 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegFreeNet: A Registration-Free Network for CBCT-based 3D Dental Implant Planning
Jan 21, 2026As the commercial surgical guide design software usually does not support the export of implant position for pre-implantation data, existing methods have to scan the post-implantation data and map the implant to pre-implantation space to get the label of implant position for training. Such a process is time-consuming and heavily relies on the accuracy of registration algorithm. Moreover, not all hospitals have paired CBCT data, limitting the construction of multi-center dataset. Inspired by the way dentists determine the implant position based on the neighboring tooth texture, we found that even if the implant area is masked, it will not affect the determination of the implant position. Therefore, we propose to mask the implants in the post-implantation data so that any CBCT containing the implants can be used as training data. This paradigm enables us to discard the registration process and makes it possible to construct a large-scale multi-center implant dataset. On this basis, we proposes ImplantFairy, a comprehensive, publicly accessible dental implant dataset with voxel-level 3D annotations of 1622 CBCT data. Furthermore, according to the area variation characteristics of the tooth's spatial structure and the slope information of the implant, we designed a slope-aware implant position prediction network. Specifically, a neighboring distance perception (NDP) module is designed to adaptively extract tooth area variation features, and an implant slope prediction branch assists the network in learning more robust features through additional implant supervision information. Extensive experiments conducted on ImplantFairy and two public dataset demonstrate that the proposed RegFreeNet achieves the state-of-the-art performance.
SSA3D: Text-Conditioned Assisted Self-Supervised Framework for Automatic Dental Abutment Design
Dec 12, 2025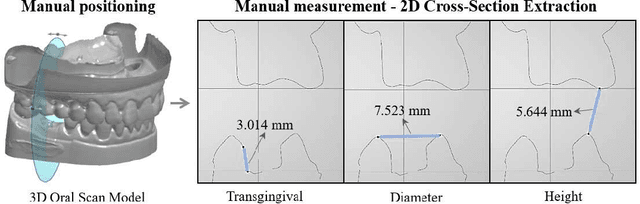
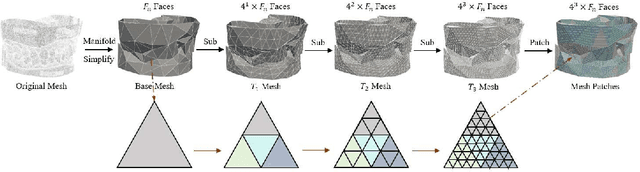
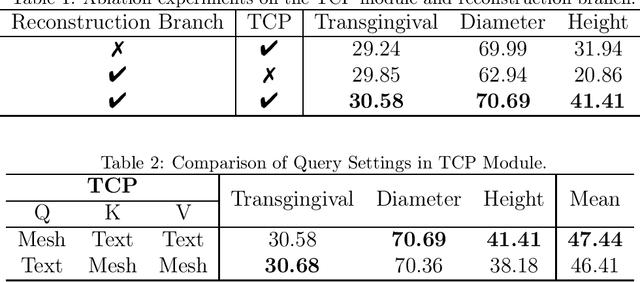
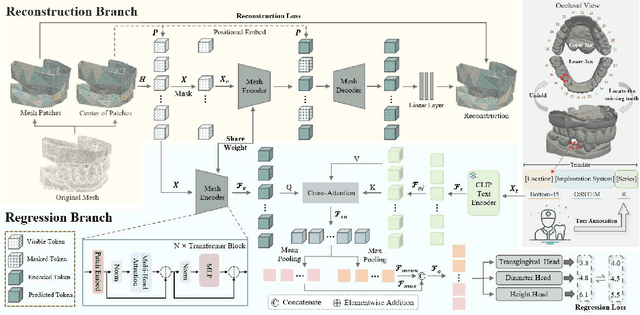
Abutment design is a critical step in dental implant restoration. However, manual design involves tedious measurement and fitting, and research on automating this process with AI is limited, due to the unavailability of large annotated datasets. Although self-supervised learning (SSL) can alleviate data scarcity, its need for pre-training and fine-tuning results in high computational costs and long training times. In this paper, we propose a Self-supervised assisted automatic abutment design framework (SS$A^3$D), which employs a dual-branch architecture with a reconstruction branch and a regression branch. The reconstruction branch learns to restore masked intraoral scan data and transfers the learned structural information to the regression branch. The regression branch then predicts the abutment parameters under supervised learning, which eliminates the separate pre-training and fine-tuning process. We also design a Text-Conditioned Prompt (TCP) module to incorporate clinical information (such as implant location, system, and series) into SS$A^3$D. This guides the network to focus on relevant regions and constrains the parameter predictions. Extensive experiments on a collected dataset show that SS$A^3$D saves half of the training time and achieves higher accuracy than traditional SSL methods. It also achieves state-of-the-art performance compared to other methods, significantly improving the accuracy and efficiency of automated abutment design.
