 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More in Semantic Space: Intrinsic Decoupling via Clifford-M for Fundus Image Classification
Mar 21, 2026Multi-label fundus diagnosis requires features that capture both fine-grained lesions and large-scale retinal structure. Many multi-scale medical vision models address this challenge through explicit frequency decomposition, but our ablation studies show that such heuristics provide limited benefit in this setting: replacing the proposed simple dual-resolution stem with Octave Convolution increased parameters by 35% and computation by a 2.23-fold increase in computation; without improving mean accuracy, while a fixed wavelet-based variant performed substantially worse. Motivated by these findings, we propose Clifford-M, a lightweight backbone that replaces both feed-forward expansion and frequency-splitting modules with sparse geometric interaction. The model is built on a Clifford-style rolling product that jointly captures alignment and structural variation with linear complexity, enabling efficient cross-scale fusion and self-refinement in a compact dual-resolution architecture. Without pre-training, Clifford-M achieves a mean AUC-ROC of 0.8142 and a mean macro-F1 (optimal threshold) of 0.5481 on ODIR-5K using only 0.85M parameters, outperforming substantially larger mid-scale CNN baselines under the same training protocol. When evaluated on RFMiD without fine-tuning, it attains 0.7425 +/- 0.0198 macro AUC and 0.7610 +/- 0.0344 micro AUC, indicating reasonable robustness to cross-dataset shift. These results suggest that competitive and efficient fundus diagnosis can be achieved without explicit frequency engineering, provided that the core feature interaction is designed to capture multi-scale structure directly.
Communications to Circulations: 3D Wind Field Retrieval and Real-Time Prediction Using 5G GNSS Signals and Deep Learning
Sep 19, 2025



Accurate atmospheric wind field information is crucial for various applications, including weather forecasting, aviation safety, and disaster risk reduction. However, obtaining high spatiotemporal resolution wind data remains challenging due to limitations in traditional in-situ observations and remote sensing techniques, as well as the computational expense and biases of numerical weather prediction (NWP) models. This paper introduces G-WindCast, a novel deep learning framework that leverages signal strength variations from 5G Global Navigation Satellite System (GNSS) signals to retrieve and forecast three-dimensional (3D) atmospheric wind fields. The framework utilizes Forward Neural Networks (FNN) and Transformer networks to capture complex, nonlinear, and spatiotemporal relationships between GNSS-derived features and wind dynamics. Our preliminary results demonstrate promising accuracy in both wind retrieval and short-term wind forecasting (up to 30 minutes lead time), with skill scores comparable to high-resolution NWP outputs in certain scenarios. The model exhibits robustness across different forecast horizons and pressure levels, and its predictions for wind speed and direction show superior agreement with observations compared to concurrent ERA5 reanalysis data. Furthermore, we show that the system can maintain excellent performance for localized forecasting even with a significantly reduced number of GNSS stations (e.g., around 100), highlighting its cost-effectiveness and scalability. This interdisciplinary approach underscores the transformative potential of exploiting non-traditional data sources and deep learning for advanced environmental monitoring and real-time atmospheric applications.
