 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoin the High Accuracy Club on ImageNet with A Binary Neural Network Ticket
Dec 13, 2022



Binary neural networks are the extreme case of network quantization, which has long been thought of as a potential edge machine learning solution. However, the significant accuracy gap to the full-precision counterparts restricts their creative potential for mobile applications. In this work, we revisit the potential of binary neural networks and focus on a compelling but unanswered problem: how can a binary neural network achieve the crucial accuracy level (e.g., 80%) on ILSVRC-2012 ImageNet? We achieve this goal by enhancing the optimization process from three complementary perspectives: (1) We design a novel binary architecture BNext based on a comprehensive study of binary architectures and their optimization process. (2) We propose a novel knowledge-distillation technique to alleviate the counter-intuitive overfitting problem observed when attempting to train extremely accurate binary models. (3) We analyze the data augmentation pipeline for binary networks and modernize it with up-to-date techniques from full-precision models. The evaluation results on ImageNet show that BNext, for the first time, pushes the binary model accuracy boundary to 80.57% and significantly outperforms all the existing binary networks. Code and trained models are available at: https://github.com/hpi-xnor/BNext.git.
Synthesis in Style: Semantic Segmentation of Historical Documents using Synthetic Data
Jul 14, 2021
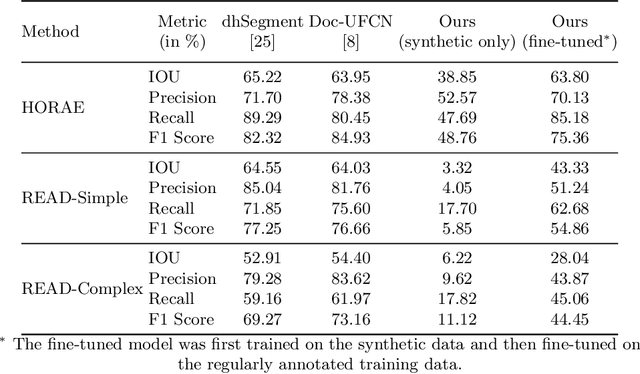


One of the most pressing problems in the automated analysis of historical documents is the availability of annotated training data. In this paper, we propose a novel method for the synthesis of training data for semantic segmentation of document images. We utilize clusters found in intermediate features of a StyleGAN generator for the synthesis of RGB and label images at the same time. Our model can be applied to any dataset of scanned documents without the need for manual annotation of individual images, as each model is custom-fit to the dataset. In our experiments, we show that models trained on our synthetic data can reach competitive performance on open benchmark datasets for line segmentation.
BoolNet: Minimizing The Energy Consumption of Binary Neural Networks
Jun 13, 2021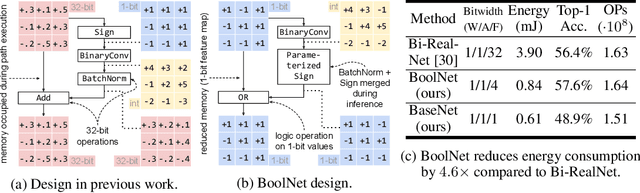
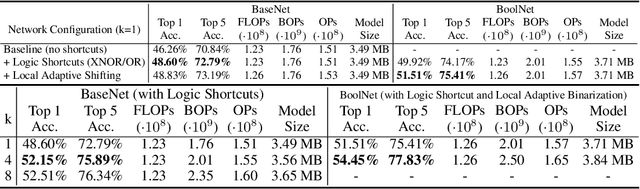
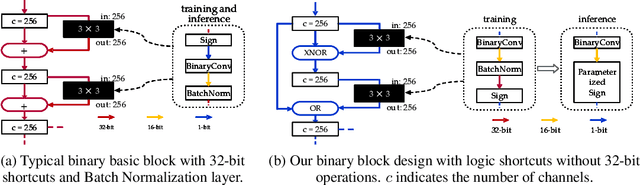
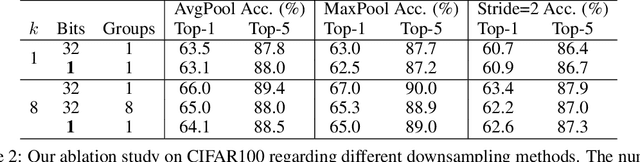
Recent works on Binary Neural Networks (BNNs) have made promising progress in narrowing the accuracy gap of BNNs to their 32-bit counterparts. However, the accuracy gains are often based on specialized model designs using additional 32-bit components. Furthermore, almost all previous BNNs use 32-bit for feature maps and the shortcuts enclosing the corresponding binary convolution blocks, which helps to effectively maintain the accuracy, but is not friendly to hardware accelerators with limited memory, energy, and computing resources. Thus, we raise the following question: How can accuracy and energy consumption be balanced in a BNN network design? We extensively study this fundamental problem in this work and propose a novel BNN architecture without most commonly used 32-bit components: \textit{BoolNet}. Experimental results on ImageNet demonstrate that BoolNet can achieve 4.6x energy reduction coupled with 1.2\% higher accuracy than the commonly used BNN architecture Bi-RealNet. Code and trained models are available at: https://github.com/hpi-xnor/BoolNet.
