 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightRetriever: A LLM-based Hybrid Retrieval Architecture with 1000x Faster Query Inference
May 18, 2025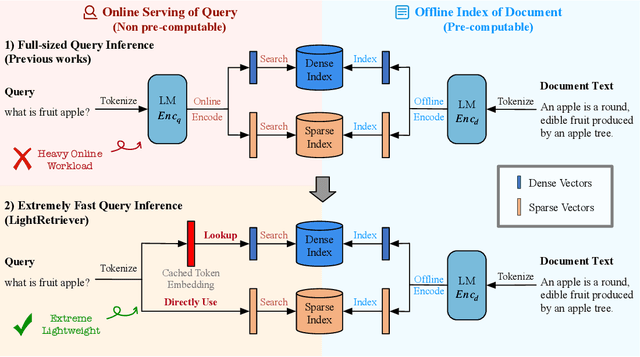
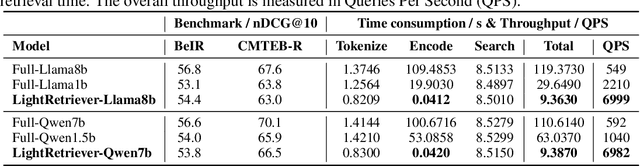

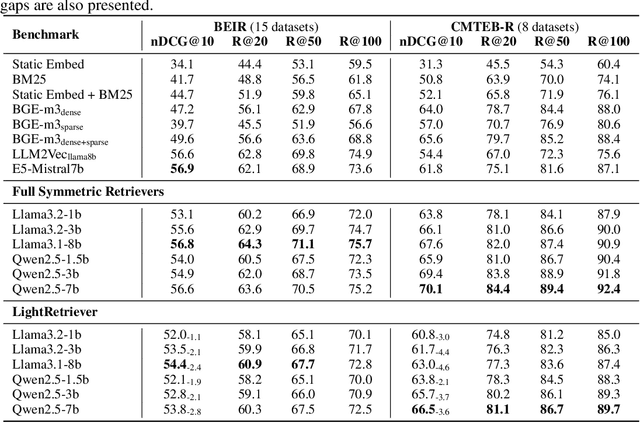
Large Language Models (LLMs)-based hybrid retrieval uses LLMs to encode queries and documents into low-dimensional dense or high-dimensional sparse vectors. It retrieves documents relevant to search queries based on vector similarities. Documents are pre-encoded offline, while queries arrive in real-time, necessitating an efficient online query encoder. Although LLMs significantly enhance retrieval capabilities, serving deeply parameterized LLMs slows down query inference throughput and increases demands for online deployment resources. In this paper, we propose LightRetriever, a novel LLM-based hybrid retriever with extremely lightweight query encoders. Our method retains a full-sized LLM for document encoding, but reduces the workload of query encoding to no more than an embedding lookup. Compared to serving a full-sized LLM on an H800 GPU, our approach achieves over a 1000x speedup for query inference with GPU acceleration, and even a 20x speedup without GPU. Experiments on large-scale retrieval benchmarks demonstrate that our method generalizes well across diverse retrieval tasks, retaining an average of 95% full-sized performance.
Task-level Distributionally Robust Optimization for Large Language Model-based Dense Retrieval
Aug 20, 2024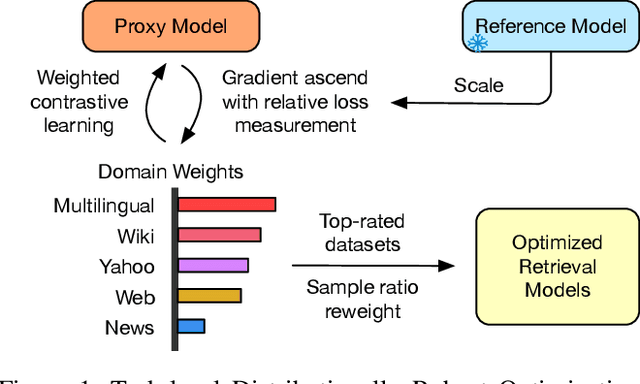