DataLab: A Unified Platform for LLM-Powered Business Intelligence
Dec 04, 2024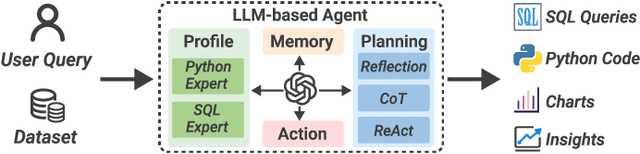
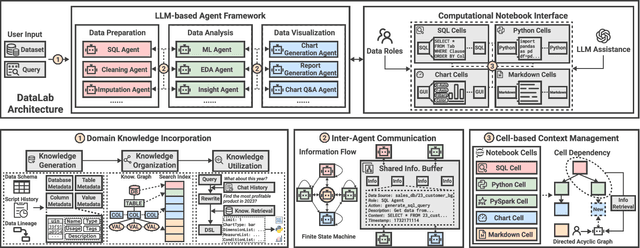
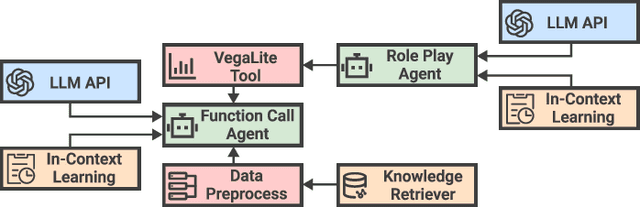
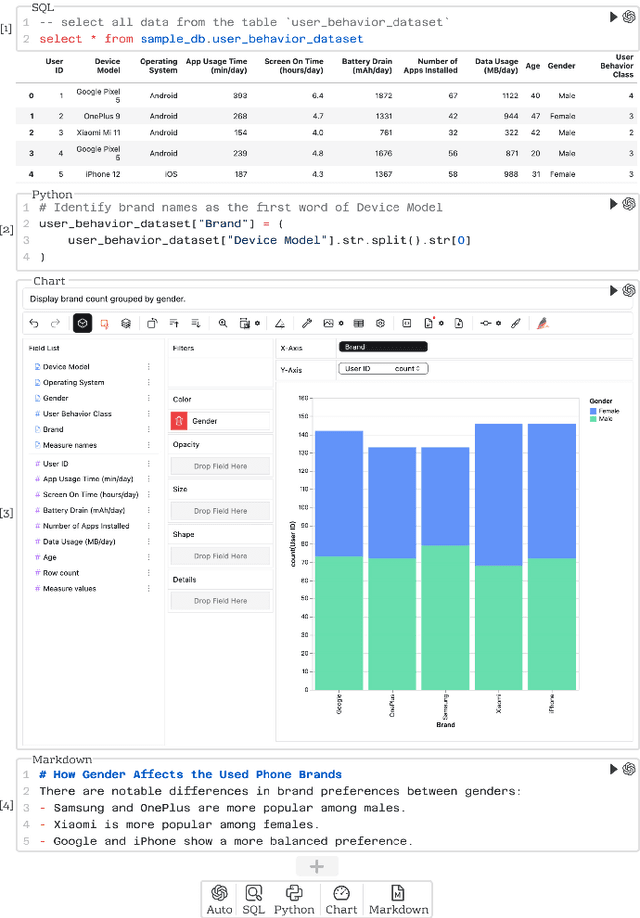
Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
DataLab: A Unifed Platform for LLM-Powered Business Intelligence
Dec 03, 2024Business intelligence (BI) transforms large volumes of data within modern organizations into actionable insights for informed decision-making. Recently, large language model (LLM)-based agents have streamlined the BI workflow by automatically performing task planning, reasoning, and actions in executable environments based on natural language (NL) queries. However, existing approaches primarily focus on individual BI tasks such as NL2SQL and NL2VIS. The fragmentation of tasks across different data roles and tools lead to inefficiencies and potential errors due to the iterative and collaborative nature of BI. In this paper, we introduce DataLab, a unified BI platform that integrates a one-stop LLM-based agent framework with an augmented computational notebook interface. DataLab supports a wide range of BI tasks for different data roles by seamlessly combining LLM assistance with user customization within a single environment. To achieve this unification, we design a domain knowledge incorporation module tailored for enterprise-specific BI tasks, an inter-agent communication mechanism to facilitate information sharing across the BI workflow, and a cell-based context management strategy to enhance context utilization efficiency in BI notebooks. Extensive experiments demonstrate that DataLab achieves state-of-the-art performance on various BI tasks across popular research benchmarks. Moreover, DataLab maintains high effectiveness and efficiency on real-world datasets from Tencent, achieving up to a 58.58% increase in accuracy and a 61.65% reduction in token cost on enterprise-specific BI tasks.