One Model to Reconstruct Them All: A Novel Way to Use the Stochastic Noise in StyleGAN
Oct 21, 2020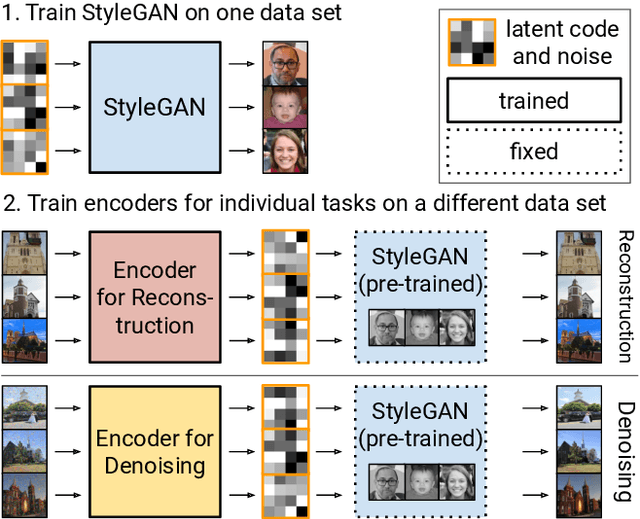
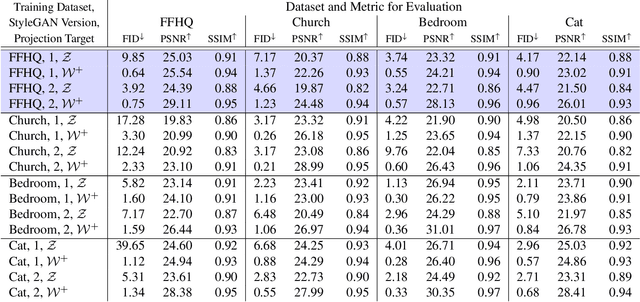
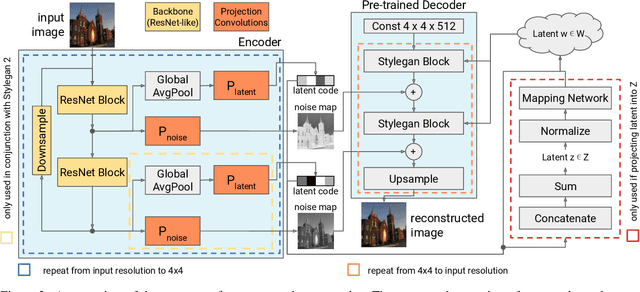
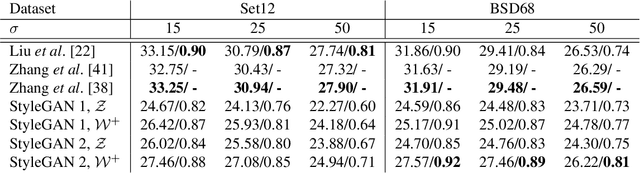
Generative Adversarial Networks (GANs) have achieved state-of-the-art performance for several image generation and manipulation tasks. Different works have improved the limited understanding of the latent space of GANs by embedding images into specific GAN architectures to reconstruct the original images. We present a novel StyleGAN-based autoencoder architecture, which can reconstruct images with very high quality across several data domains. We demonstrate a previously unknown grade of generalizablility by training the encoder and decoder independently and on different datasets. Furthermore, we provide new insights about the significance and capabilities of noise inputs of the well-known StyleGAN architecture. Our proposed architecture can handle up to 40 images per second on a single GPU, which is approximately 28x faster than previous approaches. Finally, our model also shows promising results, when compared to the state-of-the-art on the image denoising task, although it was not explicitly designed for this task.
