 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightRetriever: A LLM-based Hybrid Retrieval Architecture with 1000x Faster Query Inference
May 18, 2025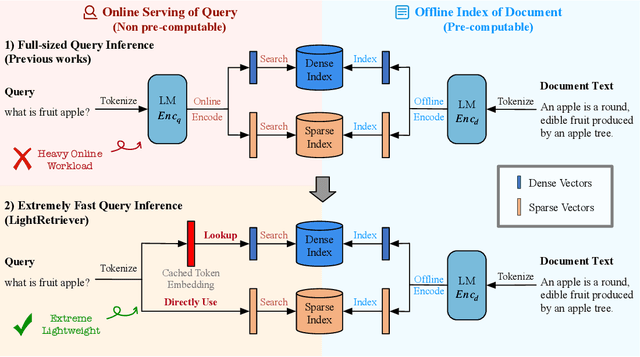
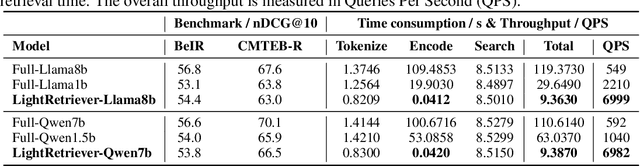

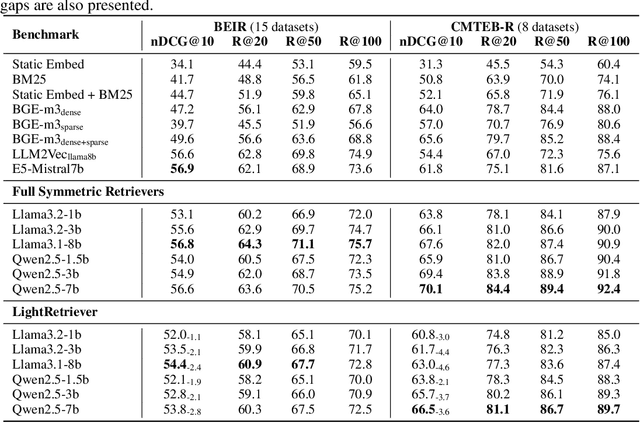
Large Language Models (LLMs)-based hybrid retrieval uses LLMs to encode queries and documents into low-dimensional dense or high-dimensional sparse vectors. It retrieves documents relevant to search queries based on vector similarities. Documents are pre-encoded offline, while queries arrive in real-time, necessitating an efficient online query encoder. Although LLMs significantly enhance retrieval capabilities, serving deeply parameterized LLMs slows down query inference throughput and increases demands for online deployment resources. In this paper, we propose LightRetriever, a novel LLM-based hybrid retriever with extremely lightweight query encoders. Our method retains a full-sized LLM for document encoding, but reduces the workload of query encoding to no more than an embedding lookup. Compared to serving a full-sized LLM on an H800 GPU, our approach achieves over a 1000x speedup for query inference with GPU acceleration, and even a 20x speedup without GPU. Experiments on large-scale retrieval benchmarks demonstrate that our method generalizes well across diverse retrieval tasks, retaining an average of 95% full-sized performance.
PulseBat: A field-accessible dataset for second-life battery diagnostics from realistic histories using multidimensional rapid pulse test
Feb 24, 2025As electric vehicles (EVs) approach the end of their operational life, their batteries retain significant economic value and present promising opportunities for second-life use and material recycling. This is particularly compelling for Global South and other underdeveloped regions, where reliable energy storage is vital to addressing critical challenges posed by weak and even nonexistent power grid and energy infrastructures. However, despite this potential, widespread adoption has been hindered by critical uncertainties surrounding the technical performance, safety, and recertification of second-life batteries. In cases where they have been redeployed, mismatches between estimated and actual performance often render batteries technically unsuitable or hazardous, turning them into liabilities for communities they were intended to benefit. This considerable misalignment exacerbates energy access disparities and undermines the broader vision of energy justice, highlighting an urgent need for robust and scalable solutions to unlock the potential. In the PulseBat Dataset, the authors tested 464 retired lithium-ion batteries, covering 3 cathode material types, 6 historical usages, 3 physical formats, and 6 capacity designs. The pulse test experiments were performed repeatedly for each second-life battery with 10 pulse width, 10 pulse magnitude, multiple state-of-charge, and state-of-health conditions, e.g., from 0.37 to 1.03. The PulseBat Dataset recorded these test conditions and the voltage response as well as the temperature signals that were subject to the injected pulse current, which could be used as a valuable data resource for critical diagnostics tasks such as state-of-charge estimation, state-of-health estimation, cathode material type identification, open-circuit voltage reconstruction, thermal management, and beyond.