Vertical Federated Learning: Taxonomies, Threats, and Prospects
Feb 03, 2023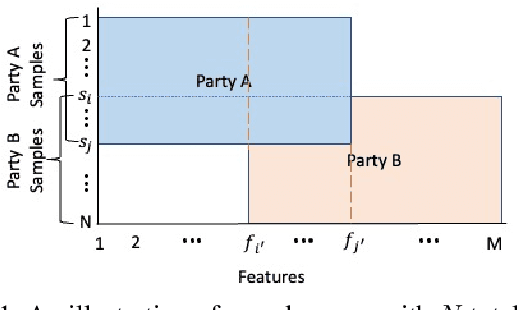
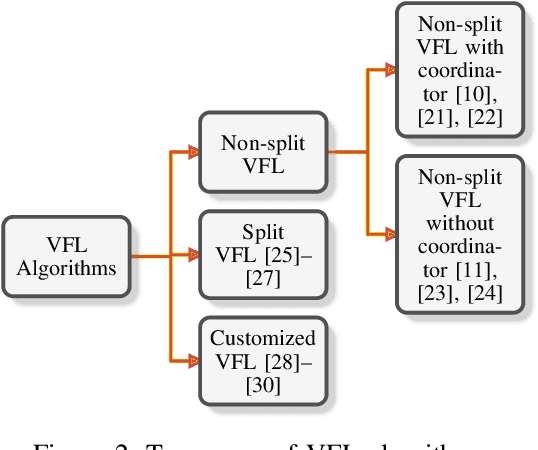
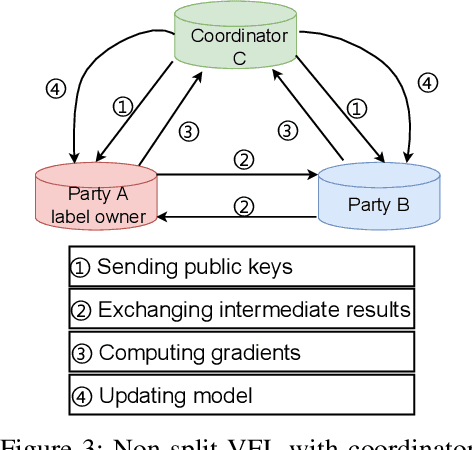

Federated learning (FL) is the most popular distributed machine learning technique. FL allows machine-learning models to be trained without acquiring raw data to a single point for processing. Instead, local models are trained with local data; the models are then shared and combined. This approach preserves data privacy as locally trained models are shared instead of the raw data themselves. Broadly, FL can be divided into horizontal federated learning (HFL) and vertical federated learning (VFL). For the former, different parties hold different samples over the same set of features; for the latter, different parties hold different feature data belonging to the same set of samples. In a number of practical scenarios, VFL is more relevant than HFL as different companies (e.g., bank and retailer) hold different features (e.g., credit history and shopping history) for the same set of customers. Although VFL is an emerging area of research, it is not well-established compared to HFL. Besides, VFL-related studies are dispersed, and their connections are not intuitive. Thus, this survey aims to bring these VFL-related studies to one place. Firstly, we classify existing VFL structures and algorithms. Secondly, we present the threats from security and privacy perspectives to VFL. Thirdly, for the benefit of future researchers, we discussed the challenges and prospects of VFL in detail.
BadHash: Invisible Backdoor Attacks against Deep Hashing with Clean Label
Jul 13, 2022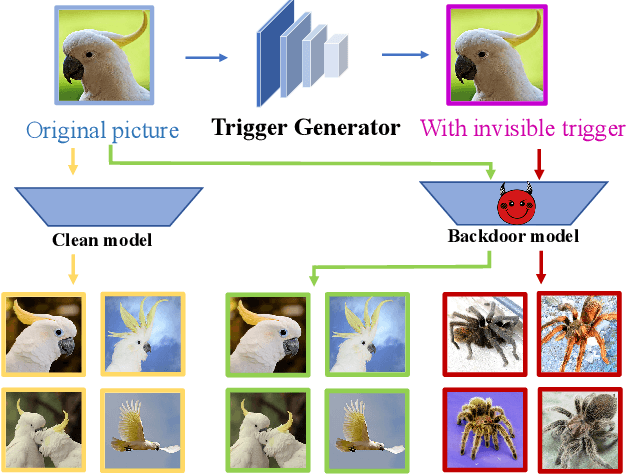
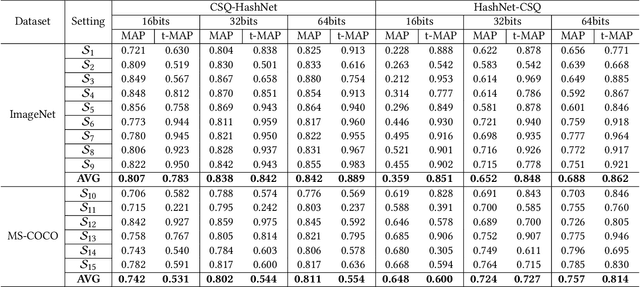
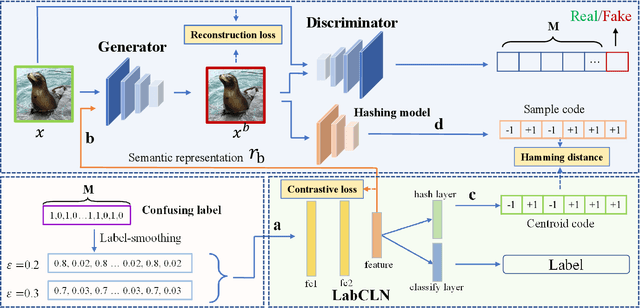
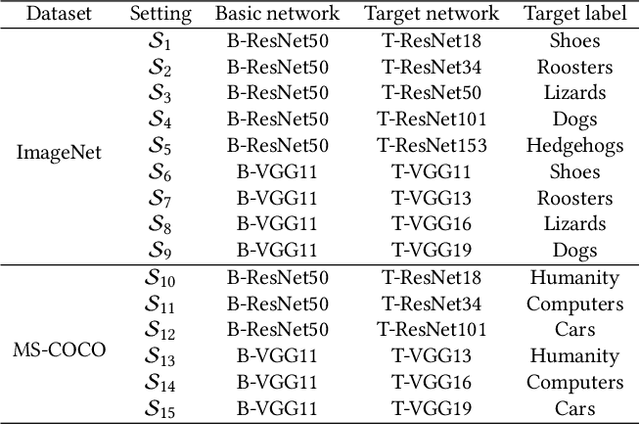
