 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Scene Text Detection using Deep Reinforcement Learning
Jan 13, 2022


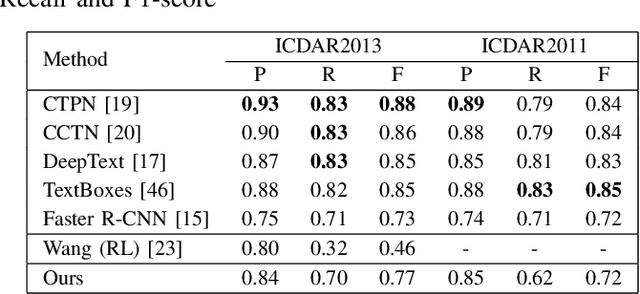
The challenging field of scene text detection requires complex data annotation, which is time-consuming and expensive. Techniques, such as weak supervision, can reduce the amount of data needed. In this paper we propose a weak supervision method for scene text detection, which makes use of reinforcement learning (RL). The reward received by the RL agent is estimated by a neural network, instead of being inferred from ground-truth labels. First, we enhance an existing supervised RL approach to text detection with several training optimizations, allowing us to close the performance gap to regression-based algorithms. We then use our proposed system in a weakly- and semi-supervised training on real-world data. Our results show that training in a weakly supervised setting is feasible. However, we find that using our model in a semi-supervised setting , e.g. when combining labeled synthetic data with unannotated real-world data, produces the best results.
Synthesis in Style: Semantic Segmentation of Historical Documents using Synthetic Data
Jul 14, 2021
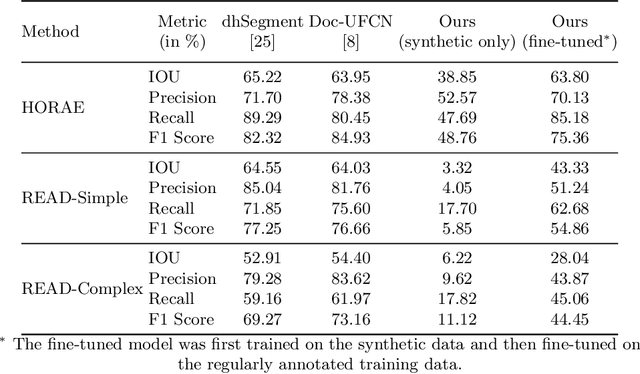


One of the most pressing problems in the automated analysis of historical documents is the availability of annotated training data. In this paper, we propose a novel method for the synthesis of training data for semantic segmentation of document images. We utilize clusters found in intermediate features of a StyleGAN generator for the synthesis of RGB and label images at the same time. Our model can be applied to any dataset of scanned documents without the need for manual annotation of individual images, as each model is custom-fit to the dataset. In our experiments, we show that models trained on our synthetic data can reach competitive performance on open benchmark datasets for line segmentation.
Handwriting Classification for the Analysis of Art-Historical Documents
Nov 04, 2020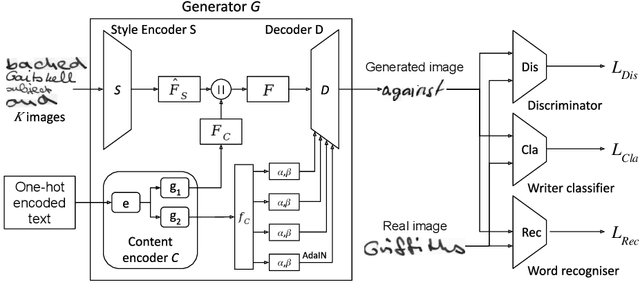
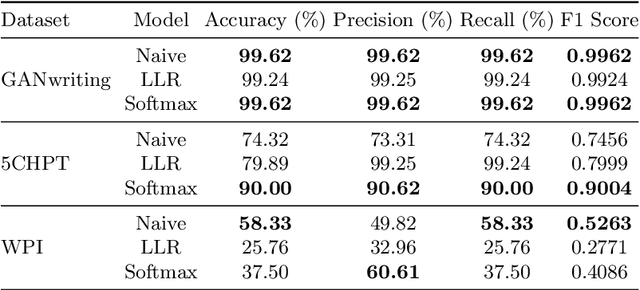

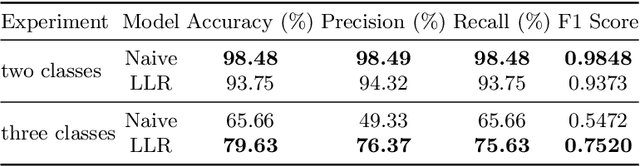
Digitized archives contain and preserve the knowledge of generations of scholars in millions of documents. The size of these archives calls for automatic analysis since a manual analysis by specialists is often too expensive. In this paper, we focus on the analysis of handwriting in scanned documents from the art-historic archive of the WPI. Since the archive consists of documents written in several languages and lacks annotated training data for the creation of recognition models, we propose the task of handwriting classification as a new step for a handwriting OCR pipeline. We propose a handwriting classification model that labels extracted text fragments, eg, numbers, dates, or words, based on their visual structure. Such a classification supports historians by highlighting documents that contain a specific class of text without the need to read the entire content. To this end, we develop and compare several deep learning-based models for text classification. In extensive experiments, we show the advantages and disadvantages of our proposed approach and discuss possible usage scenarios on a real-world dataset.
