 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiTIMO: An LLM-empowered Synthesis Dataset for Travel Itinerary Modification
Jan 15, 2026Addressing itinerary modification is crucial for enhancing the travel experience as it is a frequent requirement during traveling. However, existing research mainly focuses on fixed itinerary planning, leaving modification underexplored. To bridge this gap, we formally define the itinerary modification task and introduce iTIMO, a dataset specifically tailored for this purpose. We identify the lack of {\itshape need-to-modify} itinerary data as the critical bottleneck hindering research on this task and propose a general pipeline to overcome it. This pipeline frames the generation of such data as an intent-driven perturbation task. It instructs large language models to perturb real world itineraries using three atomic editing operations: REPLACE, ADD, and DELETE. Each perturbation is grounded in three intents, including disruptions of popularity, spatial distance, and category diversity. Furthermore, a hybrid evaluation metric is designed to ensure perturbation effectiveness. We conduct comprehensive experiments on iTIMO, revealing the limitations of current LLMs and lead to several valuable directions for future research. Dataset and corresponding code are available at https://github.com/zelo2/iTIMO.
Keep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
From Pixels to Trajectory: Universal Adversarial Example Detection via Temporal Imprints
Mar 06, 2025For the first time, we unveil discernible temporal (or historical) trajectory imprints resulting from adversarial example (AE) attacks. Standing in contrast to existing studies all focusing on spatial (or static) imprints within the targeted underlying victim models, we present a fresh temporal paradigm for understanding these attacks. Of paramount discovery is that these imprints are encapsulated within a single loss metric, spanning universally across diverse tasks such as classification and regression, and modalities including image, text, and audio. Recognizing the distinct nature of loss between adversarial and clean examples, we exploit this temporal imprint for AE detection by proposing TRAIT (TRaceable Adversarial temporal trajectory ImprinTs). TRAIT operates under minimal assumptions without prior knowledge of attacks, thereby framing the detection challenge as a one-class classification problem. However, detecting AEs is still challenged by significant overlaps between the constructed synthetic losses of adversarial and clean examples due to the absence of ground truth for incoming inputs. TRAIT addresses this challenge by converting the synthetic loss into a spectrum signature, using the technique of Fast Fourier Transform to highlight the discrepancies, drawing inspiration from the temporal nature of the imprints, analogous to time-series signals. Across 12 AE attacks including SMACK (USENIX Sec'2023), TRAIT demonstrates consistent outstanding performance across comprehensively evaluated modalities, tasks, datasets, and model architectures. In all scenarios, TRAIT achieves an AE detection accuracy exceeding 97%, often around 99%, while maintaining a false rejection rate of 1%. TRAIT remains effective under the formulated strong adaptive attacks.
qMRI Diffusor: Quantitative T1 Mapping of the Brain using a Denoising Diffusion Probabilistic Model
Jul 23, 2024Quantitative MRI (qMRI) offers significant advantages over weighted images by providing objective parameters related to tissue properties. Deep learning-based methods have demonstrated effectiveness in estimating quantitative maps from series of weighted images. In this study, we present qMRI Diffusor, a novel approach to qMRI utilising deep generative models. Specifically, we implemented denoising diffusion probabilistic models (DDPM) for T1 quantification in the brain, framing the estimation of quantitative maps as a conditional generation task. The proposed method is compared with the residual neural network (ResNet) and the recurrent inference machine (RIM) on both phantom and in vivo data. The results indicate that our method achieves improved accuracy and precision in parameter estimation, along with superior visual performance. Moreover, our method inherently incorporates stochasticity, enabling straightforward quantification of uncertainty. Hence, the proposed method holds significant promise for quantitative MR mapping.
