 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription-Code Inconsistency in Real-world MCP Servers: Measurement, Detection, and Security Implications
Jun 03, 2026The Model Context Protocol (MCP) has emerged as a critical standard empowering Large Language Models (LLMs) to utilize external tools. In this ecosystem, LLMs rely on natural language descriptions provided by MCP servers to select and execute functions. This interaction implicitly assumes that tool descriptions faithfully reflect their underlying implementations, while this assumption is not mandatorily verified in practice. As a result, MCP deployments may suffer from a problem named Description-Code Inconsistency (DCI), where a tool's description of its capabilities and security boundaries is not consistent with what the code actually does. In this paper, we present a comprehensive study of DCI in real-world MCP servers. We formally define the problem and propose a comprehensive taxonomy spanning functionality inconsistencies and undeclared side effects. Guided by this taxonomy, we develop DCIChecker, an automated framework that combines structure-aware static analysis with the Direct-Reverse-Arbitration prompting method to cross-validate tool descriptions against actual code implementations. We apply this framework to a large-scale dataset comprising 19,200 description-code pairs extracted from 2,214 real-world MCP servers. Our measurement reveals that DCI is widespread, with 9.93% of these pairs exhibiting inconsistencies. We further demonstrate that DCI creates a critical defense blind spot, facilitating varied risks from operational failures to stealthy malicious behaviors. Finally, we propose mitigation strategies to enforce semantic consistency and enhance the reliability of the emerging agentic ecosystem.
Safe Text-to-Image Generation: Simply Sanitize the Prompt Embedding
Nov 15, 2024



In recent years, text-to-image (T2I) generation models have made significant progress in generating high-quality images that align with text descriptions. However, these models also face the risk of unsafe generation, potentially producing harmful content that violates usage policies, such as explicit material. Existing safe generation methods typically focus on suppressing inappropriate content by erasing undesired concepts from visual representations, while neglecting to sanitize the textual representation. Although these methods help mitigate the risk of misuse to certain extent, their robustness remains insufficient when dealing with adversarial attacks. Given that semantic consistency between input text and output image is a fundamental requirement for T2I models, we identify that textual representations (i.e., prompt embeddings) are likely the primary source of unsafe generation. To this end, we propose a vision-agnostic safe generation framework, Embedding Sanitizer (ES), which focuses on erasing inappropriate concepts from prompt embeddings and uses the sanitized embeddings to guide the model for safe generation. ES is applied to the output of the text encoder as a plug-and-play module, enabling seamless integration with different T2I models as well as other safeguards. In addition, ES's unique scoring mechanism assigns a score to each token in the prompt to indicate its potential harmfulness, and dynamically adjusts the sanitization intensity to balance defensive performance and generation quality. Through extensive evaluation on five prompt benchmarks, our approach achieves state-of-the-art robustness by sanitizing the source (prompt embedding) of unsafe generation compared to nine baseline methods. It significantly outperforms existing safeguards in terms of interpretability and controllability while maintaining generation quality.
BELT: Old-School Backdoor Attacks can Evade the State-of-the-Art Defense with Backdoor Exclusivity Lifting
Dec 08, 2023



Deep neural networks (DNNs) are susceptible to backdoor attacks, where malicious functionality is embedded to allow attackers to trigger incorrect classifications. Old-school backdoor attacks use strong trigger features that can easily be learned by victim models. Despite robustness against input variation, the robustness however increases the likelihood of unintentional trigger activations. This leaves traces to existing defenses, which find approximate replacements for the original triggers that can activate the backdoor without being identical to the original trigger via, e.g., reverse engineering and sample overlay. In this paper, we propose and investigate a new characteristic of backdoor attacks, namely, backdoor exclusivity, which measures the ability of backdoor triggers to remain effective in the presence of input variation. Building upon the concept of backdoor exclusivity, we propose Backdoor Exclusivity LifTing (BELT), a novel technique which suppresses the association between the backdoor and fuzzy triggers to enhance backdoor exclusivity for defense evasion. Extensive evaluation on three popular backdoor benchmarks validate, our approach substantially enhances the stealthiness of four old-school backdoor attacks, which, after backdoor exclusivity lifting, is able to evade six state-of-the-art backdoor countermeasures, at almost no cost of the attack success rate and normal utility. For example, one of the earliest backdoor attacks BadNet, enhanced by BELT, evades most of the state-of-the-art defenses including ABS and MOTH which would otherwise recognize the backdoored model.