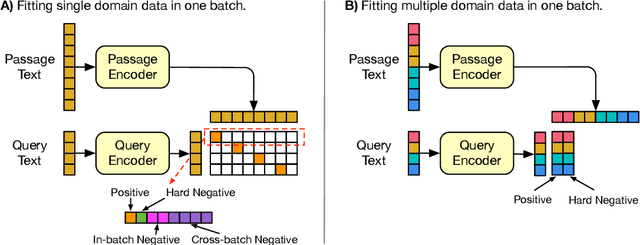
Large Language Model-based Dense Retrieval (LLM-DR) optimizes over numerous heterogeneous fine-tuning collections from different domains. However, the discussion about its training data distribution is still minimal. Previous studies rely on empirically assigned dataset choices or sampling ratios, which inevitably leads to sub-optimal retrieval performances. In this paper, we propose a new task-level Distributionally Robust Optimization (tDRO) algorithm for LLM-DR fine-tuning, targeted at improving the universal domain generalization ability by end-to-end reweighting the data distribution of each task. The tDRO parameterizes the domain weights and updates them with scaled domain gradients. The optimized weights are then transferred to the LLM-DR fine-tuning to train more robust retrievers. Experiments show optimal improvements in large-scale retrieval benchmarks and reduce up to 30% dataset usage after applying our optimization algorithm with a series of different-sized LLM-DR models.
LLMaAA: Making Large Language Models as Active Annotators
Oct 31, 2023



Prevalent supervised learning methods in natural language processing (NLP) are notoriously data-hungry, which demand large amounts of high-quality annotated data. In practice, acquiring such data is a costly endeavor. Recently, the superior few-shot performance of large language models (LLMs) has propelled the development of dataset generation, where the training data are solely synthesized from LLMs. However, such an approach usually suffers from low-quality issues, and requires orders of magnitude more labeled data to achieve satisfactory performance. To fully exploit the potential of LLMs and make use of massive unlabeled data, we propose LLMaAA, which takes LLMs as annotators and puts them into an active learning loop to determine what to annotate efficiently. To learn robustly with pseudo labels, we optimize both the annotation and training processes: (1) we draw k-NN examples from a small demonstration pool as in-context examples, and (2) we adopt the example reweighting technique to assign training samples with learnable weights. Compared with previous approaches, LLMaAA features both efficiency and reliability. We conduct experiments and analysis on two classic NLP tasks, named entity recognition and relation extraction. With LLMaAA, task-specific models trained from LLM-generated labels can outperform the teacher within only hundreds of annotated examples, which is much more cost-effective than other baselines.
Two is Better Than One: Answering Complex Questions by Multiple Knowledge Sources with Generalized Links
Sep 11, 2023



Incorporating multiple knowledge sources is proven to be beneficial for answering complex factoid questions. To utilize multiple knowledge bases (KB), previous works merge all KBs into a single graph via entity alignment and reduce the problem to question-answering (QA) over the fused KB. In reality, various link relations between KBs might be adopted in QA over multi-KBs. In addition to the identity between the alignable entities (i.e. full link), unalignable entities expressing the different aspects or types of an abstract concept may also be treated identical in a question (i.e. partial link). Hence, the KB fusion in prior works fails to represent all types of links, restricting their ability to comprehend multi-KBs for QA. In this work, we formulate the novel Multi-KB-QA task that leverages the full and partial links among multiple KBs to derive correct answers, a benchmark with diversified link and query types is also constructed to efficiently evaluate Multi-KB-QA performance. Finally, we propose a method for Multi-KB-QA that encodes all link relations in the KB embedding to score and rank candidate answers. Experiments show that our method markedly surpasses conventional KB-QA systems in Multi-KB-QA, justifying the necessity of devising this task.