 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKISS: Keeping It Simple for Scene Text Recognition
Paper and Code
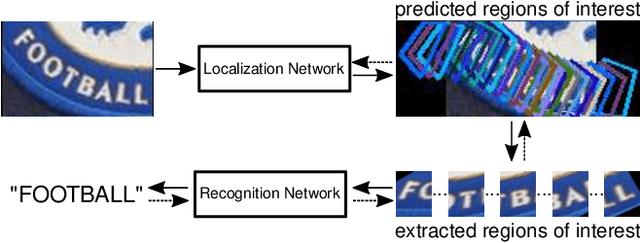
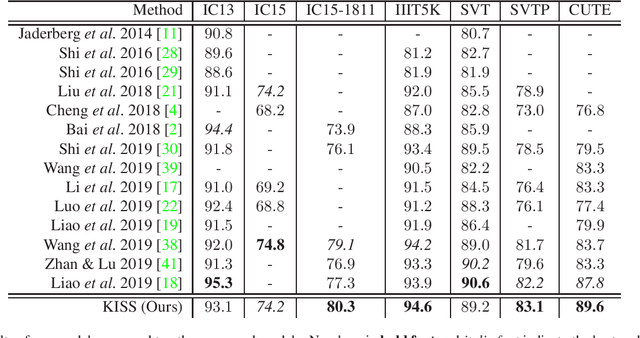
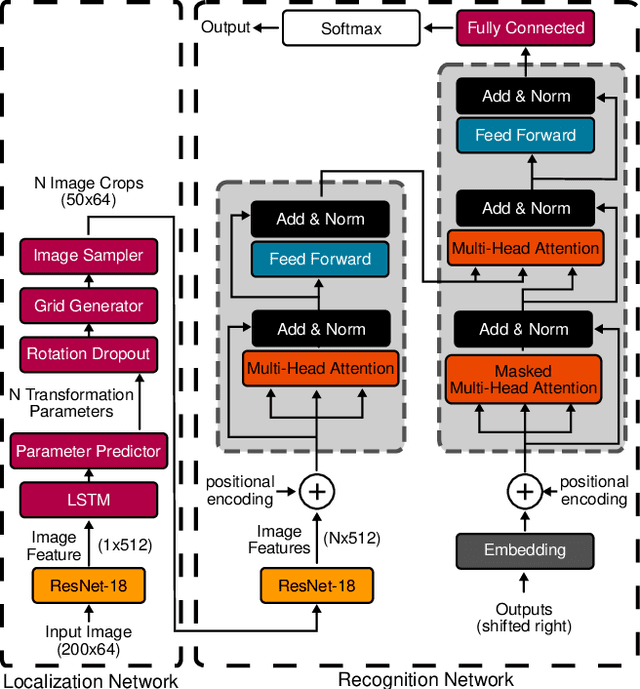
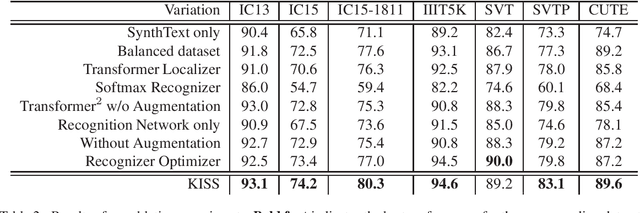
Over the past few years, several new methods for scene text recognition have been proposed. Most of these methods propose novel building blocks for neural networks. These novel building blocks are specially tailored for the task of scene text recognition and can thus hardly be used in any other tasks. In this paper, we introduce a new model for scene text recognition that only consists of off-the-shelf building blocks for neural networks. Our model (KISS) consists of two ResNet based feature extractors, a spatial transformer, and a transformer. We train our model only on publicly available, synthetic training data and evaluate it on a range of scene text recognition benchmarks, where we reach state-of-the-art or competitive performance, although our model does not use methods like 2D-attention, or image rectification.