One Model to Reconstruct Them All: A Novel Way to Use the Stochastic Noise in StyleGAN
Oct 21, 2020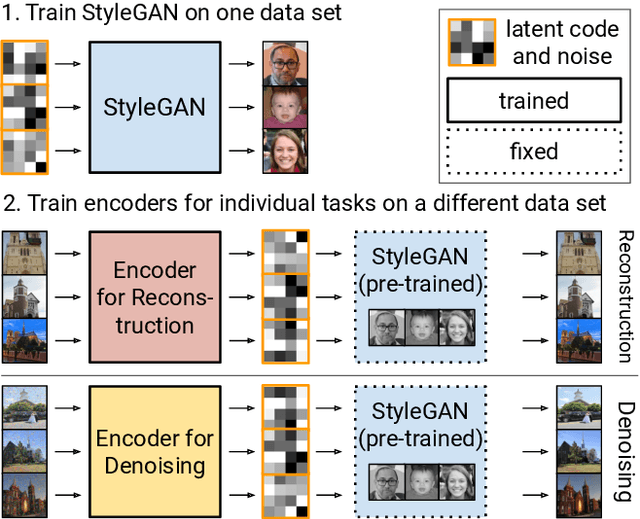
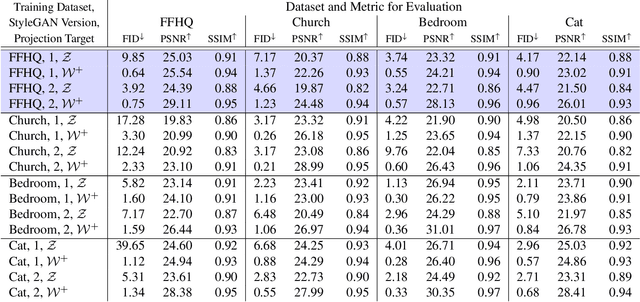
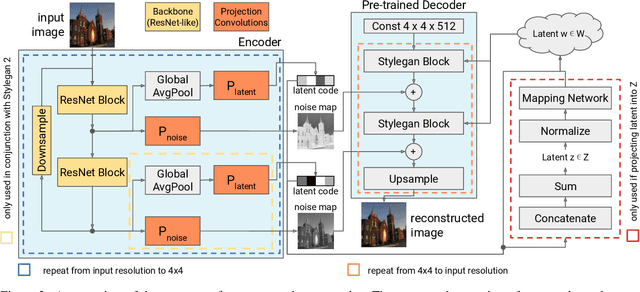
Generative Adversarial Networks (GANs) have achieved state-of-the-art performance for several image generation and manipulation tasks. Different works have improved the limited understanding of the latent space of GANs by embedding images into specific GAN architectures to reconstruct the original images. We present a novel StyleGAN-based autoencoder architecture, which can reconstruct images with very high quality across several data domains. We demonstrate a previously unknown grade of generalizablility by training the encoder and decoder independently and on different datasets. Furthermore, we provide new insights about the significance and capabilities of noise inputs of the well-known StyleGAN architecture. Our proposed architecture can handle up to 40 images per second on a single GPU, which is approximately 28x faster than previous approaches. Finally, our model also shows promising results, when compared to the state-of-the-art on the image denoising task, although it was not explicitly designed for this task.