* Extended data descriptor of Nat Commun 15, 10154 (2024), https://doi.org/10.1038/s41467-024-54454-0
CartesianMoE: Boosting Knowledge Sharing among Experts via Cartesian Product Routing in Mixture-of-Experts
Oct 21, 2024Large language models (LLM) have been attracting much attention from the community recently, due to their remarkable performance in all kinds of downstream tasks. According to the well-known scaling law, scaling up a dense LLM enhances its capabilities, but also significantly increases the computational complexity. Mixture-of-Experts (MoE) models address that by allowing the model size to grow without substantially raising training or inference costs. Yet MoE models face challenges regarding knowledge sharing among experts, making their performance somehow sensitive to routing accuracy. To tackle that, previous works introduced shared experts and combined their outputs with those of the top $K$ routed experts in an ``addition'' manner. In this paper, inspired by collective matrix factorization to learn shared knowledge among data, we propose CartesianMoE, which implements more effective knowledge sharing among experts in more like a ``multiplication'' manner. Extensive experimental results indicate that CartesianMoE outperforms previous MoE models for building LLMs, in terms of both perplexity and downstream task performance. And we also find that CartesianMoE achieves better expert routing robustness.
Task-level Distributionally Robust Optimization for Large Language Model-based Dense Retrieval
Aug 20, 2024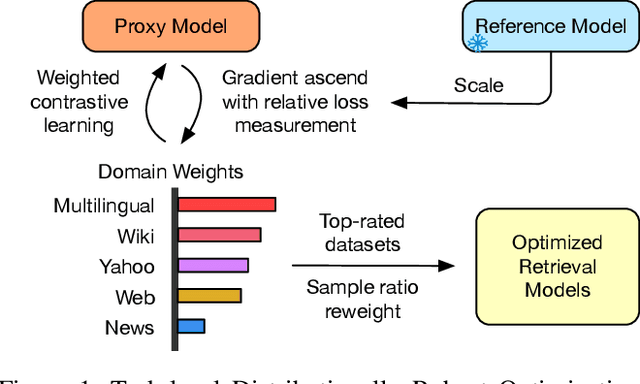

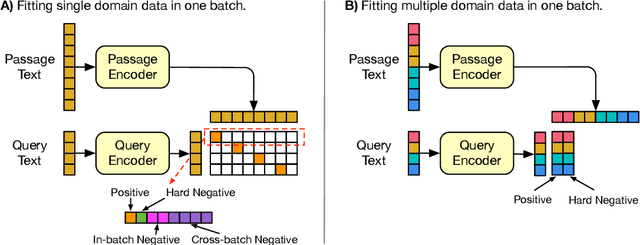
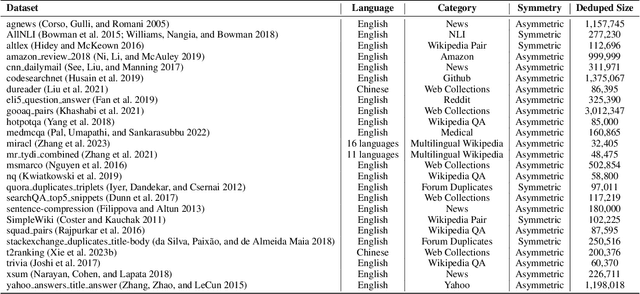
Large Language Model-based Dense Retrieval (LLM-DR) optimizes over numerous heterogeneous fine-tuning collections from different domains. However, the discussion about its training data distribution is still minimal. Previous studies rely on empirically assigned dataset choices or sampling ratios, which inevitably leads to sub-optimal retrieval performances. In this paper, we propose a new task-level Distributionally Robust Optimization (tDRO) algorithm for LLM-DR fine-tuning, targeted at improving the universal domain generalization ability by end-to-end reweighting the data distribution of each task. The tDRO parameterizes the domain weights and updates them with scaled domain gradients. The optimized weights are then transferred to the LLM-DR fine-tuning to train more robust retrievers. Experiments show optimal improvements in large-scale retrieval benchmarks and reduce up to 30% dataset usage after applying our optimization algorithm with a series of different-sized LLM-DR models.