Weighted Contrastive Hashing
Sep 28, 2022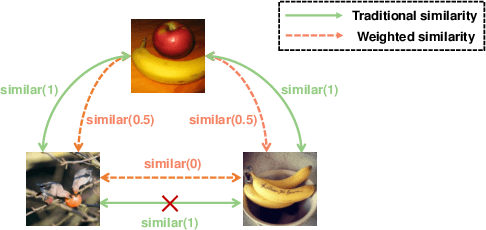
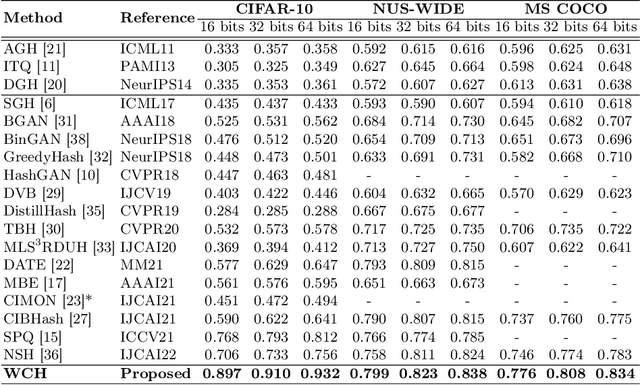
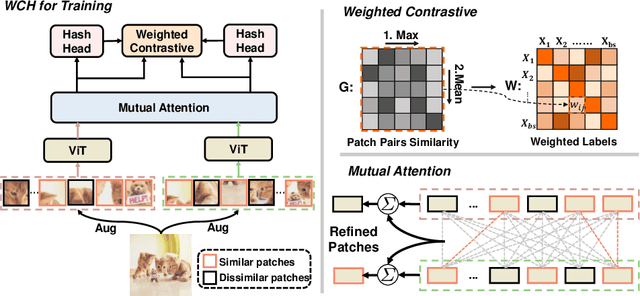
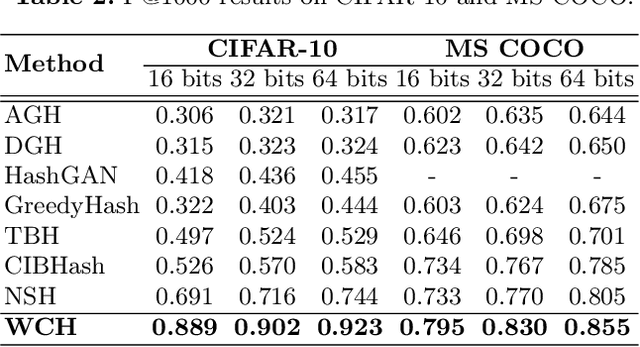
The development of unsupervised hashing is advanced by the recent popular contrastive learning paradigm. However, previous contrastive learning-based works have been hampered by (1) insufficient data similarity mining based on global-only image representations, and (2) the hash code semantic loss caused by the data augmentation. In this paper, we propose a novel method, namely Weighted Contrative Hashing (WCH), to take a step towards solving these two problems. We introduce a novel mutual attention module to alleviate the problem of information asymmetry in network features caused by the missing image structure during contrative augmentation. Furthermore, we explore the fine-grained semantic relations between images, i.e., we divide the images into multiple patches and calculate similarities between patches. The aggregated weighted similarities, which reflect the deep image relations, are distilled to facilitate the hash codes learning with a distillation loss, so as to obtain better retrieval performance. Extensive experiments show that the proposed WCH significantly outperforms existing unsupervised hashing methods on three benchmark datasets.