MeliusNet: Can Binary Neural Networks Achieve MobileNet-level Accuracy?
Jan 16, 2020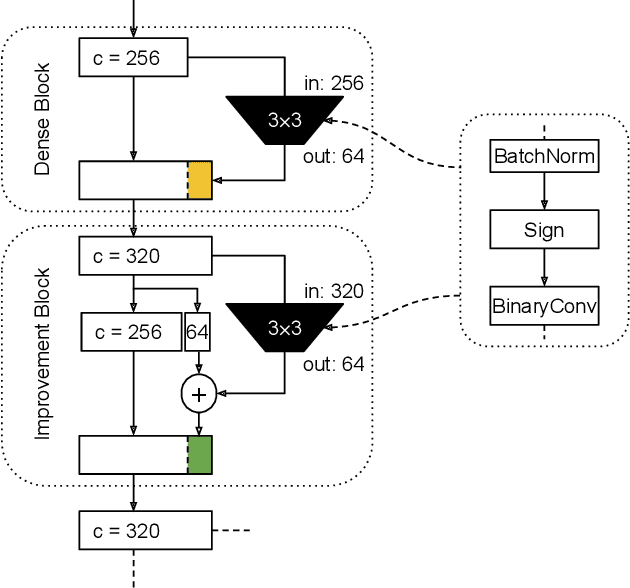
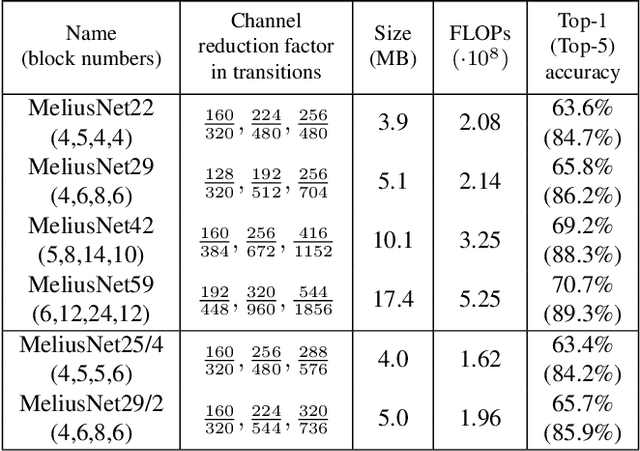
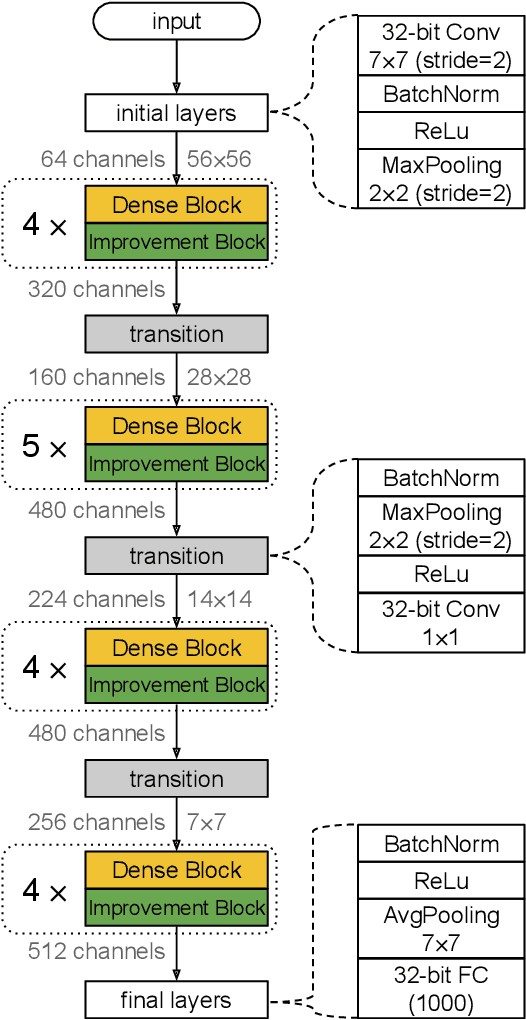
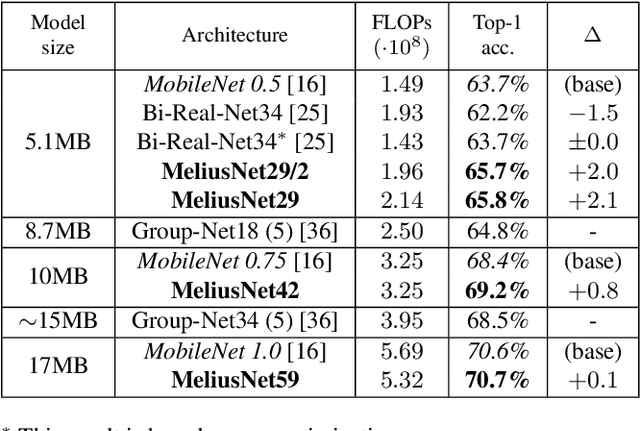
Binary Neural Networks (BNNs) are neural networks which use binary weights and activations instead of the typical 32-bit floating point values. They have reduced model sizes and allow for efficient inference on mobile or embedded devices with limited power and computational resources. However, the binarization of weights and activations leads to feature maps of lower quality and lower capacity and thus a drop in accuracy compared to traditional networks. Previous work has increased the number of channels or used multiple binary bases to alleviate these problems. In this paper, we instead present MeliusNet consisting of alternating two block designs, which consecutively increase the number of features and then improve the quality of these features. In addition, we propose a redesign of those layers that use 32-bit values in previous approaches to reduce the required number of operations. Experiments on the ImageNet dataset demonstrate the superior performance of our MeliusNet over a variety of popular binary architectures with regards to both computation savings and accuracy. Furthermore, with our method we trained BNN models, which for the first time can match the accuracy of the popular compact network MobileNet in terms of model size and accuracy. Our code is published online: https://github.com/hpi-xnor/BMXNet-v2
KISS: Keeping It Simple for Scene Text Recognition
Nov 19, 2019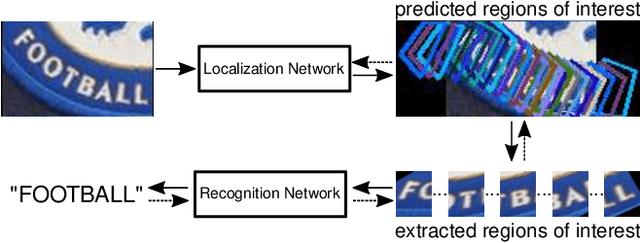