Horizontal Class Backdoor to Deep Learning
Oct 01, 2023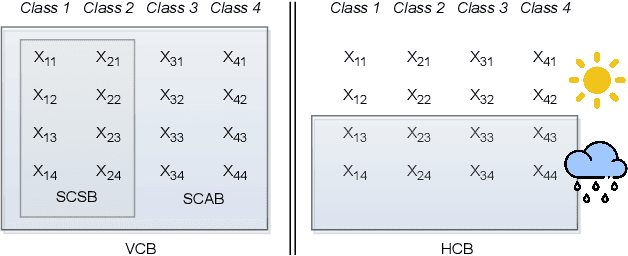


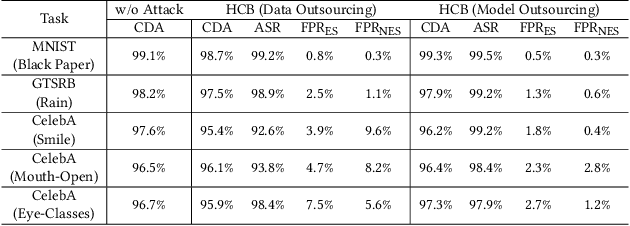
All existing backdoor attacks to deep learning (DL) models belong to the vertical class backdoor (VCB). That is, any sample from a class will activate the implanted backdoor in the presence of the secret trigger, regardless of source-class-agnostic or source-class-specific backdoor. Current trends of existing defenses are overwhelmingly devised for VCB attacks especially the source-class-agnostic backdoor, which essentially neglects other potential simple but general backdoor types, thus giving false security implications. It is thus urgent to discover unknown backdoor types. This work reveals a new, simple, and general horizontal class backdoor (HCB) attack. We show that the backdoor can be naturally bounded with innocuous natural features that are common and pervasive in the real world. Note that an innocuous feature (e.g., expression) is irrelevant to the main task of the model (e.g., recognizing a person from one to another). The innocuous feature spans across classes horizontally but is exhibited by partial samples per class -- satisfying the horizontal class (HC) property. Only when the trigger is concurrently presented with the HC innocuous feature, can the backdoor be effectively activated. Extensive experiments on attacking performance in terms of high attack success rates with tasks of 1) MNIST, 2) facial recognition, 3) traffic sign recognition, and 4) object detection demonstrate that the HCB is highly efficient and effective. We extensively evaluate the HCB evasiveness against a (chronologically) series of 9 influential countermeasures of Fine-Pruning (RAID 18'), STRIP (ACSAC 19'), Neural Cleanse (Oakland 19'), ABS (CCS 19'), Februus (ACSAC 20'), MNTD (Oakland 21'), SCAn (USENIX SEC 21'), MOTH (Oakland 22'), and Beatrix (NDSS 23'), where none of them can succeed even when a simplest trigger is used.
CIT-EmotionNet: CNN Interactive Transformer Network for EEG Emotion Recognition
May 07, 2023Emotion recognition using Electroencephalogram (EEG) signals has emerged as a significant research challenge in affective computing and intelligent interaction. However, effectively combining global and local features of EEG signals to improve performance in emotion recognition is still a difficult task. In this study, we propose a novel CNN Interactive Transformer Network for EEG Emotion Recognition, known as CIT-EmotionNet, which efficiently integrates global and local features of EEG signals. Initially, we convert raw EEG signals into spatial-frequency representations, which serve as inputs. Then, we integrate Convolutional Neural Network (CNN) and Transformer within a single framework in a parallel manner. Finally, we design a CNN interactive Transformer module, which facilitates the interaction and fusion of local and global features, thereby enhancing the model's ability to extract both types of features from EEG spatial-frequency representations. The proposed CIT-EmotionNet outperforms state-of-the-art methods, achieving an average recognition accuracy of 98.57\% and 92.09\% on two publicly available datasets, SEED and SEED-IV, respectively.