MaskMoE: Boosting Token-Level Learning via Routing Mask in Mixture-of-Experts
Jul 13, 2024Scaling model capacity enhances its capabilities but significantly increases computation. Mixture-of-Experts models (MoEs) address this by allowing model capacity to scale without substantially increasing training or inference costs. Despite their promising results, MoE models encounter several challenges. Primarily, the dispersion of training tokens across multiple experts can lead to underfitting, particularly for infrequent tokens. Additionally, while fixed routing mechanisms can mitigate this issue, they compromise on the diversity of representations. In this paper, we propose MaskMoE, a method designed to enhance token-level learning by employing a routing masking technique within the Mixture-of-Experts model. MaskMoE is capable of maintaining representation diversity while achieving more comprehensive training. Experimental results demonstrate that our method outperforms previous dominant Mixture-of-Experts models in both perplexity (PPL) and downstream tasks.
Drop your Decoder: Pre-training with Bag-of-Word Prediction for Dense Passage Retrieval
Jan 20, 2024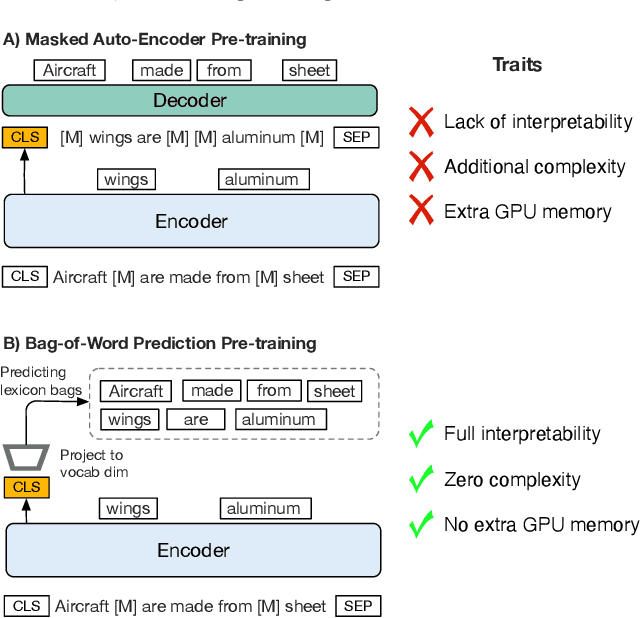
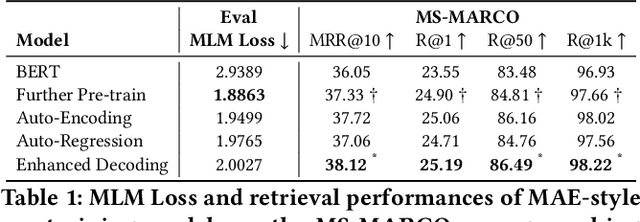
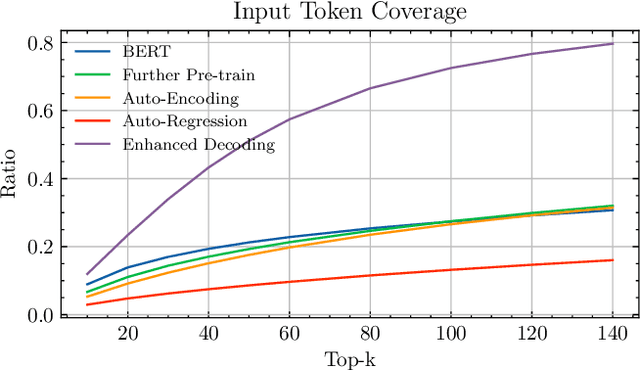
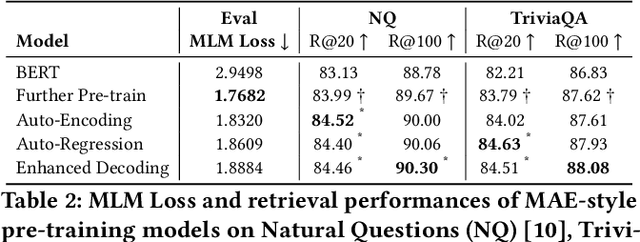
Masked auto-encoder pre-training has emerged as a prevalent technique for initializing and enhancing dense retrieval systems. It generally utilizes additional Transformer decoder blocks to provide sustainable supervision signals and compress contextual information into dense representations. However, the underlying reasons for the effectiveness of such a pre-training technique remain unclear. The usage of additional Transformer-based decoders also incurs significant computational costs. In this study, we aim to shed light on this issue by revealing that masked auto-encoder (MAE) pre-training with enhanced decoding significantly improves the term coverage of input tokens in dense representations, compared to vanilla BERT checkpoints. Building upon this observation, we propose a modification to the traditional MAE by replacing the decoder of a masked auto-encoder with a completely simplified Bag-of-Word prediction task. This modification enables the efficient compression of lexical signals into dense representations through unsupervised pre-training. Remarkably, our proposed method achieves state-of-the-art retrieval performance on several large-scale retrieval benchmarks without requiring any additional parameters, which provides a 67% training speed-up compared to standard masked auto-encoder pre-training with enhanced decoding.
