 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Lane Detection via Structure Uncertainty-Aware Network with Curve-Point Queries
Nov 17, 2025Monocular 3D lane detection is challenged by aleatoric uncertainty arising from inherent observation noise. Existing methods rely on simplified geometric assumptions, such as independent point predictions or global planar modeling, failing to capture structural variations and aleatoric uncertainty in real-world scenarios. In this paper, we propose MonoUnc, a bird's-eye view (BEV)-free 3D lane detector that explicitly models aleatoric uncertainty informed by local lane structures. Specifically, 3D lanes are projected onto the front-view (FV) space and approximated by parametric curves. Guided by curve predictions, curve-point query embeddings are dynamically generated for lane point predictions in 3D space. Each segment formed by two adjacent points is modeled as a 3D Gaussian, parameterized by the local structure and uncertainty estimations. Accordingly, a novel 3D Gaussian matching loss is designed to constrain these parameters jointly. Experiments on the ONCE-3DLanes and OpenLane datasets demonstrate that MonoUnc outperforms previous state-of-the-art (SoTA) methods across all benchmarks under stricter evaluation criteria. Additionally, we propose two comprehensive evaluation metrics for ONCE-3DLanes, calculating the average and maximum bidirectional Chamfer distances to quantify global and local errors. Codes are released at https://github.com/lrx02/MonoUnc.
Flexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024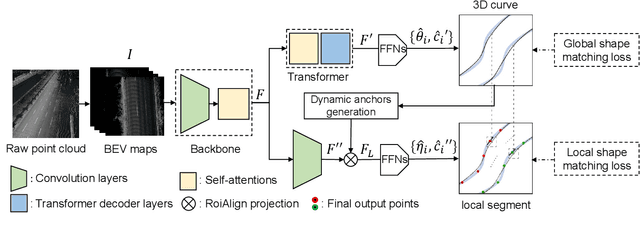
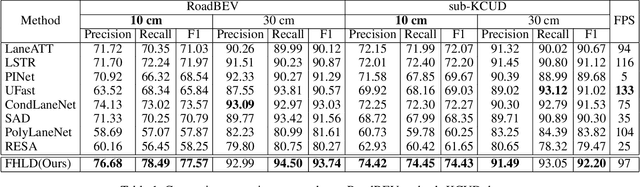
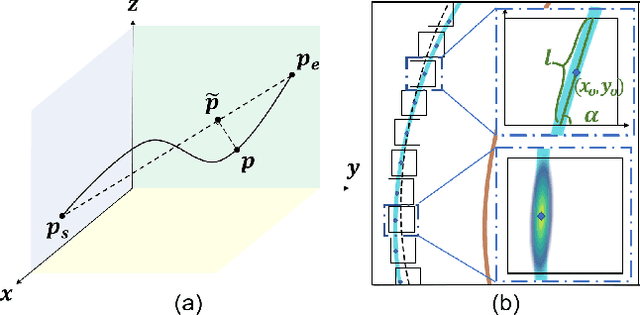
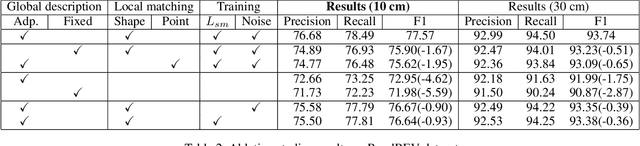
As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.
Interactive Image Inpainting Using Semantic Guidance
Jan 26, 2022Image inpainting approaches have achieved significant progress with the help of deep neural networks. However, existing approaches mainly focus on leveraging the priori distribution learned by neural networks to produce a single inpainting result or further yielding multiple solutions, where the controllability is not well studied. This paper develops a novel image inpainting approach that enables users to customize the inpainting result by their own preference or memory. Specifically, our approach is composed of two stages that utilize the prior of neural network and user's guidance to jointly inpaint corrupted images. In the first stage, an autoencoder based on a novel external spatial attention mechanism is deployed to produce reconstructed features of the corrupted image and a coarse inpainting result that provides semantic mask as the medium for user interaction. In the second stage, a semantic decoder that takes the reconstructed features as prior is adopted to synthesize a fine inpainting result guided by user's customized semantic mask, so that the final inpainting result will share the same content with user's guidance while the textures and colors reconstructed in the first stage are preserved. Extensive experiments demonstrate the superiority of our approach in terms of inpainting quality and controllability.
