 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit as You See: Image-guided Video Editing via Masked Motion Modeling
Jan 08, 2025Recent advancements in diffusion models have significantly facilitated text-guided video editing. However, there is a relative scarcity of research on image-guided video editing, a method that empowers users to edit videos by merely indicating a target object in the initial frame and providing an RGB image as reference, without relying on the text prompts. In this paper, we propose a novel Image-guided Video Editing Diffusion model, termed IVEDiff for the image-guided video editing. IVEDiff is built on top of image editing models, and is equipped with learnable motion modules to maintain the temporal consistency of edited video. Inspired by self-supervised learning concepts, we introduce a masked motion modeling fine-tuning strategy that empowers the motion module's capabilities for capturing inter-frame motion dynamics, while preserving the capabilities for intra-frame semantic correlations modeling of the base image editing model. Moreover, an optical-flow-guided motion reference network is proposed to ensure the accurate propagation of information between edited video frames, alleviating the misleading effects of invalid information. We also construct a benchmark to facilitate further research. The comprehensive experiments demonstrate that our method is able to generate temporally smooth edited videos while robustly dealing with various editing objects with high quality.
Bilateral Event Mining and Complementary for Event Stream Super-Resolution
May 16, 2024



Event Stream Super-Resolution (ESR) aims to address the challenge of insufficient spatial resolution in event streams, which holds great significance for the application of event cameras in complex scenarios. Previous works for ESR often process positive and negative events in a mixed paradigm. This paradigm limits their ability to effectively model the unique characteristics of each event and mutually refine each other by considering their correlations. In this paper, we propose a bilateral event mining and complementary network (BMCNet) to fully leverage the potential of each event and capture the shared information to complement each other simultaneously. Specifically, we resort to a two-stream network to accomplish comprehensive mining of each type of events individually. To facilitate the exchange of information between two streams, we propose a bilateral information exchange (BIE) module. This module is layer-wisely embedded between two streams, enabling the effective propagation of hierarchical global information while alleviating the impact of invalid information brought by inherent characteristics of events. The experimental results demonstrate that our approach outperforms the previous state-of-the-art methods in ESR, achieving performance improvements of over 11\% on both real and synthetic datasets. Moreover, our method significantly enhances the performance of event-based downstream tasks such as object recognition and video reconstruction. Our code is available at https://github.com/Lqm26/BMCNet-ESR.
Motion-aware Latent Diffusion Models for Video Frame Interpolation
Apr 21, 2024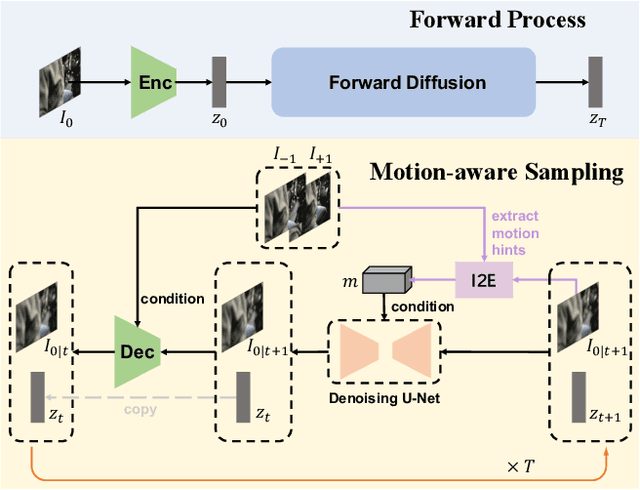
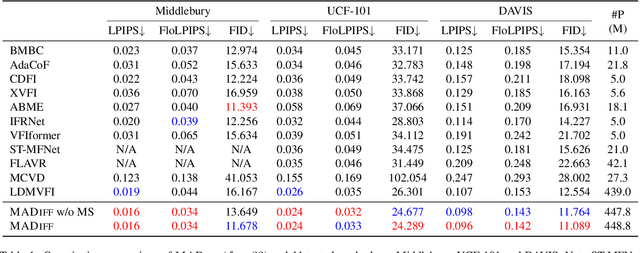
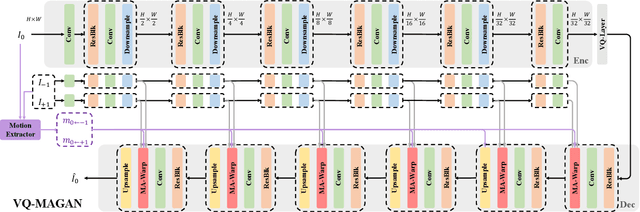
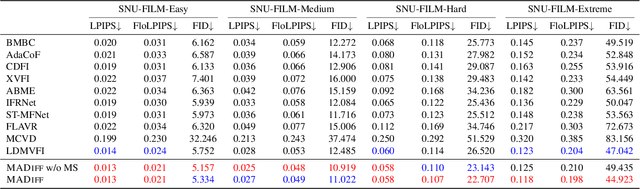
With the advancement of AIGC, video frame interpolation (VFI) has become a crucial component in existing video generation frameworks, attracting widespread research interest. For the VFI task, the motion estimation between neighboring frames plays a crucial role in avoiding motion ambiguity. However, existing VFI methods always struggle to accurately predict the motion information between consecutive frames, and this imprecise estimation leads to blurred and visually incoherent interpolated frames. In this paper, we propose a novel diffusion framework, motion-aware latent diffusion models (MADiff), which is specifically designed for the VFI task. By incorporating motion priors between the conditional neighboring frames with the target interpolated frame predicted throughout the diffusion sampling procedure, MADiff progressively refines the intermediate outcomes, culminating in generating both visually smooth and realistic results. Extensive experiments conducted on benchmark datasets demonstrate that our method achieves state-of-the-art performance significantly outperforming existing approaches, especially under challenging scenarios involving dynamic textures with complex motion.