Due to its powerful feature learning capability and high efficiency, deep hashing has achieved great success in large-scale image retrieval. Meanwhile, extensive works have demonstrated that deep neural networks (DNNs) are susceptible to adversarial examples, and exploring adversarial attack against deep hashing has attracted many research efforts. Nevertheless, backdoor attack, another famous threat to DNNs, has not been studied for deep hashing yet. Although various backdoor attacks have been proposed in the field of image classification, existing approaches failed to realize a truly imperceptive backdoor attack that enjoys invisible triggers and clean label setting simultaneously, and they also cannot meet the intrinsic demand of image retrieval backdoor. In this paper, we propose BadHash, the first generative-based imperceptible backdoor attack against deep hashing, which can effectively generate invisible and input-specific poisoned images with clean label. Specifically, we first propose a new conditional generative adversarial network (cGAN) pipeline to effectively generate poisoned samples. For any given benign image, it seeks to generate a natural-looking poisoned counterpart with a unique invisible trigger. In order to improve the attack effectiveness, we introduce a label-based contrastive learning network LabCLN to exploit the semantic characteristics of different labels, which are subsequently used for confusing and misleading the target model to learn the embedded trigger. We finally explore the mechanism of backdoor attacks on image retrieval in the hash space. Extensive experiments on multiple benchmark datasets verify that BadHash can generate imperceptible poisoned samples with strong attack ability and transferability over state-of-the-art deep hashing schemes.