HC3 Plus: A Semantic-Invariant Human ChatGPT Comparison Corpus
Sep 06, 2023
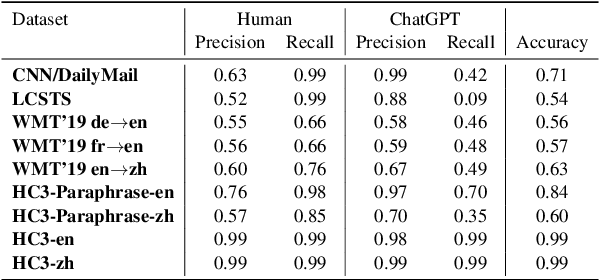
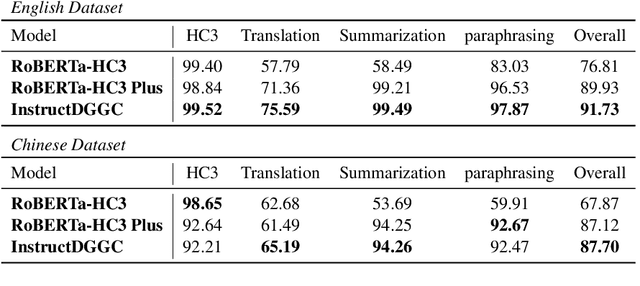

ChatGPT has gained significant interest due to its impressive performance, but people are increasingly concerned about its potential risks, particularly around the detection of AI-generated content (AIGC), which is often difficult for untrained humans to identify. Current datasets utilized for detecting ChatGPT-generated text primarily center around question-answering, yet they tend to disregard tasks that possess semantic-invariant properties, such as summarization, translation, and paraphrasing. Our primary studies demonstrate that detecting model-generated text on semantic-invariant tasks is more difficult. To fill this gap, we introduce a more extensive and comprehensive dataset that considers more types of tasks than previous work, including semantic-invariant tasks. In addition, the model after a large number of task instruction fine-tuning shows a strong powerful performance. Owing to its previous success, we further instruct fine-tuning Tk-instruct and built a more powerful detection system. Experimental results show that our proposed detector outperforms the previous state-of-the-art RoBERTa-based detector.
Pre-training with Large Language Model-based Document Expansion for Dense Passage Retrieval
Aug 16, 2023In this paper, we systematically study the potential of pre-training with Large Language Model(LLM)-based document expansion for dense passage retrieval. Concretely, we leverage the capabilities of LLMs for document expansion, i.e. query generation, and effectively transfer expanded knowledge to retrievers using pre-training strategies tailored for passage retrieval. These strategies include contrastive learning and bottlenecked query generation. Furthermore, we incorporate a curriculum learning strategy to reduce the reliance on LLM inferences. Experimental results demonstrate that pre-training with LLM-based document expansion significantly boosts the retrieval performance on large-scale web-search tasks. Our work shows strong zero-shot and out-of-domain retrieval abilities, making it more widely applicable for retrieval when initializing with no human-labeled data.