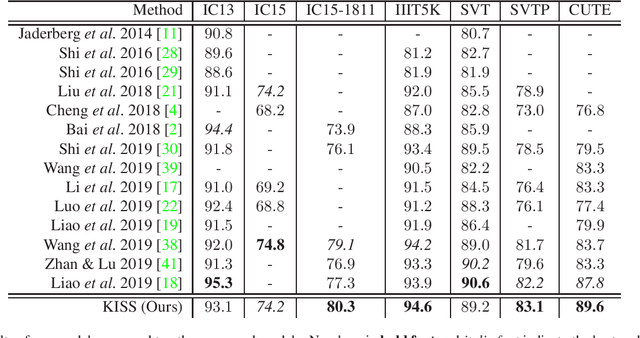
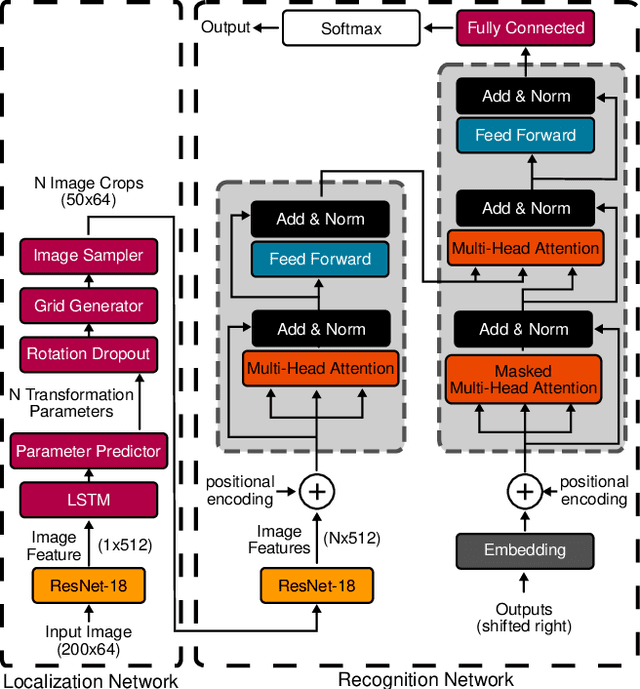
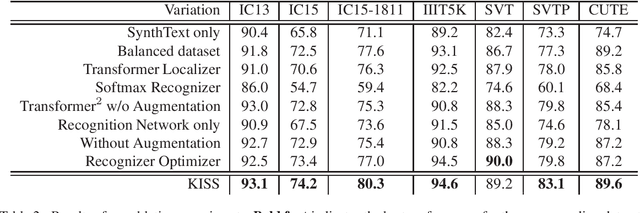
Over the past few years, several new methods for scene text recognition have been proposed. Most of these methods propose novel building blocks for neural networks. These novel building blocks are specially tailored for the task of scene text recognition and can thus hardly be used in any other tasks. In this paper, we introduce a new model for scene text recognition that only consists of off-the-shelf building blocks for neural networks. Our model (KISS) consists of two ResNet based feature extractors, a spatial transformer, and a transformer. We train our model only on publicly available, synthetic training data and evaluate it on a range of scene text recognition benchmarks, where we reach state-of-the-art or competitive performance, although our model does not use methods like 2D-attention, or image rectification.
Back to Simplicity: How to Train Accurate BNNs from Scratch?
Jun 19, 2019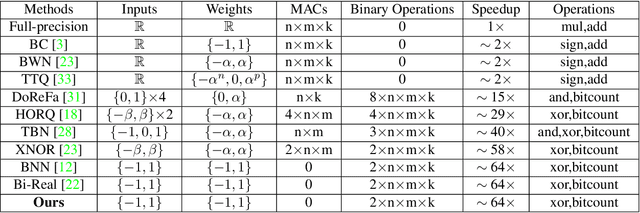


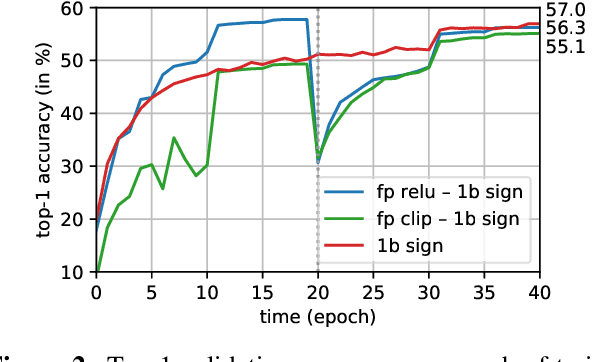
Binary Neural Networks (BNNs) show promising progress in reducing computational and memory costs but suffer from substantial accuracy degradation compared to their real-valued counterparts on large-scale datasets, e.g., ImageNet. Previous work mainly focused on reducing quantization errors of weights and activations, whereby a series of approximation methods and sophisticated training tricks have been proposed. In this work, we make several observations that challenge conventional wisdom. We revisit some commonly used techniques, such