 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Simplicity: How to Train Accurate BNNs from Scratch?
Paper and Code
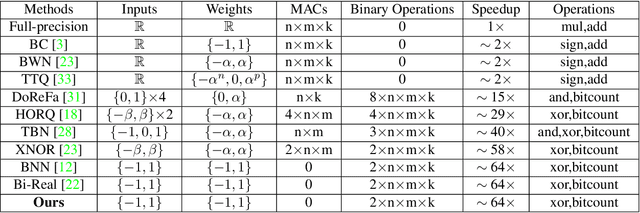


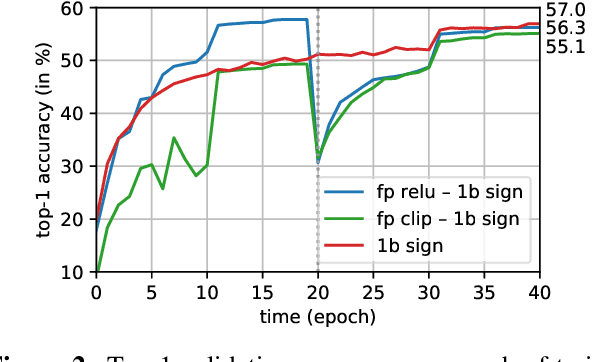
Binary Neural Networks (BNNs) show promising progress in reducing computational and memory costs but suffer from substantial accuracy degradation compared to their real-valued counterparts on large-scale datasets, e.g., ImageNet. Previous work mainly focused on reducing quantization errors of weights and activations, whereby a series of approximation methods and sophisticated training tricks have been proposed. In this work, we make several observations that challenge conventional wisdom. We revisit some commonly used techniques, such as scaling factors and custom gradients, and show that these methods are not crucial in training well-performing BNNs. On the contrary, we suggest several design principles for BNNs based on the insights learned and demonstrate that highly accurate BNNs can be trained from scratch with a simple training strategy. We propose a new BNN architecture BinaryDenseNet, which significantly surpasses all existing 1-bit CNNs on ImageNet without tricks. In our experiments, BinaryDenseNet achieves 18.6% and 7.6% relative improvement over the well-known XNOR-Network and the current state-of-the-art Bi-Real Net in terms of top-1 accuracy on ImageNet, respectively.