 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Identification Using Deep Convolutional Recurrent Neural Networks
Paper and Code
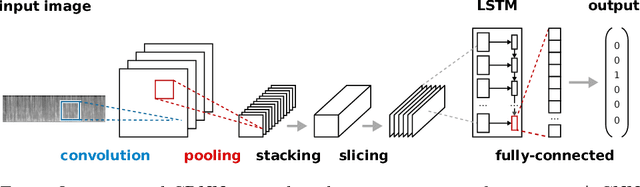
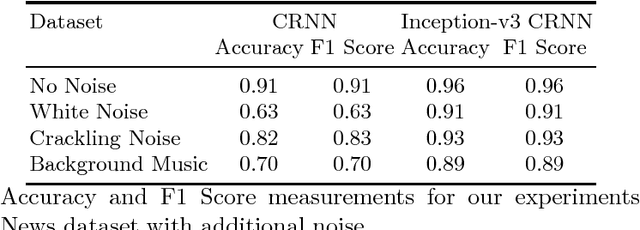
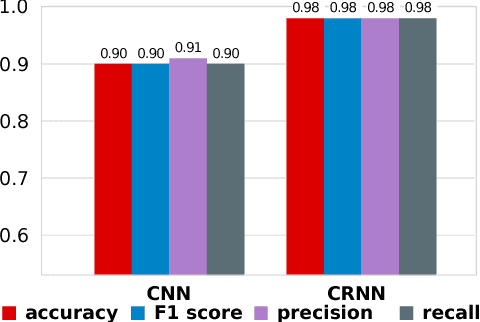
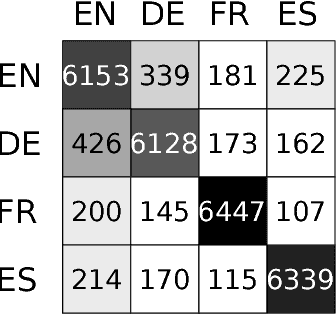
Language Identification (LID) systems are used to classify the spoken language from a given audio sample and are typically the first step for many spoken language processing tasks, such as Automatic Speech Recognition (ASR) systems. Without automatic language detection, speech utterances cannot be parsed correctly and grammar rules cannot be applied, causing subsequent speech recognition steps to fail. We propose a LID system that solves the problem in the image domain, rather than the audio domain. We use a hybrid Convolutional Recurrent Neural Network (CRNN) that operates on spectrogram images of the provided audio snippets. In extensive experiments we show, that our model is applicable to a range of noisy scenarios and can easily be extended to previously unknown languages, while maintaining its classification accuracy. We release our code and a large scale training set for LID systems to the community.