as scaling factors and custom gradients, and show that these methods are not crucial in training well-performing BNNs. On the contrary, we suggest several design principles for BNNs based on the insights learned and demonstrate that highly accurate BNNs can be trained from scratch with a simple training strategy. We propose a new BNN architecture BinaryDenseNet, which significantly surpasses all existing 1-bit CNNs on ImageNet without tricks. In our experiments, BinaryDenseNet achieves 18.6% and 7.6% relative improvement over the well-known XNOR-Network and the current state-of-the-art Bi-Real Net in terms of top-1 accuracy on ImageNet, respectively.
Training Competitive Binary Neural Networks from Scratch
Dec 05, 2018



Convolutional neural networks have achieved astonishing results in different application areas. Various methods that allow us to use these models on mobile and embedded devices have been proposed. Especially binary neural networks are a promising approach for devices with low computational power. However, training accurate binary models from scratch remains a challenge. Previous work often uses prior knowledge from full-precision models and complex training strategies. In our work, we focus on increasing the performance of binary neural networks without such prior knowledge and a much simpler training strategy. In our experiments we show that we are able to achieve state-of-the-art results on standard benchmark datasets. Further, to the best of our knowledge, we are the first to successfully adopt a network architecture with dense connections for binary networks, which lets us improve the state-of-the-art even further.