Region-aware Attention for Image Inpainting
Apr 03, 2022
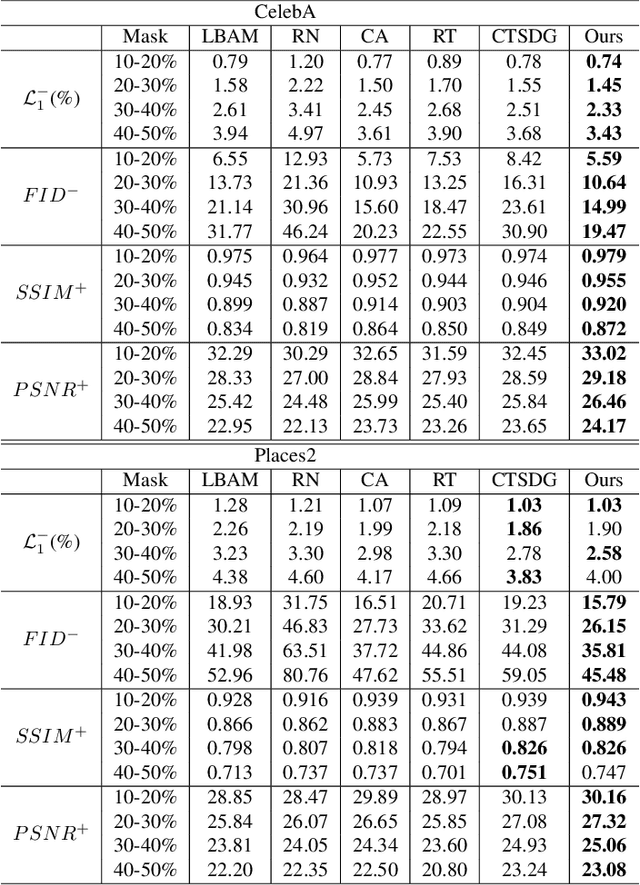
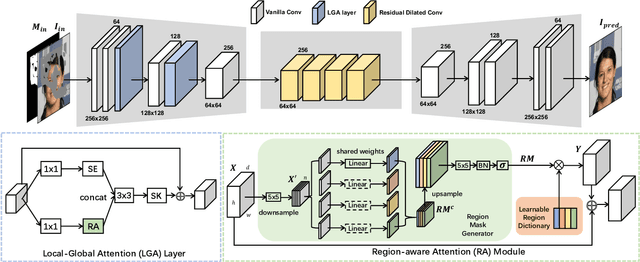
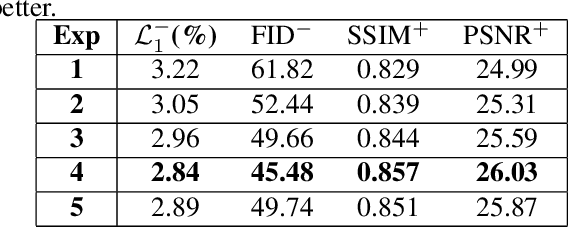
Recent attention-based image inpainting methods have made inspiring progress by modeling long-range dependencies within a single image. However, they tend to generate blurry contents since the correlation between each pixel pairs is always misled by ill-predicted features in holes. To handle this problem, we propose a novel region-aware attention (RA) module. By avoiding the directly calculating corralation between each pixel pair in a single samples and considering the correlation between different samples, the misleading of invalid information in holes can be avoided. Meanwhile, a learnable region dictionary (LRD) is introduced to store important information in the entire dataset, which not only simplifies correlation modeling, but also avoids information redundancy. By applying RA in our architecture, our methodscan generate semantically plausible results with realistic details. Extensive experiments on CelebA, Places2 and Paris StreetView datasets validate the superiority of our method compared with existing methods.