Towards A Critical Evaluation of Robustness for Deep Learning Backdoor Countermeasures
Apr 13, 2022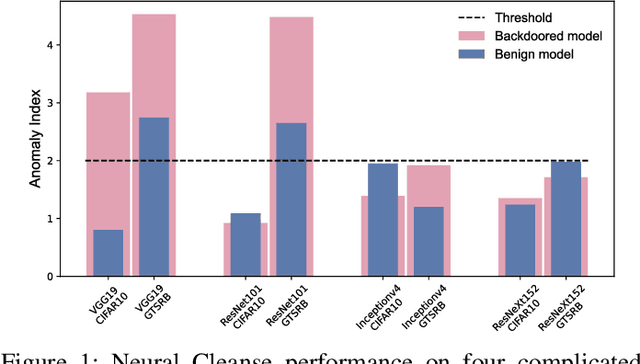
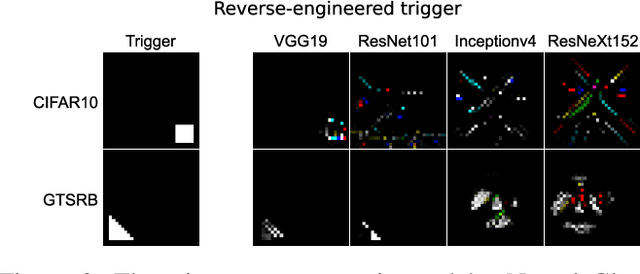

Since Deep Learning (DL) backdoor attacks have been revealed as one of the most insidious adversarial attacks, a number of countermeasures have been developed with certain assumptions defined in their respective threat models. However, the robustness of these countermeasures is inadvertently ignored, which can introduce severe consequences, e.g., a countermeasure can be misused and result in a false implication of backdoor detection. For the first time, we critically examine the robustness of existing backdoor countermeasures with an initial focus on three influential model-inspection ones that are Neural Cleanse (S&P'19), ABS (CCS'19), and MNTD (S&P'21). Although the three countermeasures claim that they work well under their respective threat models, they have inherent unexplored non-robust cases depending on factors such as given tasks, model architectures, datasets, and defense hyper-parameter, which are \textit{not even rooted from delicate adaptive attacks}. We demonstrate how to trivially bypass them aligned with their respective threat models by simply varying aforementioned factors. Particularly, for each defense, formal proofs or empirical studies are used to reveal its two non-robust cases where it is not as robust as it claims or expects, especially the recent MNTD. This work highlights the necessity of thoroughly evaluating the robustness of backdoor countermeasures to avoid their misleading security implications in unknown non-robust cases.
Quantization Backdoors to Deep Learning Models
Aug 20, 2021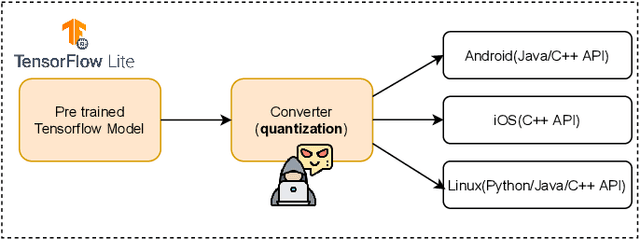
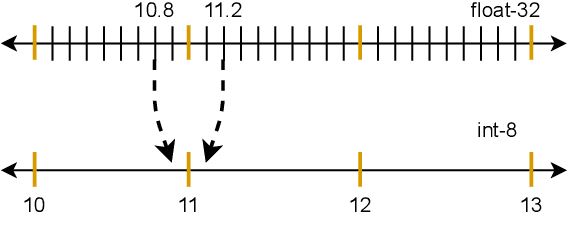
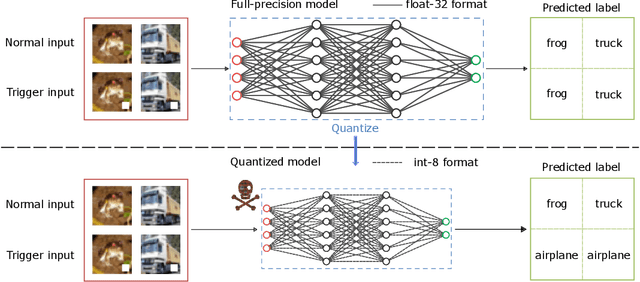
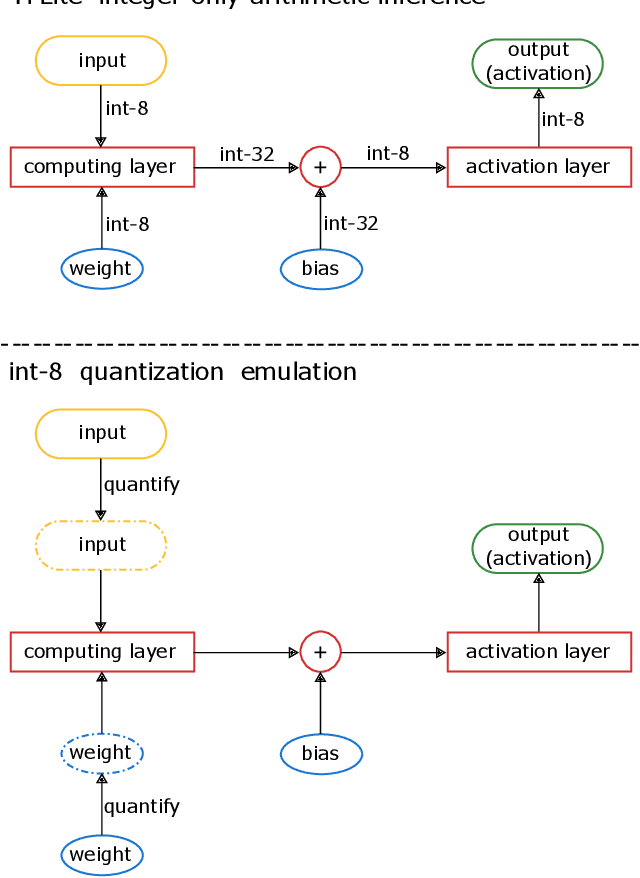