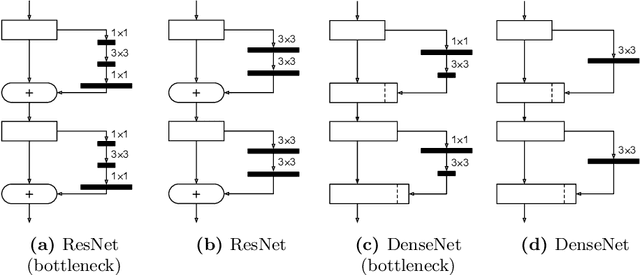
MeliusNet: Can Binary Neural Networks Achieve MobileNet-level Accuracy?
Jan 16, 2020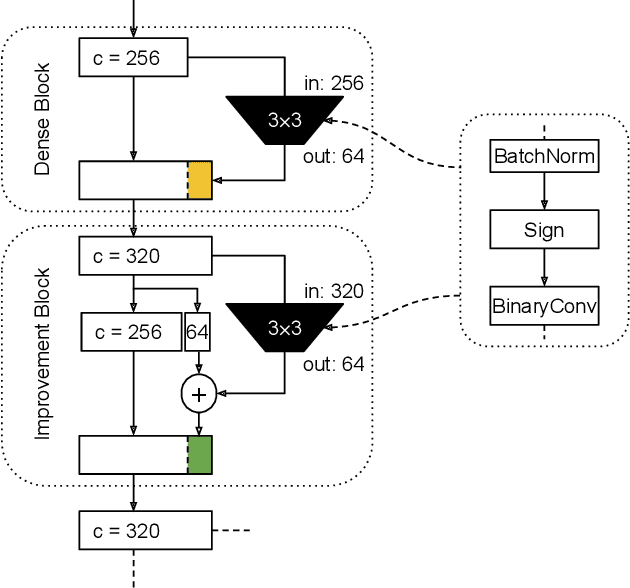
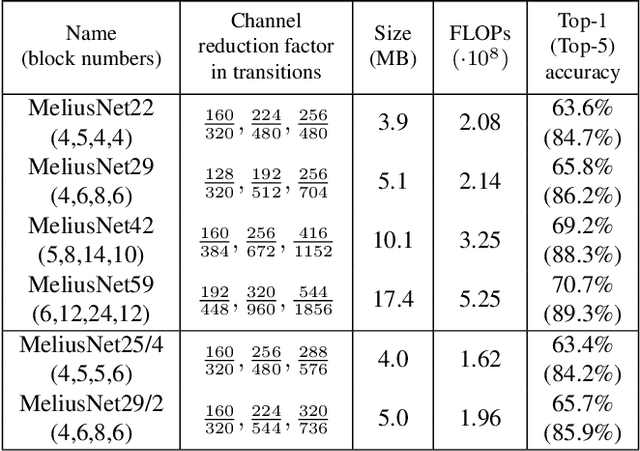
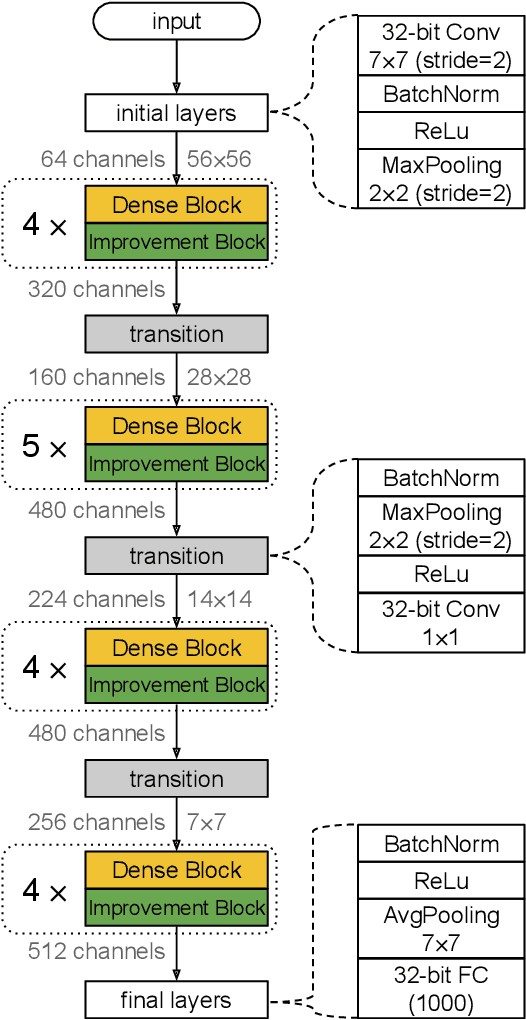
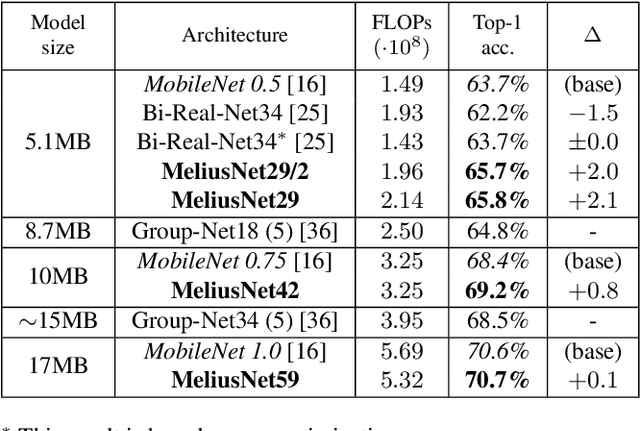
Binary Neural Networks (BNNs) are neural networks which use binary weights and activations instead of the typical 32-bit floating point values. They have reduced model sizes and allow for efficient inference on mobile or embedded devices with limited power and computational resources. However, the binarization of weights and activations leads to feature maps of lower quality and lower capacity and thus a drop in accuracy compared to traditional networks. Previous work has increased the number of channels or used multiple binary bases to alleviate these problems. In this paper, we instead present MeliusNet consisting of alternating two block designs, which consecutively increase the number of features and then improve the quality of these features. In addition, we propose a redesign of those layers that use 32-bit values in previous approaches to reduce the required number of operations. Experiments on the ImageNet dataset demonstrate the superior performance of our MeliusNet over a variety of popular binary architectures with regards to both computation savings and accuracy. Furthermore, with our method we trained BNN models, which for the first time can match the accuracy of the popular compact network MobileNet in terms of model size and accuracy. Our code is published online: https://github.com/hpi-xnor/BMXNet-v2
KISS: Keeping It Simple for Scene Text Recognition