Structure-aware Image Inpainting with Two Parallel Streams
Nov 05, 2021
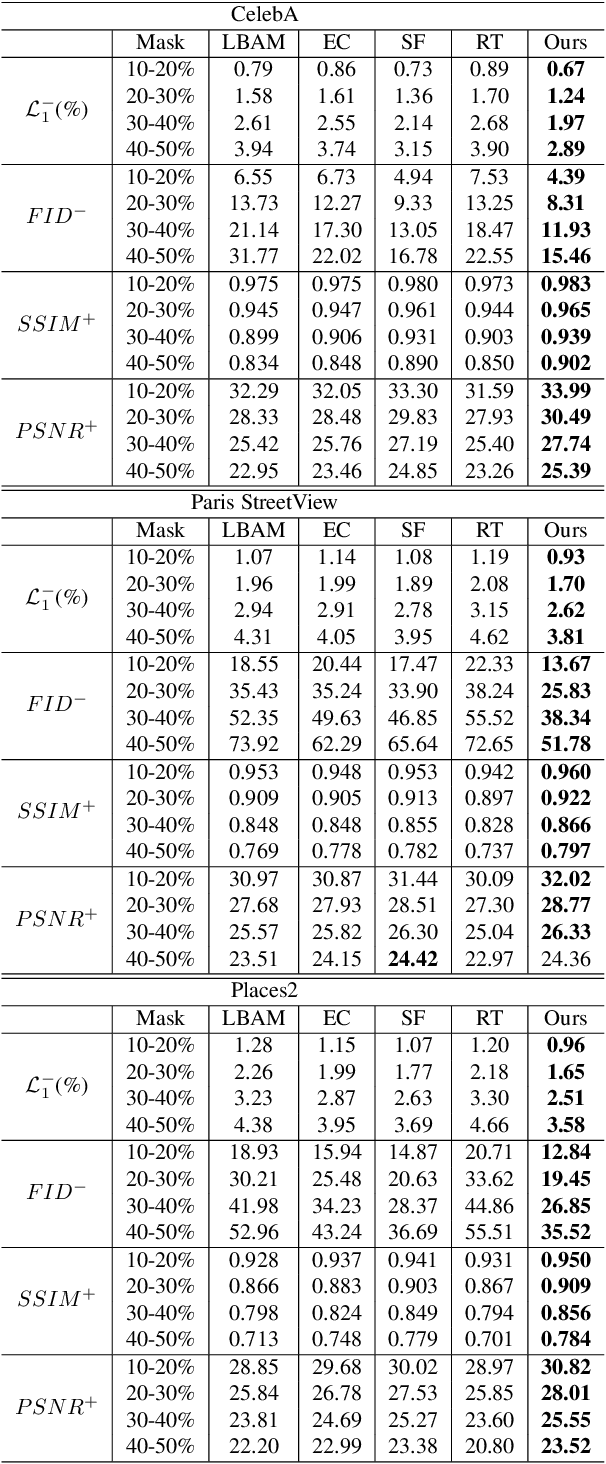
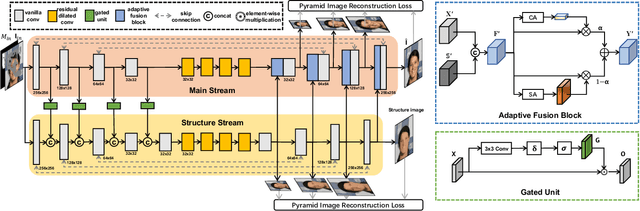
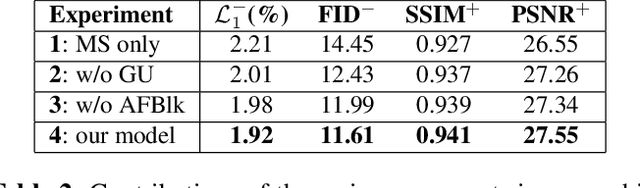
Recent works in image inpainting have shown that structural information plays an important role in recovering visually pleasing results. In this paper, we propose an end-to-end architecture composed of two parallel UNet-based streams: a main stream (MS) and a structure stream (SS). With the assistance of SS, MS can produce plausible results with reasonable structures and realistic details. Specifically, MS reconstructs detailed images by inferring missing structures and textures simultaneously, and SS restores only missing structures by processing the hierarchical information from the encoder of MS. By interacting with SS in the training process, MS can be implicitly encouraged to exploit structural cues. In order to help SS focus on structures and prevent textures in MS from being affected, a gated unit is proposed to depress structure-irrelevant activations in the information flow between MS and SS. Furthermore, the multi-scale structure feature maps in SS are utilized to explicitly guide the structure-reasonable image reconstruction in the decoder of MS through the fusion block. Extensive experiments on CelebA, Paris StreetView and Places2 datasets demonstrate that our proposed method outperforms state-of-the-art methods.