There is currently a burgeoning demand for deploying deep learning (DL) models on ubiquitous edge Internet of Things devices attributing to their low latency and high privacy preservation. However, DL models are often large in size and require large-scale computation, which prevents them from being placed directly onto IoT devices where resources are constrained and 32-bit floating-point operations are unavailable. Model quantization is a pragmatic solution, which enables DL deployment on mobile devices and embedded systems by effortlessly post-quantizing a large high-precision model into a small low-precision model while retaining the model inference accuracy. This work reveals that the standard quantization operation can be abused to activate a backdoor. We demonstrate that a full-precision backdoored model that does not have any backdoor effect in the presence of a trigger -- as the backdoor is dormant -- can be activated by the default TensorFlow-Lite quantization, the only product-ready quantization framework to date. We ascertain that all trained float-32 backdoored models exhibit no backdoor effect even in the presence of trigger inputs. State-of-the-art frontend detection approaches, such as Neural Cleanse and STRIP, fail to identify the backdoor in the float-32 models. When each of the float-32 models is converted into an int-8 format model through the standard TFLite post-training quantization, the backdoor is activated in the quantized model, which shows a stable attack success rate close to 100% upon inputs with the trigger, while behaves normally upon non-trigger inputs. This work highlights that a stealthy security threat occurs when end users utilize the on-device post-training model quantization toolkits, informing security researchers of cross-platform overhaul of DL models post quantization even if they pass frontend inspections.