Vertical Federated Learning: Taxonomies, Threats, and Prospects
Feb 03, 2023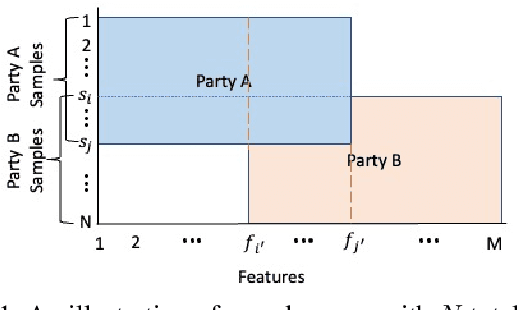
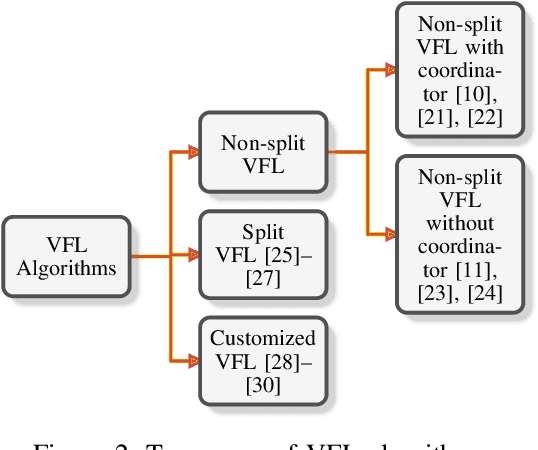
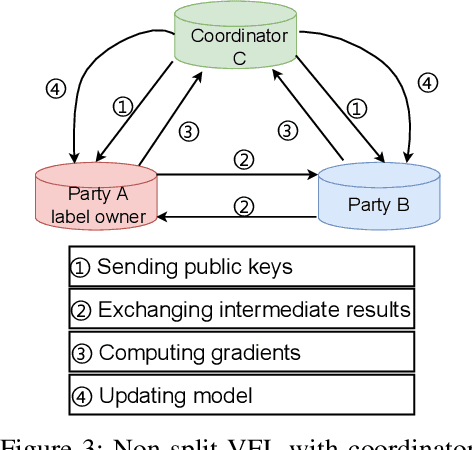

Federated learning (FL) is the most popular distributed machine learning technique. FL allows machine-learning models to be trained without acquiring raw data to a single point for processing. Instead, local models are trained with local data; the models are then shared and combined. This approach preserves data privacy as locally trained models are shared instead of the raw data themselves. Broadly, FL can be divided into horizontal federated learning (HFL) and vertical federated learning (VFL). For the former, different parties hold different samples over the same set of features; for the latter, different parties hold different feature data belonging to the same set of samples. In a number of practical scenarios, VFL is more relevant than HFL as different companies (e.g., bank and retailer) hold different features (e.g., credit history and shopping history) for the same set of customers. Although VFL is an emerging area of research, it is not well-established compared to HFL. Besides, VFL-related studies are dispersed, and their connections are not intuitive. Thus, this survey aims to bring these VFL-related studies to one place. Firstly, we classify existing VFL structures and algorithms. Secondly, we present the threats from security and privacy perspectives to VFL. Thirdly, for the benefit of future researchers, we discussed the challenges and prospects of VFL in detail.
MACAB: Model-Agnostic Clean-Annotation Backdoor to Object Detection with Natural Trigger in Real-World
Sep 06, 2022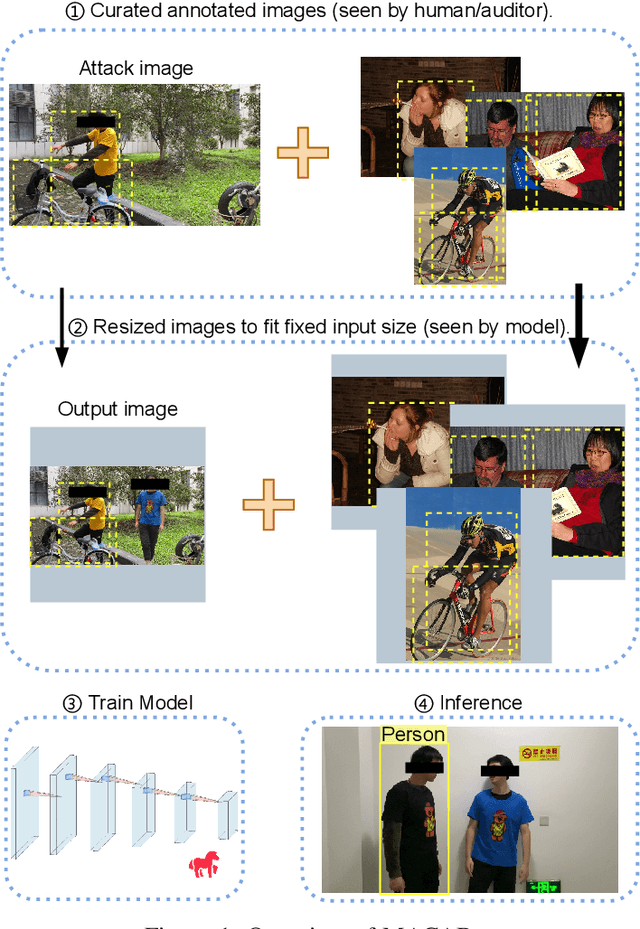
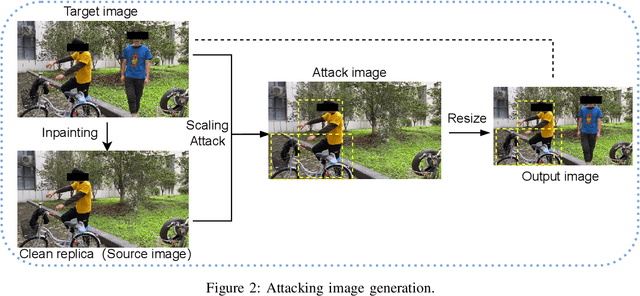


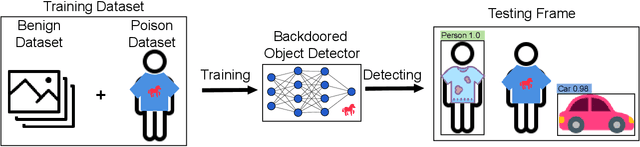
Object detection is the foundation of various critical computer-vision tasks such as segmentation, object tracking, and event detection. To train an object detector with satisfactory accuracy, a large amount of data is required. However, due to the intensive workforce involved with annotating large datasets, such a data curation task is often outsourced to a third party or relied on volunteers. This work reveals severe vulnerabilities of such data curation pipeline. We propose MACAB that crafts clean-annotated images to stealthily implant the backdoor into the object detectors trained on them even when the data curator can manually audit the images. We observe