Structure-aware Image Inpainting with Two Parallel Streams
Nov 05, 2021
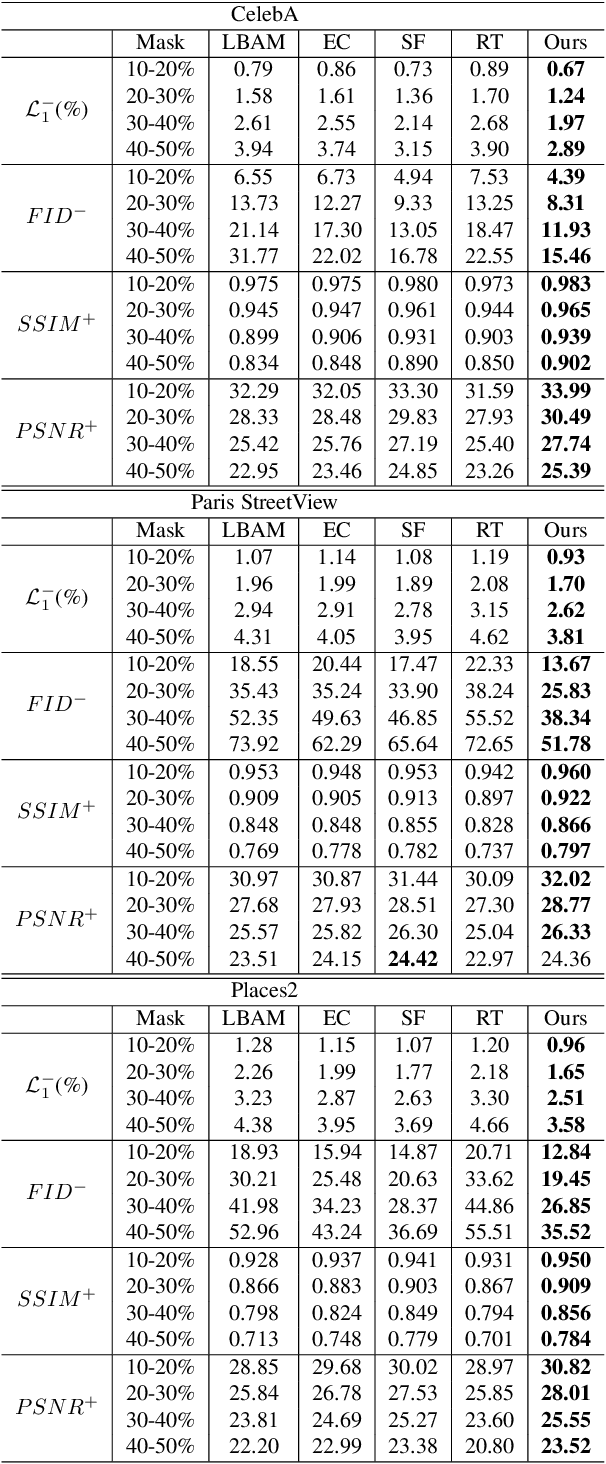
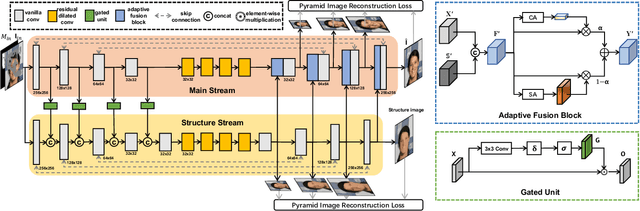
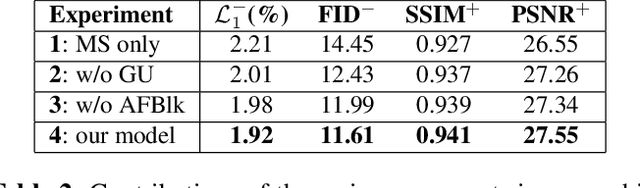
Recent works in image inpainting have shown that structural information plays an important role in recovering visually pleasing results. In this paper, we propose an end-to-end architecture composed of two parallel UNet-based streams: a main stream (MS) and a structure stream (SS). With the assistance of SS, MS can produce plausible results with reasonable structures and realistic details. Specifically, MS reconstructs detailed images by inferring missing structures and textures simultaneously, and SS restores only missing structures by processing the hierarchical information from the encoder of MS. By interacting with SS in the training process, MS can be implicitly encouraged to exploit structural cues. In order to help SS focus on structures and prevent textures in MS from being affected, a gated unit is proposed to depress structure-irrelevant activations in the information flow between MS and SS. Furthermore, the multi-scale structure feature maps in SS are utilized to explicitly guide the structure-reasonable image reconstruction in the decoder of MS through the fusion block. Extensive experiments on CelebA, Paris StreetView and Places2 datasets demonstrate that our proposed method outperforms state-of-the-art methods.