RBNN: Memory-Efficient Reconfigurable Deep Binary Neural Network with IP Protection for Internet of Things
May 11, 2021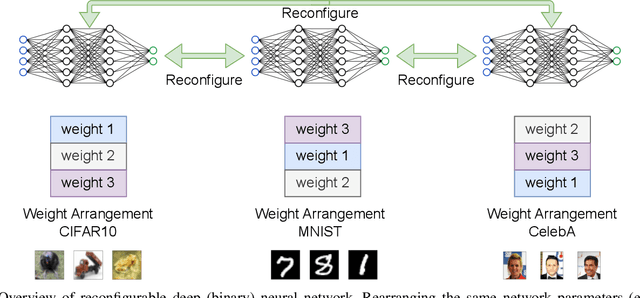
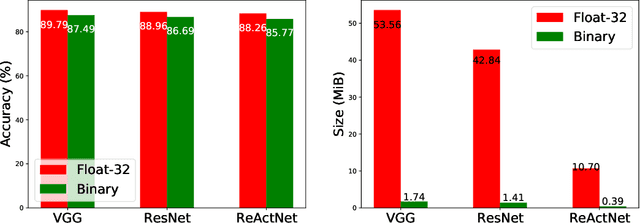
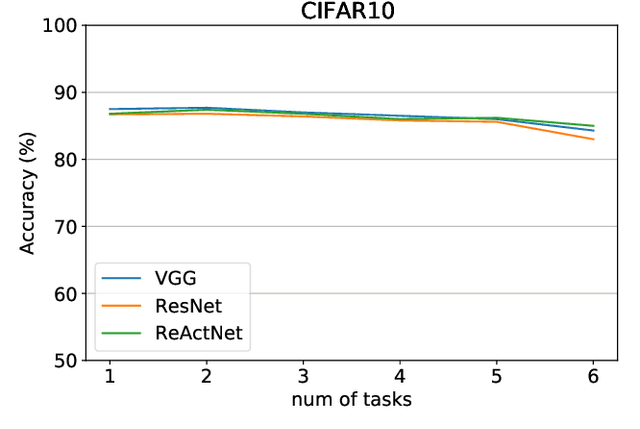
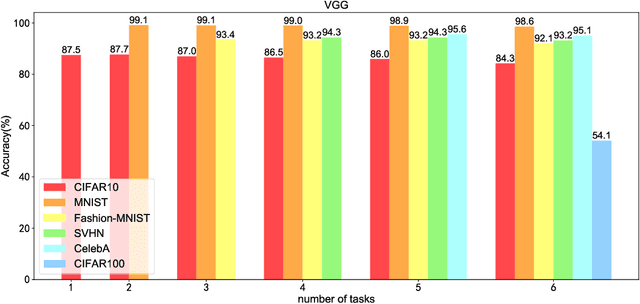
Though deep neural network models exhibit outstanding performance for various applications, their large model size and extensive floating-point operations render deployment on mobile computing platforms a major challenge, and, in particular, on Internet of Things devices. One appealing solution is model quantization that reduces the model size and uses integer operations commonly supported by microcontrollers . To this end, a 1-bit quantized DNN model or deep binary neural network maximizes the memory efficiency, where each parameter in a BNN model has only 1-bit. In this paper, we propose a reconfigurable BNN (RBNN) to further amplify the memory efficiency for resource-constrained IoT devices. Generally, the RBNN can be reconfigured on demand to achieve any one of M (M>1) distinct tasks with the same parameter set, thus only a single task determines the memory requirements. In other words, the memory utilization is improved by times M. Our extensive experiments corroborate that up to seven commonly used tasks can co-exist (the value of M can be larger). These tasks with a varying number of classes have no or negligible accuracy drop-off on three binarized popular DNN architectures including VGG, ResNet, and ReActNet. The tasks span across different domains, e.g., computer vision and audio domains validated herein, with the prerequisite that the model architecture can serve those cross-domain tasks. To protect the intellectual property of an RBNN model, the reconfiguration can be controlled by both a user key and a device-unique root key generated by the intrinsic hardware fingerprint. By doing so, an RBNN model can only be used per paid user per authorized device, thus benefiting both the user and the model provider.