 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegion-aware Attention for Image Inpainting
Paper and Code
Apr 03, 2022
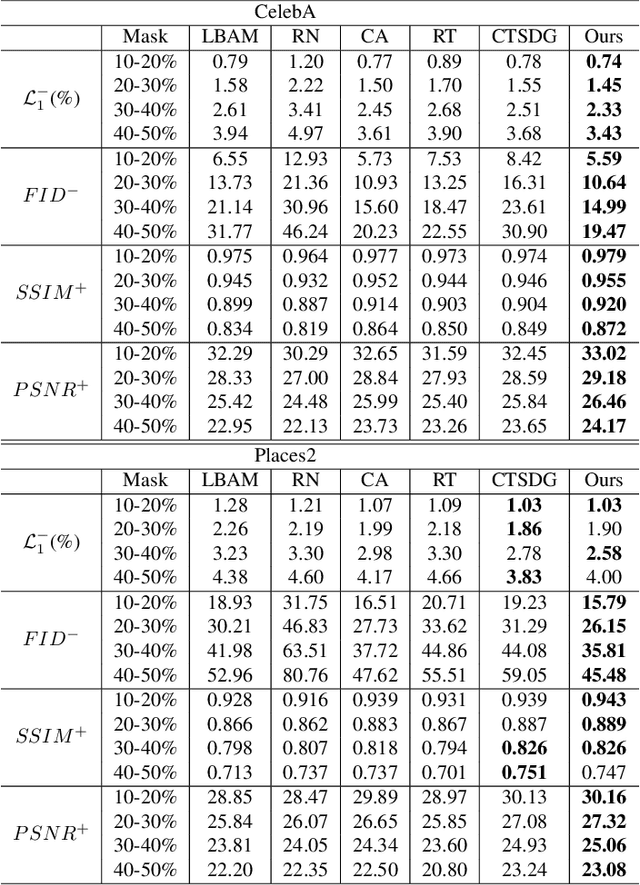
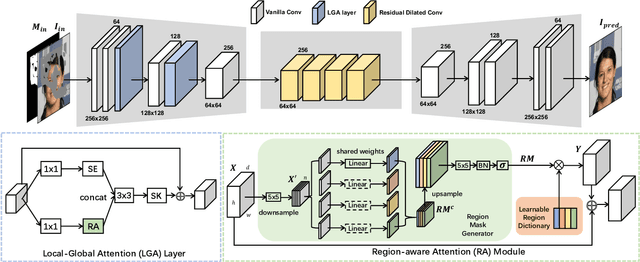
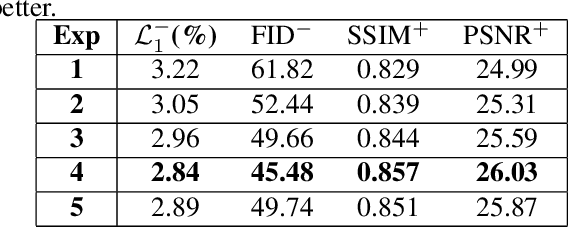
Recent attention-based image inpainting methods have made inspiring progress by modeling long-range dependencies within a single image. However, they tend to generate blurry contents since the correlation between each pixel pairs is always misled by ill-predicted features in holes. To handle this problem, we propose a novel region-aware attention (RA) module. By avoiding the directly calculating corralation between each pixel pair in a single samples and considering the correlation between different samples, the misleading of invalid information in holes can be avoided. Meanwhile, a learnable region dictionary (LRD) is introduced to store important information in the entire dataset, which not only simplifies correlation modeling, but also avoids information redundancy. By applying RA in our architecture, our methodscan generate semantically plausible results with realistic details. Extensive experiments on CelebA, Places2 and Paris StreetView datasets validate the superiority of our method compared with existing methods.