that the backdoor effect of both misclassification and the cloaking are robustly achieved in the wild when the backdoor is activated with inconspicuously natural physical triggers. Backdooring non-classification object detection with clean-annotation is challenging compared to backdooring existing image classification tasks with clean-label, owing to the complexity of having multiple objects within each frame, including victim and non-victim objects. The efficacy of the MACAB is ensured by constructively i abusing the image-scaling function used by the deep learning framework, ii incorporating the proposed adversarial clean image replica technique, and iii combining poison data selection criteria given constrained attacking budget. Extensive experiments demonstrate that MACAB exhibits more than 90% attack success rate under various real-world scenes. This includes both cloaking and misclassification backdoor effect even restricted with a small attack budget. The poisoned samples cannot be effectively identified by state-of-the-art detection techniques.The comprehensive video demo is at https://youtu.be/MA7L_LpXkp4, which is based on a poison rate of 0.14% for YOLOv4 cloaking backdoor and Faster R-CNN misclassification backdoor.
Towards A Critical Evaluation of Robustness for Deep Learning Backdoor Countermeasures
Apr 13, 2022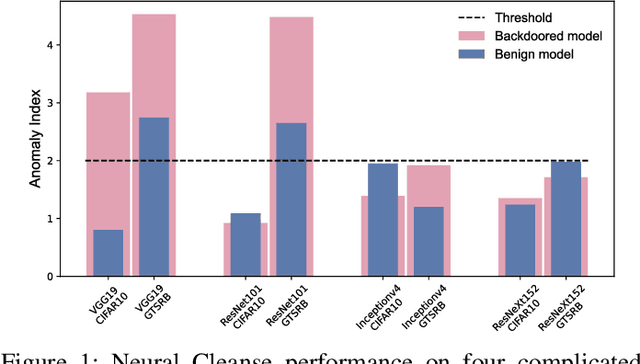
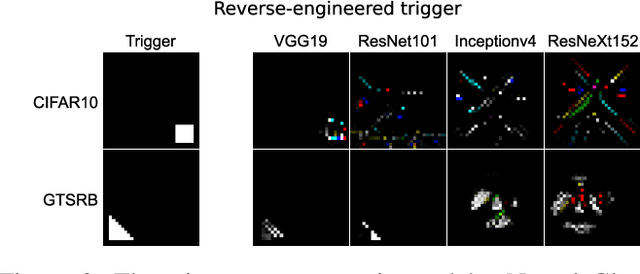
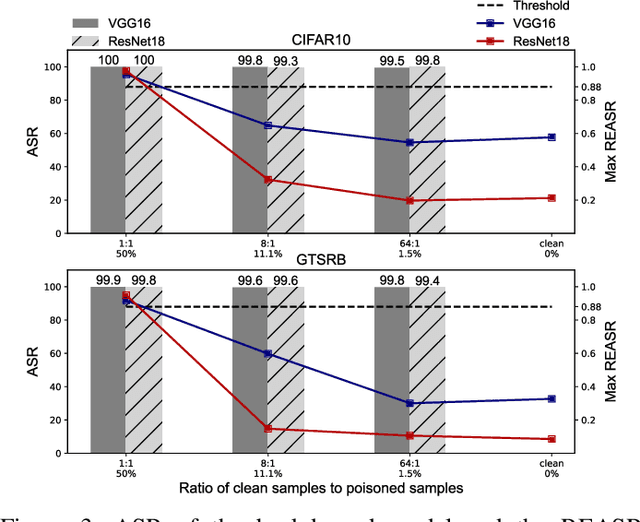

Since Deep Learning (DL) backdoor attacks have been revealed as one of the most insidious adversarial attacks, a number of countermeasures have been developed with certain assumptions defined in their respective threat models. However, the robustness of these countermeasures is inadvertently ignored, which can introduce severe consequences, e.g., a countermeasure can be misused and result in a false implication of backdoor detection. For the first time, we critically examine the robustness of existing backdoor countermeasures with an initial focus on three influential model-inspection ones that are Neural Cleanse (S&P'19), ABS (CCS'19), and MNTD (S&P'21). Although the three countermeasures claim that they work well under their respective threat models, they have inherent unexplored non-robust cases depending on factors such as given tasks, model architectures, datasets, and defense hyper-parameter, which are \textit{not even rooted from delicate adaptive attacks}. We demonstrate how to trivially bypass them aligned with their