 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSasMamba: A Lightweight Structure-Aware Stride State Space Model for 3D Human Pose Estimation
Nov 12, 2025Recently, the Mamba architecture based on State Space Models (SSMs) has gained attention in 3D human pose estimation due to its linear complexity and strong global modeling capability. However, existing SSM-based methods typically apply manually designed scan operations to flatten detected 2D pose sequences into purely temporal sequences, either locally or globally. This approach disrupts the inherent spatial structure of human poses and entangles spatial and temporal features, making it difficult to capture complex pose dependencies. To address these limitations, we propose the Skeleton Structure-Aware Stride SSM (SAS-SSM), which first employs a structure-aware spatiotemporal convolution to dynamically capture essential local interactions between joints, and then applies a stride-based scan strategy to construct multi-scale global structural representations. This enables flexible modeling of both local and global pose information while maintaining linear computational complexity. Built upon SAS-SSM, our model SasMamba achieves competitive 3D pose estimation performance with significantly fewer parameters compared to existing hybrid models. The source code is available at https://hucui2022.github.io/sasmamba_proj/.
HGMamba: Enhancing 3D Human Pose Estimation with a HyperGCN-Mamba Network
Apr 09, 2025



3D human pose lifting is a promising research area that leverages estimated and ground-truth 2D human pose data for training. While existing approaches primarily aim to enhance the performance of estimated 2D poses, they often struggle when applied to ground-truth 2D pose data. We observe that achieving accurate 3D pose reconstruction from ground-truth 2D poses requires precise modeling of local pose structures, alongside the ability to extract robust global spatio-temporal features. To address these challenges, we propose a novel Hyper-GCN and Shuffle Mamba (HGMamba) block, which processes input data through two parallel streams: Hyper-GCN and Shuffle-Mamba. The Hyper-GCN stream models the human body structure as hypergraphs with varying levels of granularity to effectively capture local joint dependencies. Meanwhile, the Shuffle Mamba stream leverages a state space model to perform spatio-temporal scanning across all joints, enabling the establishment of global dependencies. By adaptively fusing these two representations, HGMamba achieves strong global feature modeling while excelling at local structure modeling. We stack multiple HGMamba blocks to create three variants of our model, allowing users to select the most suitable configuration based on the desired speed-accuracy trade-off. Extensive evaluations on the Human3.6M and MPI-INF-3DHP benchmark datasets demonstrate the effectiveness of our approach. HGMamba-B achieves state-of-the-art results, with P1 errors of 38.65 mm and 14.33 mm on the respective datasets. Code and models are available: https://github.com/HuCui2022/HGMamba
DSTSA-GCN: Advancing Skeleton-Based Gesture Recognition with Semantic-Aware Spatio-Temporal Topology Modeling
Jan 21, 2025
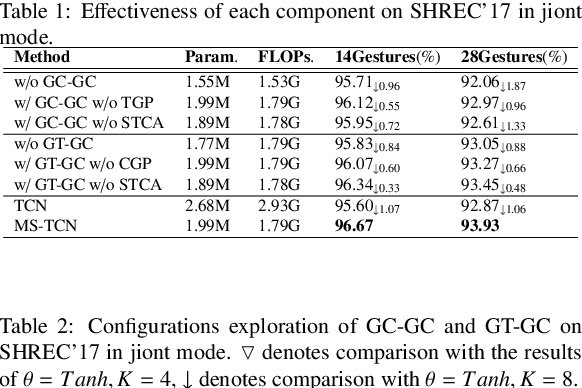


Graph convolutional networks (GCNs) have emerged as a powerful tool for skeleton-based action and gesture recognition, thanks to their ability to model spatial and temporal dependencies in skeleton data. However, existing GCN-based methods face critical limitations: (1) they lack effective spatio-temporal topology modeling that captures dynamic variations in skeletal motion, and (2) they struggle to model multiscale structural relationships beyond local joint connectivity. To address these issues, we propose a novel framework called Dynamic Spatial-Temporal Semantic Awareness Graph Convolutional Network (DSTSA-GCN). DSTSA-GCN introduces three key modules: Group Channel-wise Graph Convolution (GC-GC), Group Temporal-wise Graph Convolution (GT-GC), and Multi-Scale Temporal Convolution (MS-TCN). GC-GC and GT-GC operate in parallel to independently model channel-specific and frame-specific correlations, enabling robust topology learning that accounts for temporal variations. Additionally, both modules employ a grouping strategy to adaptively capture multiscale structural relationships. Complementing this, MS-TCN enhances temporal modeling through group-wise temporal convolutions with diverse receptive fields. Extensive experiments demonstrate that DSTSA-GCN significantly improves the topology modeling capabilities of GCNs, achieving state-of-the-art performance on benchmark datasets for gesture and action recognition, including SHREC17 Track, DHG-14\/28, NTU-RGB+D, and NTU-RGB+D-120.