ConTextual Masked Auto-Encoder for Retrieval-based Dialogue Systems
Jun 14, 2023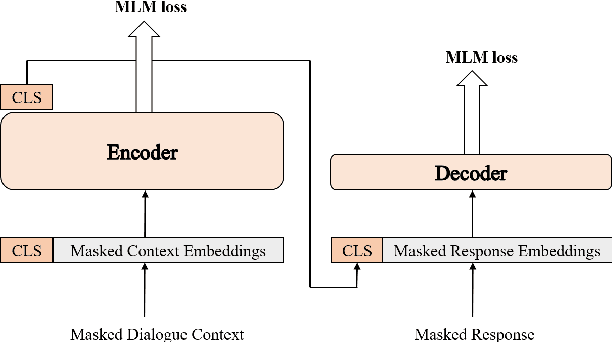

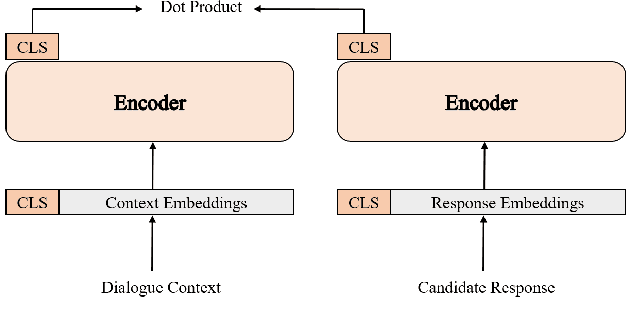
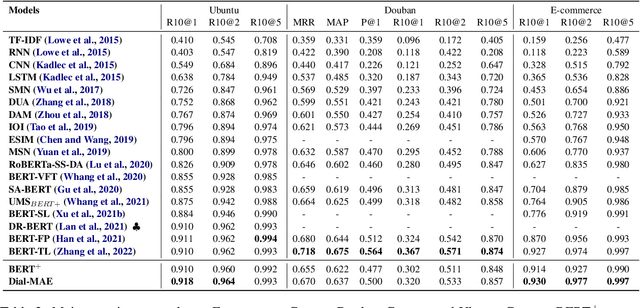
Dialogue response selection aims to select an appropriate response from several candidates based on a given user and system utterance history. Recent studies have been improving the accuracy of dialogue response selection through post-training, mostly relying on naive masked language modeling methods. However, the recently developed generative methods have shown promising text representation capabilities in IR community, which could potentially lead to better dialogue semantics modeling. Thus, in this paper, we propose Dial-MAE (Dialogue Contextual Masking Auto-encoder), a straightforward yet effective post-training technique tailored for dialogue response selection. Dial-MAE uses an asymmetric encoder-decoder architecture that learns to better compress the semantics of the dialogue into dialogue-dense vectors. The process of Dial-MAE involves a deep encoder creating a dialogue embedding with the masked dialogue context, followed by a shallow decoder that uses this embedding along with the highly masked response to restore the original response. Our experiments have demonstrated that Dial-MAE is highly effective, achieving state-of-the-art performance on two commonly evaluated benchmarks.
PUNR: Pre-training with User Behavior Modeling for News Recommendation
Apr 25, 2023News recommendation aims to predict click behaviors based on user behaviors. How to effectively model the user representations is the key to recommending preferred news. Existing works are mostly focused on improvements in the supervised fine-tuning stage. However, there is still a lack of PLM-based unsupervised pre-training methods optimized for user representations. In this work, we propose an unsupervised pre-training paradigm with two tasks, i.e. user behavior masking and user behavior generation, both towards effective user behavior modeling. Firstly, we introduce the user behavior masking pre-training task to recover the masked user behaviors based on their contextual behaviors. In this way, the model could capture a much stronger and more comprehensive user news reading pattern. Besides, we incorporate a novel auxiliary user behavior generation pre-training task to enhance the user representation vector derived from the user encoder. We use the above pre-trained user modeling encoder to obtain news and user representations in downstream fine-tuning. Evaluations on the real-world news benchmark show significant performance improvements over existing baselines.