respective threat models by simply varying aforementioned factors. Particularly, for each defense, formal proofs or empirical studies are used to reveal its two non-robust cases where it is not as robust as it claims or expects, especially the recent MNTD. This work highlights the necessity of thoroughly evaluating the robustness of backdoor countermeasures to avoid their misleading security implications in unknown non-robust cases.
Dangerous Cloaking: Natural Trigger based Backdoor Attacks on Object Detectors in the Physical World
Jan 21, 2022
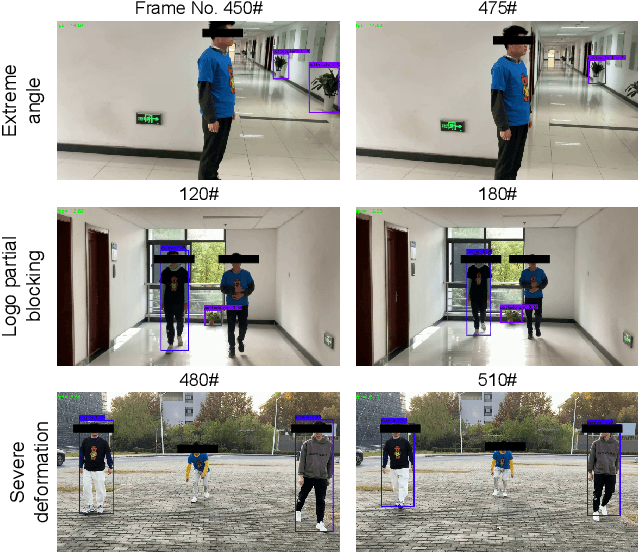

Deep learning models have been shown to be vulnerable to recent backdoor attacks. A backdoored model behaves normally for inputs containing no attacker-secretly-chosen trigger and maliciously for inputs with the trigger. To date, backdoor attacks and countermeasures mainly focus on image classification tasks. And most of them are implemented in the digital world with digital triggers. Besides the classification tasks, object detection systems are also considered as one of the basic foundations of computer vision tasks. However, there is no investigation and understanding of the backdoor vulnerability of the object detector, even in the digital world with digital triggers. For the first time, this work demonstrates that existing object detectors are inherently susceptible to physical backdoor attacks. We use a natural T-shirt bought from a market as a trigger to enable the cloaking effect--the person bounding-box disappears in front of the object detector. We show that such a backdoor can be implanted from two exploitable attack scenarios into the object detector, which is outsourced or fine-tuned through a pretrained model. We have extensively evaluated three popular object detection algorithms: anchor-based Yolo-V3, Yolo-V4, and anchor-free CenterNet. Building upon 19 videos shot in real-world scenes, we confirm that the backdoor attack is robust against various factors: movement, distance, angle, non-rigid deformation, and lighting. Specifically, the attack success rate (ASR) in most videos is 100% or close to it, while the clean data accuracy of the backdoored model is the same as its clean counterpart. The latter implies that it is infeasible to detect the backdoor behavior merely through a validation set. The averaged ASR still remains sufficiently high to be 78% in the transfer learning attack scenarios evaluated on CenterNet. See the demo video on https://youtu.be/Q3HOF4OobbY.