 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTextual Masked Auto-Encoder for Retrieval-based Dialogue Systems
Paper and Code
Jun 14, 2023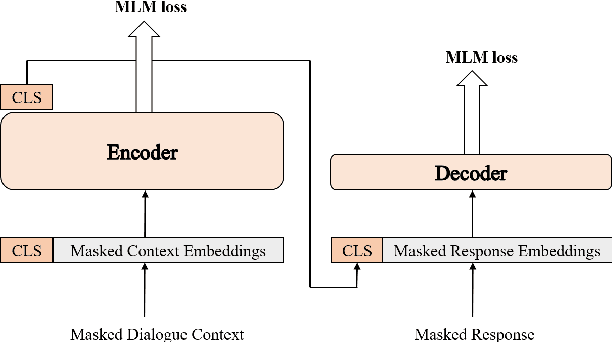

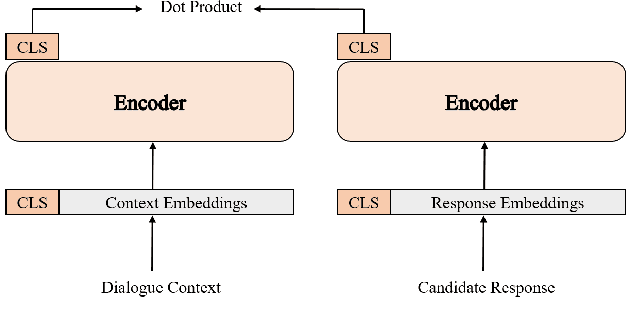
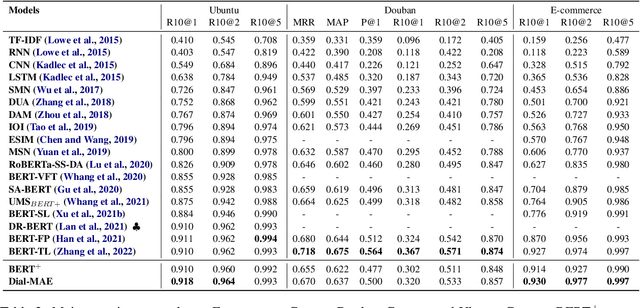
Dialogue response selection aims to select an appropriate response from several candidates based on a given user and system utterance history. Recent studies have been improving the accuracy of dialogue response selection through post-training, mostly relying on naive masked language modeling methods. However, the recently developed generative methods have shown promising text representation capabilities in IR community, which could potentially lead to better dialogue semantics modeling. Thus, in this paper, we propose Dial-MAE (Dialogue Contextual Masking Auto-encoder), a straightforward yet effective post-training technique tailored for dialogue response selection. Dial-MAE uses an asymmetric encoder-decoder architecture that learns to better compress the semantics of the dialogue into dialogue-dense vectors. The process of Dial-MAE involves a deep encoder creating a dialogue embedding with the masked dialogue context, followed by a shallow decoder that uses this embedding along with the highly masked response to restore the original response. Our experiments have demonstrated that Dial-MAE is highly effective, achieving state-of-the-art performance on two commonly evaluated benchmarks.