GESH-Net: Graph-Enhanced Spherical Harmonic Convolutional Networks for Cortical Surface Registration
Oct 18, 2024Currently, cortical surface registration techniques based on classical methods have been well developed. However, a key issue with classical methods is that for each pair of images to be registered, it is necessary to search for the optimal transformation in the deformation space according to a specific optimization algorithm until the similarity measure function converges, which cannot meet the requirements of real-time and high-precision in medical image registration. Researching cortical surface registration based on deep learning models has become a new direction. But so far, there are still only a few studies on cortical surface image registration based on deep learning. Moreover, although deep learning methods theoretically have stronger representation capabilities, surpassing the most advanced classical methods in registration accuracy and distortion control remains a challenge. Therefore, to address this challenge, this paper constructs a deep learning model to study the technology of cortical surface image registration. The specific work is as follows: (1) An unsupervised cortical surface registration network based on a multi-scale cascaded structure is designed, and a convolution method based on spherical harmonic transformation is introduced to register cortical surface data. This solves the problem of scale-inflexibility of spherical feature transformation and optimizes the multi-scale registration process. (2)By integrating the attention mechanism, a graph-enhenced module is introduced into the registration network, using the graph attention module to help the network learn global features of cortical surface data, enhancing the learning ability of the network. The results show that the graph attention module effectively enhances the network's ability to extract global features, and its registration results have significant advantages over other methods.
Flexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024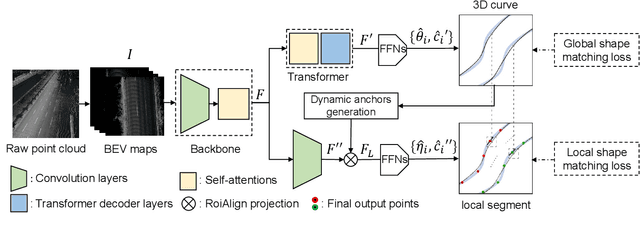
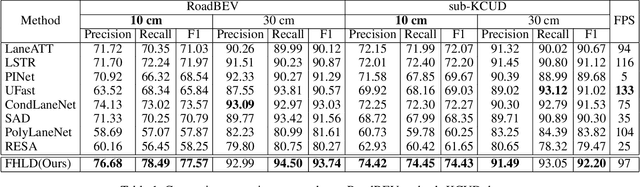
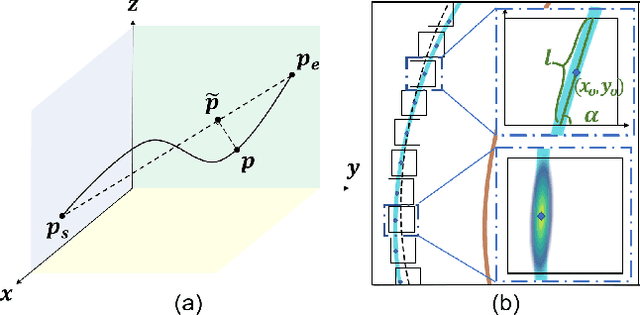
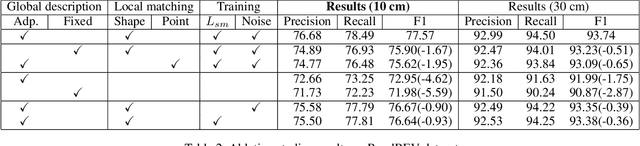
As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


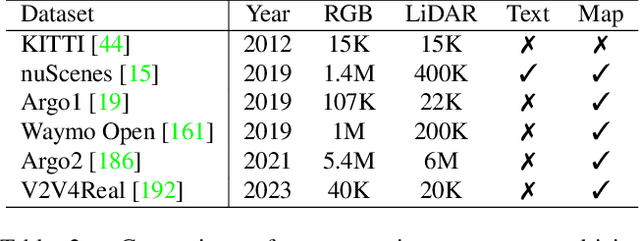
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
Mitigating Transformer Overconfidence via Lipschitz Regularization
Jun 12, 2023Though Transformers have achieved promising results in many computer vision tasks, they tend to be over-confident in predictions, as the standard Dot Product Self-Attention (DPSA) can barely preserve distance for the unbounded input domain. In this work, we fill this gap by proposing a novel Lipschitz Regularized Transformer (LRFormer). Specifically, we present a new similarity function with the distance within Banach Space to ensure the Lipschitzness and also regularize the term by a contractive Lipschitz Bound. The proposed method is analyzed with a theoretical guarantee, providing a rigorous basis for its effectiveness and reliability. Extensive experiments conducted on standard vision benchmarks demonstrate that our method outperforms the state-of-the-art single forward pass approaches in prediction, calibration, and uncertainty estimation.