Privacy-Preserving Graph Neural Network Training and Inference as a Cloud Service
Feb 16, 2022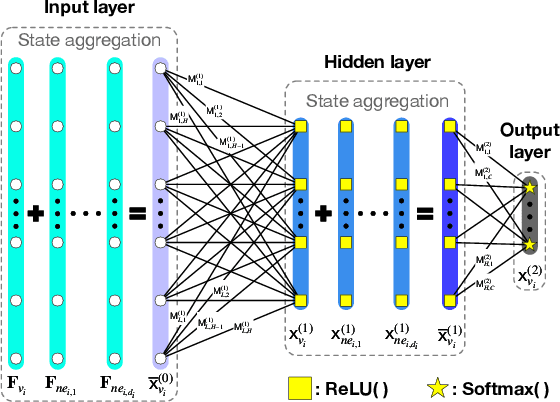
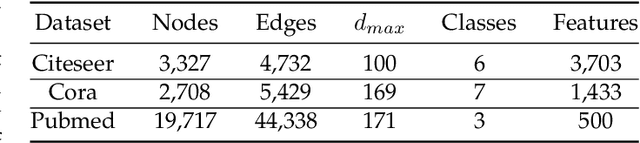
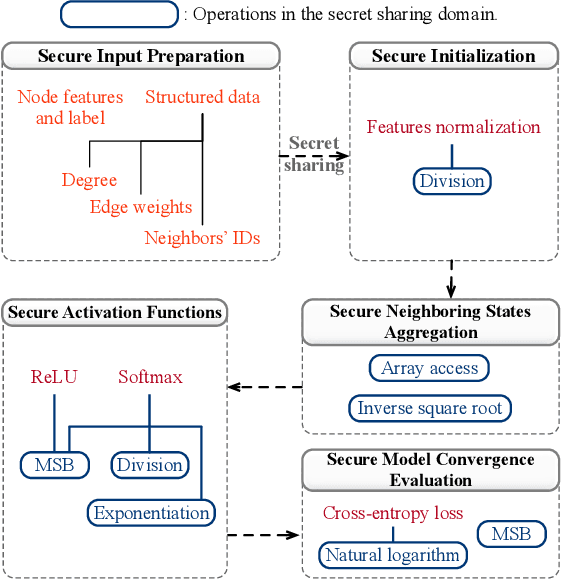

Graphs are widely used to model the complex relationships among entities. As a powerful tool for graph analytics, graph neural networks (GNNs) have recently gained wide attention due to its end-to-end processing capabilities. With the proliferation of cloud computing, it is increasingly popular to deploy the services of complex and resource-intensive model training and inference in the cloud due to its prominent benefits. However, GNN training and inference services, if deployed in the cloud, will raise critical privacy concerns about the information-rich and proprietary graph data (and the resulting model). While there has been some work on secure neural network training and inference, they all focus on convolutional neural networks handling images and text rather than complex graph data with rich structural information. In this paper, we design, implement, and evaluate SecGNN, the first system supporting privacy-preserving GNN training and inference services in the cloud. SecGNN is built from a synergy of insights on lightweight cryptography and machine learning techniques. We deeply examine the procedure of GNN training and inference, and devise a series of corresponding secure customized protocols to support the holistic computation. Extensive experiments demonstrate that SecGNN achieves comparable plaintext training and inference accuracy, with practically affordable performance.
Aggregation Service for Federated Learning: An Efficient, Secure, and More Resilient Realization
Feb 04, 2022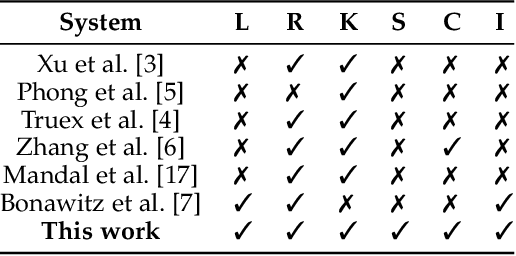
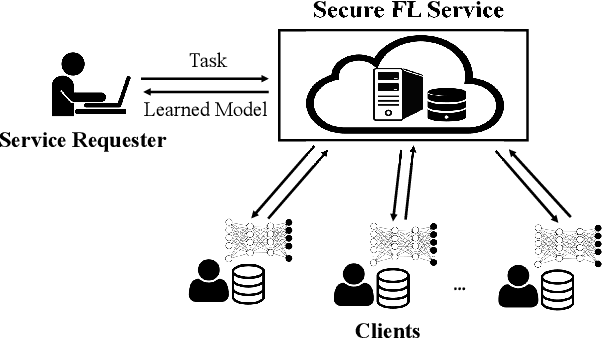

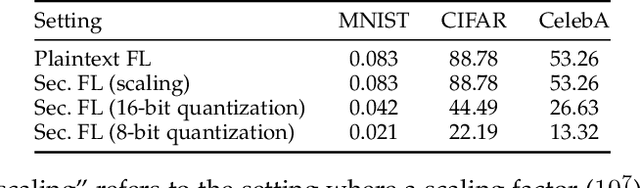
Federated learning has recently emerged as a paradigm promising the benefits of harnessing rich data from diverse sources to train high quality models, with the salient features that training datasets never leave local devices. Only model updates are locally computed and shared for aggregation to produce a global model. While federated learning greatly alleviates the privacy concerns as opposed to learning with centralized data, sharing model updates still poses privacy risks. In this paper, we present a system design which offers efficient protection of individual model updates throughout the learning procedure, allowing clients to only provide obscured model updates while a cloud server can still perform the aggregation. Our federated learning system first departs from prior works by supporting lightweight encryption and aggregation, and resilience against drop-out clients with no impact on their participation in future rounds. Meanwhile, prior work largely overlooks bandwidth efficiency optimization in the ciphertext domain and the support of security against an actively adversarial cloud server, which we also fully explore in this paper and provide effective and efficient mechanisms. Extensive experiments over several benchmark datasets (MNIST, CIFAR-10, and CelebA) show our system achieves accuracy comparable to the plaintext baseline, with practical performance.