Nov 19, 2019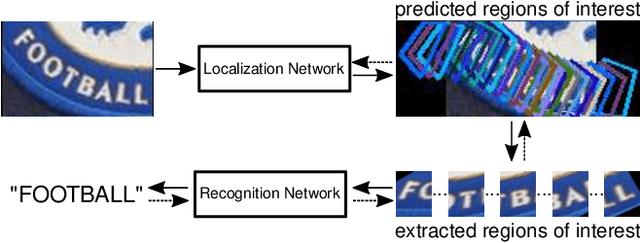
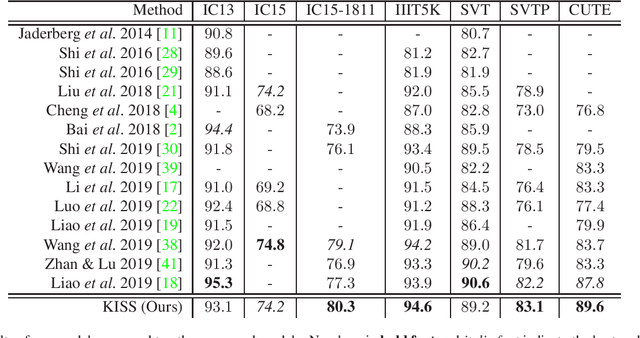
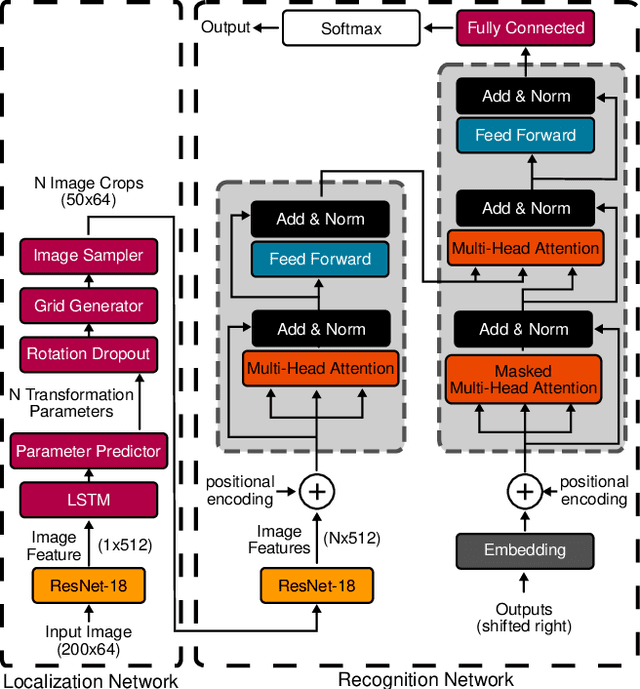
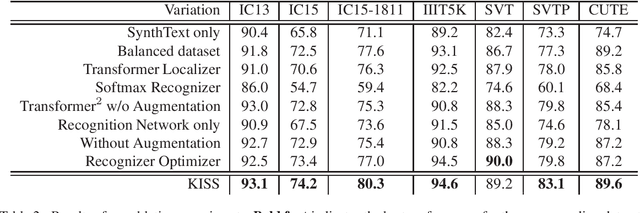
Over the past few years, several new methods for scene text recognition have been proposed. Most of these methods propose novel building blocks for neural networks. These novel building blocks are specially tailored for the task of scene text recognition and can thus hardly be used in any other tasks. In this paper, we introduce a new model for scene text recognition that only consists of off-the-shelf building blocks for neural networks. Our model (KISS) consists of two ResNet based feature extractors, a spatial transformer, and a transformer. We train our model only on publicly available, synthetic training data and evaluate it on a range of scene text recognition benchmarks, where we reach state-of-the-art or competitive performance, although our model does not use methods like 2D-attention, or image rectification.
LoANs: Weakly Supervised Object Detection with Localizer Assessor Networks
Nov 15, 2018


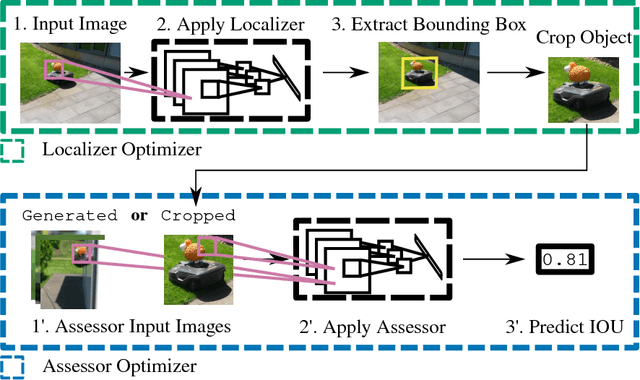
Recently, deep neural networks have achieved remarkable performance on the task of object detection and recognition. The reason for this success is mainly grounded in the availability of large scale, fully annotated datasets, but the creation of such a dataset is a complicated and costly task. In this paper, we propose a novel method for weakly supervised object detection that simplifies the process of gathering data for training an object detector. We train an ensemble of two models that work together