 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorizontal Class Backdoor to Deep Learning
Paper and Code
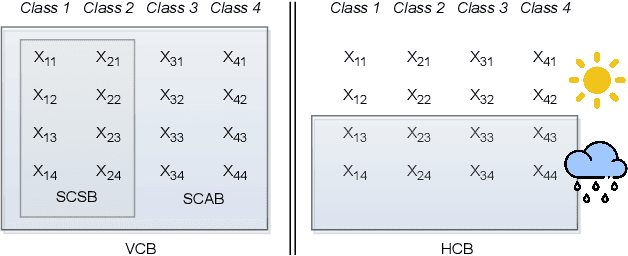


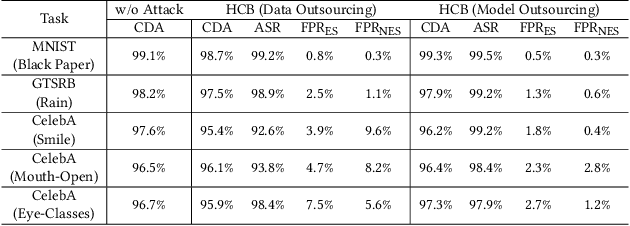
All existing backdoor attacks to deep learning (DL) models belong to the vertical class backdoor (VCB). That is, any sample from a class will activate the implanted backdoor in the presence of the secret trigger, regardless of source-class-agnostic or source-class-specific backdoor. Current trends of existing defenses are overwhelmingly devised for VCB attacks especially the source-class-agnostic backdoor, which essentially neglects other potential simple but general backdoor types, thus giving false security implications. It is thus urgent to discover unknown backdoor types. This work reveals a new, simple, and general horizontal class backdoor (HCB) attack. We show that the backdoor can be naturally bounded with innocuous natural features that are common and pervasive in the real world. Note that an innocuous feature (e.g., expression) is irrelevant to the main task of the model (e.g., recognizing a person from one to another). The innocuous feature spans across classes horizontally but is exhibited by partial samples per class -- satisfying the horizontal class (HC) property. Only when the trigger is concurrently presented with the HC innocuous feature, can the backdoor be effectively activated. Extensive experiments on attacking performance in terms of high attack success rates with tasks of 1) MNIST, 2) facial recognition, 3) traffic sign recognition, and 4) object detection demonstrate that the HCB is highly efficient and effective. We extensively evaluate the HCB evasiveness against a (chronologically) series of 9 influential countermeasures of Fine-Pruning (RAID 18'), STRIP (ACSAC 19'), Neural Cleanse (Oakland 19'), ABS (CCS 19'), Februus (ACSAC 20'), MNTD (Oakland 21'), SCAn (USENIX SEC 21'), MOTH (Oakland 22'), and Beatrix (NDSS 23'), where none of them can succeed even when a simplest trigger is used.