 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesis in Style: Semantic Segmentation of Historical Documents using Synthetic Data
Jul 14, 2021
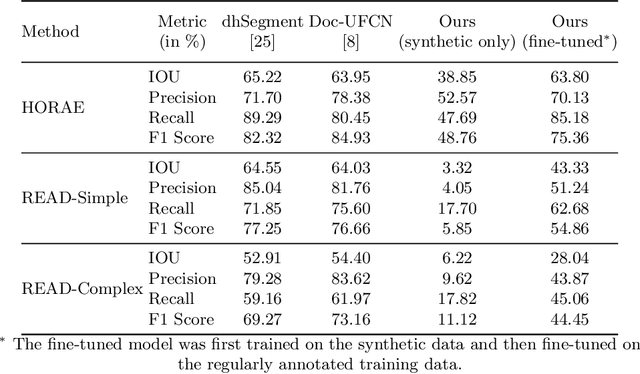


One of the most pressing problems in the automated analysis of historical documents is the availability of annotated training data. In this paper, we propose a novel method for the synthesis of training data for semantic segmentation of document images. We utilize clusters found in intermediate features of a StyleGAN generator for the synthesis of RGB and label images at the same time. Our model can be applied to any dataset of scanned documents without the need for manual annotation of individual images, as each model is custom-fit to the dataset. In our experiments, we show that models trained on our synthetic data can reach competitive performance on open benchmark datasets for line segmentation.
Handwriting Classification for the Analysis of Art-Historical Documents
Nov 04, 2020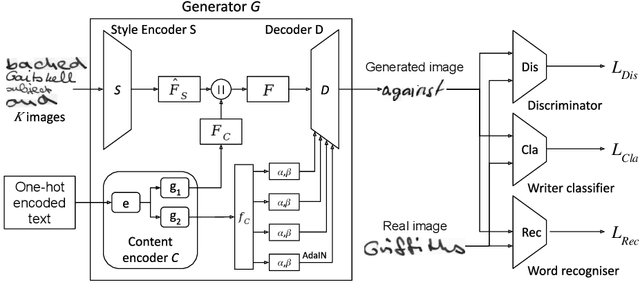
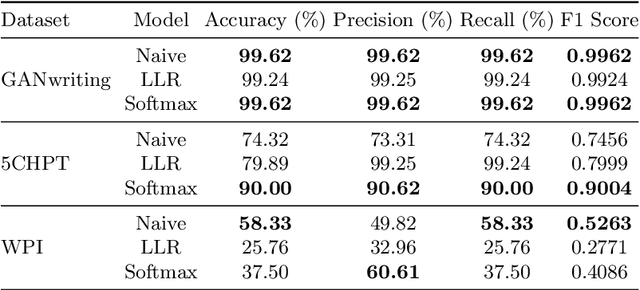

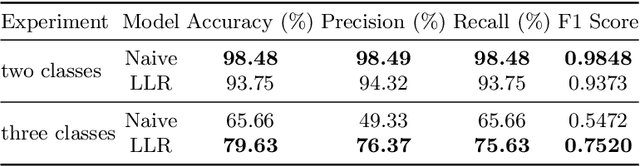
Digitized archives contain and preserve the knowledge of generations of scholars in millions of documents. The size of these archives calls for automatic analysis since a manual analysis by specialists is often too expensive. In this paper, we focus on the analysis of handwriting in scanned documents from the art-historic archive of the WPI. Since the archive consists of documents written in several languages and lacks annotated training data for the creation of recognition models, we propose the task of handwriting classification as a new step for a handwriting OCR pipeline. We propose a handwriting classification model that labels extracted text fragments, eg, numbers, dates, or words, based on their visual structure. Such a classification supports historians by highlighting documents that contain a specific class of text without the need to read the entire content. To this end, we develop and compare several deep learning-based models for text classification. In extensive experiments, we show the advantages and disadvantages of our proposed approach and discuss possible usage scenarios on a real-world dataset.