NTD: Non-Transferability Enabled Backdoor Detection
Nov 22, 2021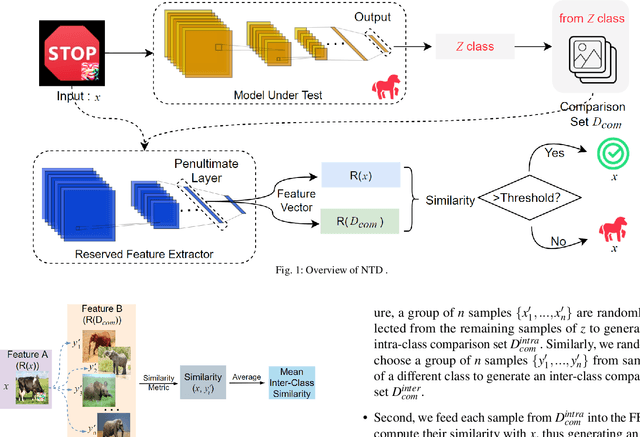

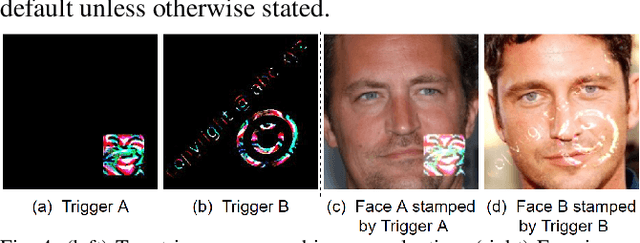
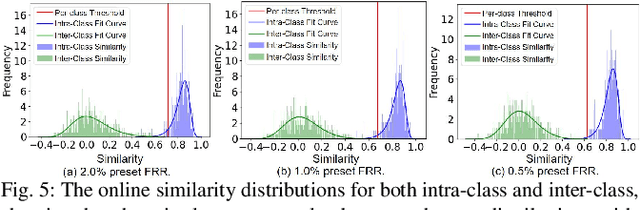
A backdoor deep learning (DL) model behaves normally upon clean inputs but misbehaves upon trigger inputs as the backdoor attacker desires, posing severe consequences to DL model deployments. State-of-the-art defenses are either limited to specific backdoor attacks (source-agnostic attacks) or non-user-friendly in that machine learning (ML) expertise or expensive computing resources are required. This work observes that all existing backdoor attacks have an inevitable intrinsic weakness, non-transferability, that is, a trigger input hijacks a backdoored model but cannot be effective to another model that has not been implanted with the same backdoor. With this key observation, we propose non-transferability enabled backdoor detection (NTD) to identify trigger inputs for a model-under-test (MUT) during run-time.Specifically, NTD allows a potentially backdoored MUT to predict a class for an input. In the meantime, NTD leverages a feature extractor (FE) to extract feature vectors for the input and a group of samples randomly picked from its predicted class, and then compares similarity between the input and the samples in the FE's latent space. If the similarity is low, the input is an adversarial trigger input; otherwise, benign. The FE is a free pre-trained model privately reserved from open platforms. As the FE and MUT are from different sources, the attacker is very unlikely to insert the same backdoor into both of them. Because of non-transferability, a trigger effect that does work on the MUT cannot be transferred to the FE, making NTD effective against different types of backdoor attacks. We evaluate NTD on three popular customized tasks such as face recognition, traffic sign recognition and general animal classification, results of which affirm that NDT has high effectiveness (low false acceptance rate) and usability (low false rejection rate) with low detection latency.