LoANs: Weakly Supervised Object Detection with Localizer Assessor Networks
Nov 15, 2018


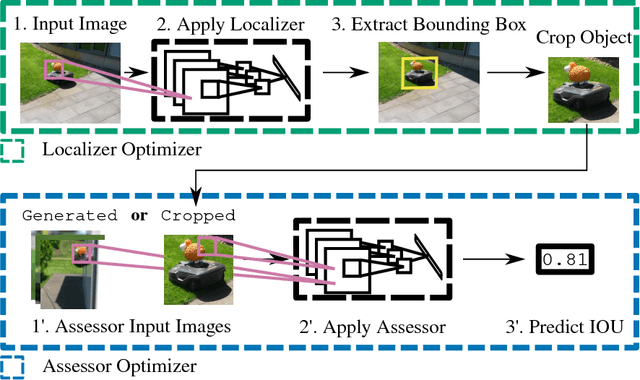
Recently, deep neural networks have achieved remarkable performance on the task of object detection and recognition. The reason for this success is mainly grounded in the availability of large scale, fully annotated datasets, but the creation of such a dataset is a complicated and costly task. In this paper, we propose a novel method for weakly supervised object detection that simplifies the process of gathering data for training an object detector. We train an ensemble of two models that work together in a student-teacher fashion. Our student (localizer) is a model that learns to localize an object, the teacher (assessor) assesses the quality of the localization and provides feedback to the student. The student uses this feedback to learn how to localize objects and is thus entirely supervised by the teacher, as we are using no labels for training the localizer. In our experiments, we show that our model is very robust to noise and reaches competitive performance compared to a state-of-the-art fully supervised approach. We also show the simplicity of creating a new dataset, based on a few videos (e.g. downloaded from YouTube) and artificially generated data.
Learning to Train a Binary Neural Network
Sep 27, 2018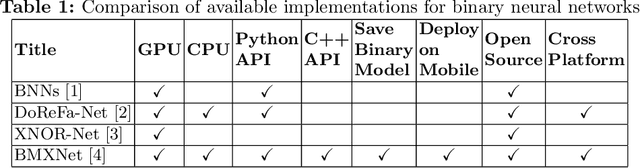
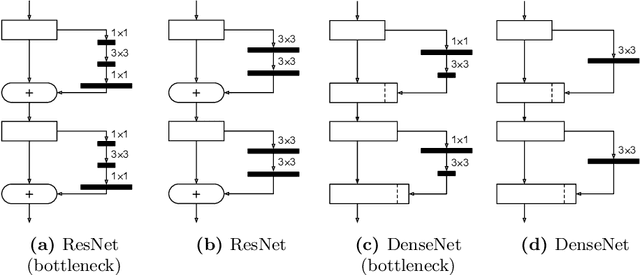
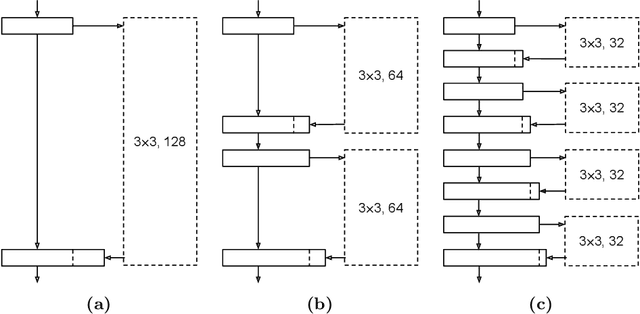

Convolutional neural networks have achieved astonishing results in different application areas. Various methods which allow us to use these models on mobile and embedded devices have been proposed. Especially binary neural networks seem to be a promising approach for these devices with low computational power. However, understanding binary neural networks and training accurate models for practical applications remains a challenge. In our work, we focus on increasing our understanding of the training process and making it accessible to everyone. We publish our code and models based on BMXNet for everyone to use. Within this framework, we systematically evaluated different network architectures and hyperparameters to provide useful insights on how to train a binary neural network. Further, we present how we improved accuracy by increasing the number of connections in the network.