in a student-teacher fashion. Our student (localizer) is a model that learns to localize an object, the teacher (assessor) assesses the quality of the localization and provides feedback to the student. The student uses this feedback to learn how to localize objects and is thus entirely supervised by the teacher, as we are using no labels for training the localizer. In our experiments, we show that our model is very robust to noise and reaches competitive performance compared to a state-of-the-art fully supervised approach. We also show the simplicity of creating a new dataset, based on a few videos (e.g. downloaded from YouTube) and artificially generated data.
Learning to Train a Binary Neural Network
Sep 27, 2018
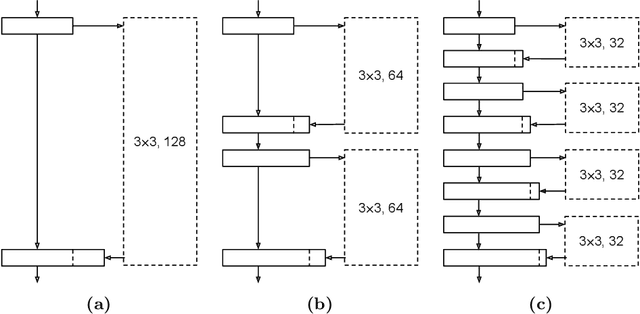

Convolutional neural networks have achieved astonishing results in different application areas. Various methods which allow us to use these models on mobile and embedded devices have been proposed. Especially binary neural networks seem to be a promising approach for these devices with low computational power. However, understanding binary neural networks and training accurate models for practical applications remains a challenge. In our work, we focus on increasing our understanding of the training process and making it accessible to everyone. We publish our code and models based on BMXNet for everyone to use. Within this framework, we systematically evaluated different network architectures and hyperparameters to provide useful insights on how to train a binary neural network. Further, we present how we improved accuracy by increasing the number of connections in the network.
