 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifiable Black-Box Attack: Ensuring Provably Successful Attack for Adversarial Examples
Paper and Code
Apr 10, 2023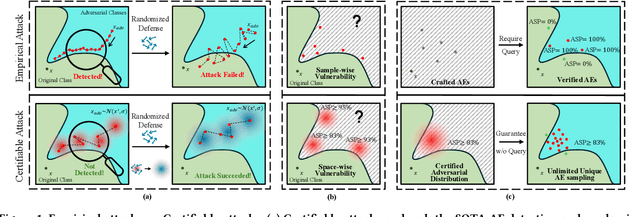

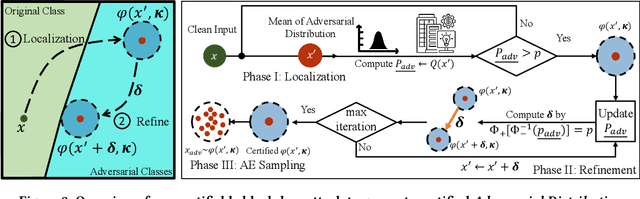
Black-box adversarial attacks have shown strong potential to subvert machine learning models. Existing black-box adversarial attacks craft the adversarial examples by iteratively querying the target model and/or leveraging the transferability of a local surrogate model. Whether such attack can succeed remains unknown to the adversary when empirically designing the attack. In this paper, to our best knowledge, we take the first step to study a new paradigm of adversarial attacks -- certifiable black-box attack that can guarantee the attack success rate of the crafted adversarial examples. Specifically, we revise the randomized smoothing to establish novel theories for ensuring the attack success rate of the adversarial examples. To craft the adversarial examples with the certifiable attack success rate (CASR) guarantee, we design several novel techniques, including a randomized query method to query the target model, an initialization method with smoothed self-supervised perturbation to derive certifiable adversarial examples, and a geometric shifting method to reduce the perturbation size of the certifiable adversarial examples for better imperceptibility. We have comprehensively evaluated the performance of the certifiable black-box attack on CIFAR10 and ImageNet datasets against different levels of defenses. Both theoretical and experimental results have validated the effectiveness of the proposed certifiable attack.