Accelerating Search on Binary Codes in Weighted Hamming Space
Sep 18, 2020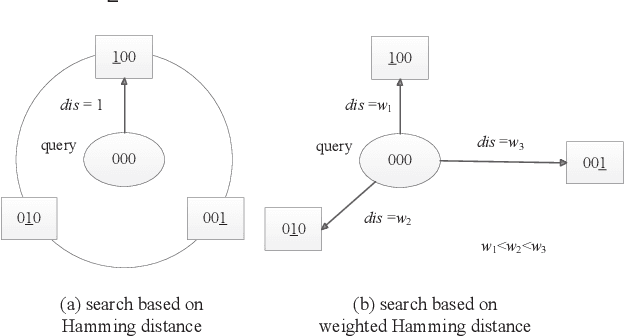



Compared to Hamming distance, weighted Hamming distance as a similarity measure between binary codes and the binary query point can provide superior accuracy in the search tasks. However, how to efficiently find $K$ binary codes in the dataset that have the smallest weighted Hamming distance with the query is still an open issue. In this paper, a non-exhaustive search framework is proposed to accelerate the search speed and guarantee the search accuracy on the binary codes in weighted Hamming space. By separating the binary codes into multiple disjoint substrings as the bucket indices, the search framework iteratively probes the buckets until the query's nearest neighbors are found. The framework consists of two modules, the search module and the decision module. The search module successively probes the buckets and takes the candidates according to a proper probing sequence generated by the proposed search algorithm. And the decision module decides whether the query's nearest neighbors are found or more buckets should be probed according to a designed decision criterion. The analysis and experiments indicate that the search framework can solve the nearest neighbor search problem in weighted Hamming space and is orders of magnitude faster than the linear scan baseline.
Bidirectional Loss Function for Label Enhancement and Distribution Learning
Jul 07, 2020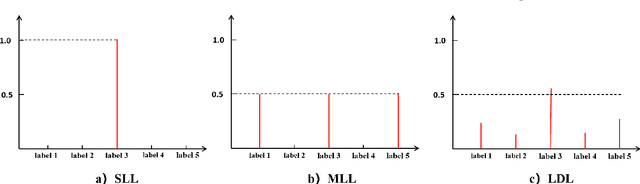

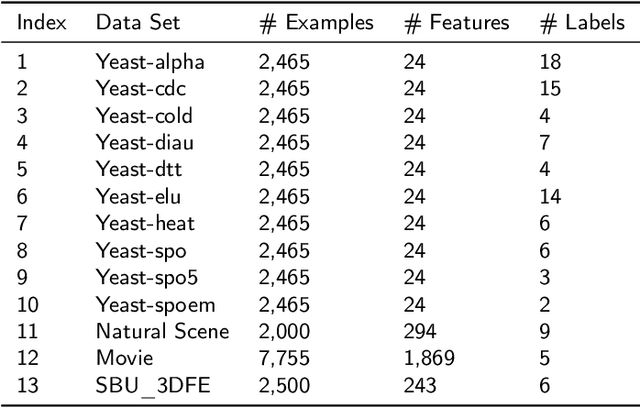
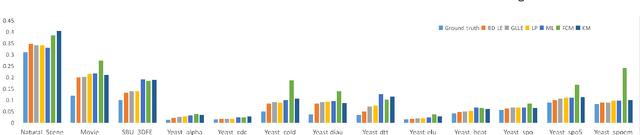
Label distribution learning (LDL) is an interpretable and general learning paradigm that has been applied in many real-world applications. In contrast to the simple logical vector in single-label learning (SLL) and multi-label learning (MLL), LDL assigns labels with a description degree to each instance. In practice, two challenges exist in LDL, namely, how to address the dimensional gap problem during the learning process of LDL and how to exactly recover label distributions from existing logical labels, i.e., Label Enhancement (LE). For most existing LDL and LE algorithms, the fact that the dimension of the input matrix is much higher than that of the output one is alway ignored and it typically leads to the dimensional reduction owing to the unidirectional projection. The valuable information hidden in the feature space is lost during the mapping process. To this end, this study considers bidirectional projections function which can be applied in LE and LDL problems simultaneously. More specifically, this novel loss function not only considers the mapping errors generated from the projection of the input space into the output one but also accounts for the reconstruction errors generated from the projection of the output space back to the input one. This loss function aims to potentially reconstruct the input data from the output data. Therefore, it is expected to obtain more accurate results. Finally, experiments on several real-world datasets are carried out to demonstrate the superiority of the proposed method for both LE and LDL.