SEE: Towards Semi-Supervised End-to-End Scene Text Recognition
Dec 14, 2017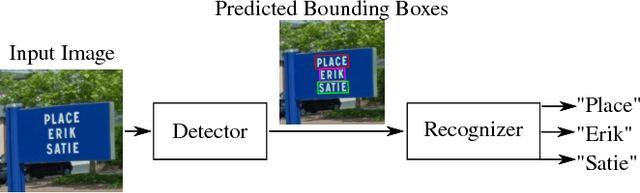

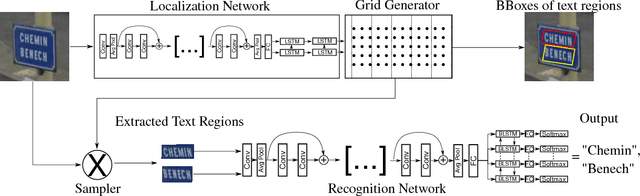

Detecting and recognizing text in natural scene images is a challenging, yet not completely solved task. In recent years several new systems that try to solve at least one of the two sub-tasks (text detection and text recognition) have been proposed. In this paper we present SEE, a step towards semi-supervised neural networks for scene text detection and recognition, that can be optimized end-to-end. Most existing works consist of multiple deep neural networks and several pre-processing steps. In contrast to this, we propose to use a single deep neural network, that learns to detect and recognize text from natural images, in a semi-supervised way. SEE is a network that integrates and jointly learns a spatial transformer network, which can learn to detect text regions in an image, and a text recognition network that takes the identified text regions and recognizes their textual content. We introduce the idea behind our novel approach and show its feasibility, by performing a range of experiments on standard benchmark datasets, where we achieve competitive results.
Language Identification Using Deep Convolutional Recurrent Neural Networks
Aug 16, 2017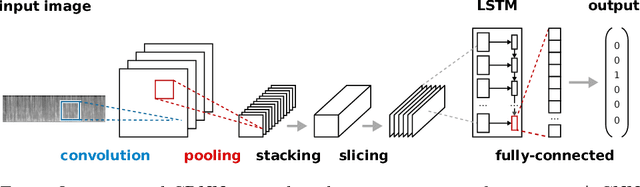
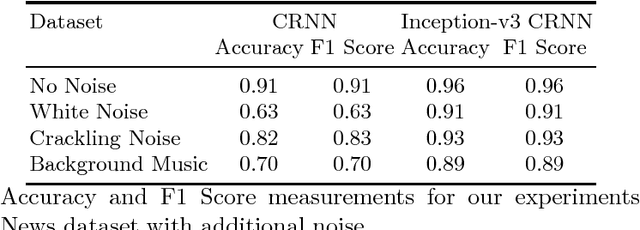
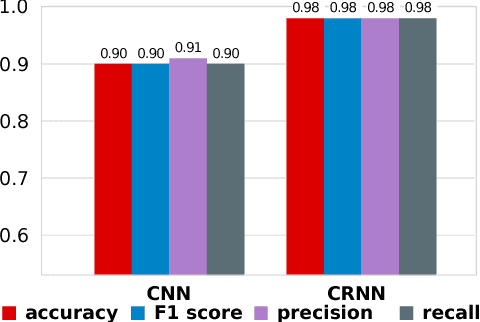
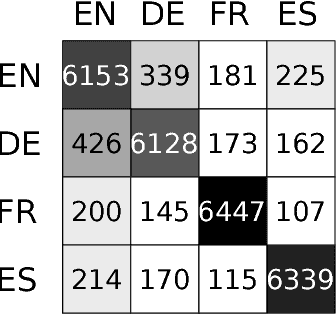
Language Identification (LID) systems are used to classify the spoken language from a given audio sample and are typically the first step for many spoken language processing tasks, such as Automatic Speech Recognition (ASR) systems. Without automatic language detection, speech utterances cannot be parsed correctly and grammar rules cannot be applied, causing subsequent speech recognition steps to fail. We propose a LID system that solves the problem in the image domain, rather than the audio domain. We use a hybrid Convolutional Recurrent Neural Network (CRNN) that operates on spectrogram images of the provided audio snippets. In extensive experiments we show, that our model is applicable to a range of noisy scenarios and can easily be extended to previously unknown languages, while maintaining its classification accuracy. We release our code and a large scale training set for LID systems to the community.