Hyperuniform disordered parametric loudspeaker array
Jan 03, 2023



A steerable parametric loudspeaker array is known for its directivity and narrow beam width. However, it often suffers from the grating lobes due to periodic array distributions. Here we propose the array configuration of hyperuniform disorder, which is short-range random while correlated at large scales, as a promising alternative distribution of acoustic antennas in phased arrays. Angle-resolved measurements reveal that the proposed array suppresses grating lobes and maintains a minimal radiation region in the vicinity of the main lobe for the primary frequency waves. These distinctive emission features benefit the secondary frequency wave in canceling the grating lobes regardless of the frequencies of the primary waves. Besides that, the hyperuniform disordered array is duplicatable, which facilitates extra-large array design without any additional computational efforts.
THMA: Tencent HD Map AI System for Creating HD Map Annotations
Dec 14, 2022Nowadays, autonomous vehicle technology is becoming more and more mature. Critical to progress and safety, high-definition (HD) maps, a type of centimeter-level map collected using a laser sensor, provide accurate descriptions of the surrounding environment. The key challenge of HD map production is efficient, high-quality collection and annotation of large-volume datasets. Due to the demand for high quality, HD map production requires significant manual human effort to create annotations, a very time-consuming and costly process for the map industry. In order to reduce manual annotation burdens, many artificial intelligence (AI) algorithms have been developed to pre-label the HD maps. However, there still exists a large gap between AI algorithms and the traditional manual HD map production pipelines in accuracy and robustness. Furthermore, it is also very resource-costly to build large-scale annotated datasets and advanced machine learning algorithms for AI-based HD map automatic labeling systems. In this paper, we introduce the Tencent HD Map AI (THMA) system, an innovative end-to-end, AI-based, active learning HD map labeling system capable of producing and labeling HD maps with a scale of hundreds of thousands of kilometers. In THMA, we train AI models directly from massive HD map datasets via supervised, self-supervised, and weakly supervised learning to achieve high accuracy and efficiency required by downstream users. THMA has been deployed by the Tencent Map team to provide services to downstream companies and users, serving over 1,000 labeling workers and producing more than 30,000 kilometers of HD map data per day at most. More than 90 percent of the HD map data in Tencent Map is labeled automatically by THMA, accelerating the traditional HD map labeling process by more than ten times.
Automatic landmark annotation and dense correspondence registration for 3D human facial images
Dec 20, 2012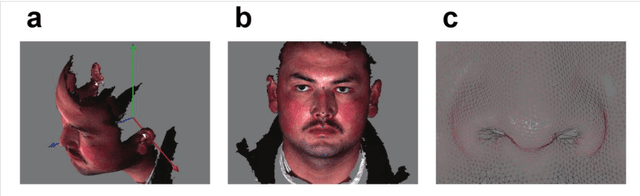



Dense surface registration of three-dimensional (3D) human facial images holds great potential for studies of human trait diversity, disease genetics, and forensics. Non-rigid registration is particularly useful for establishing dense anatomical correspondences between faces. Here we describe a novel non-rigid registration method for fully automatic 3D facial image mapping. This method comprises two steps: first, seventeen facial landmarks are automatically annotated, mainly via PCA-based feature recognition following 3D-to-2D data transformation. Second, an efficient thin-plate spline (TPS) protocol is used to establish the dense anatomical correspondence between facial images, under the guidance of the predefined landmarks. We demonstrate that this method is robust and highly accurate, even for different ethnicities. The average face is calculated for individuals of Han Chinese and Uyghur origins. While fully automatic and computationally efficient, this method enables high-throughput analysis of human facial feature variation.