RBNN: Memory-Efficient Reconfigurable Deep Binary Neural Network with IP Protection for Internet of Things
May 11, 2021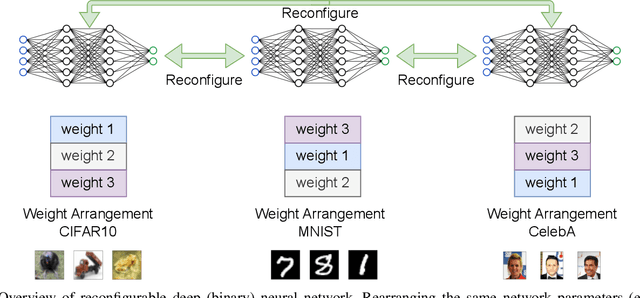
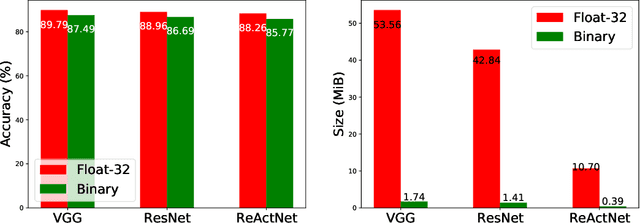
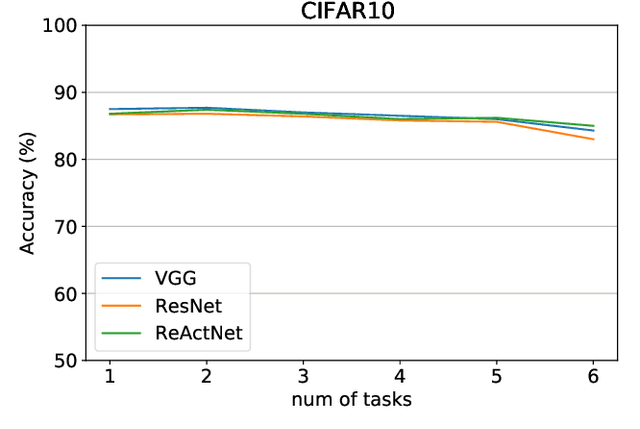
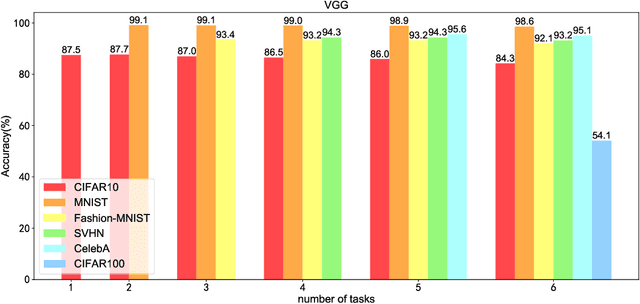
Though deep neural network models exhibit outstanding performance for various applications, their large model size and extensive floating-point operations render deployment on mobile computing platforms a major challenge, and, in particular, on Internet of Things devices. One appealing solution is model quantization that reduces the model size and uses integer operations commonly supported by microcontrollers . To this end, a 1-bit quantized DNN model or deep binary neural network maximizes the memory efficiency, where each parameter in a BNN model has only 1-bit. In this paper, we propose a reconfigurable BNN (RBNN) to further amplify the memory efficiency for resource-constrained IoT devices. Generally, the RBNN can be reconfigured on demand to achieve any one of M (M>1) distinct tasks with the same parameter set, thus only a single task determines the memory requirements. In other words, the memory utilization is improved by times M. Our extensive experiments corroborate that up to seven commonly used tasks can co-exist (the value of M can be larger). These tasks with a varying number of classes have no or negligible accuracy drop-off on three binarized popular DNN architectures including VGG, ResNet, and ReActNet. The tasks span across different domains, e.g., computer vision and audio domains validated herein, with the prerequisite that the model architecture can serve those cross-domain tasks. To protect the intellectual property of an RBNN model, the reconfiguration can be controlled by both a user key and a device-unique root key generated by the intrinsic hardware fingerprint. By doing so, an RBNN model can only be used per paid user per authorized device, thus benefiting both the user and the model provider.