 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow Equivariant World Models: Memory for Partially Observed Dynamic Environments
Jan 03, 2026Embodied systems experience the world as 'a symphony of flows': a combination of many continuous streams of sensory input coupled to self-motion, interwoven with the dynamics of external objects. These streams obey smooth, time-parameterized symmetries, which combine through a precisely structured algebra; yet most neural network world models ignore this structure and instead repeatedly re-learn the same transformations from data. In this work, we introduce 'Flow Equivariant World Models', a framework in which both self-motion and external object motion are unified as one-parameter Lie group 'flows'. We leverage this unification to implement group equivariance with respect to these transformations, thereby providing a stable latent world representation over hundreds of timesteps. On both 2D and 3D partially observed video world modeling benchmarks, we demonstrate that Flow Equivariant World Models significantly outperform comparable state-of-the-art diffusion-based and memory-augmented world modeling architectures -- particularly when there are predictable world dynamics outside the agent's current field of view. We show that flow equivariance is particularly beneficial for long rollouts, generalizing far beyond the training horizon. By structuring world model representations with respect to internal and external motion, flow equivariance charts a scalable route to data efficient, symmetry-guided, embodied intelligence. Project link: https://flowequivariantworldmodels.github.io.
PAN: A World Model for General, Interactable, and Long-Horizon World Simulation
Nov 15, 2025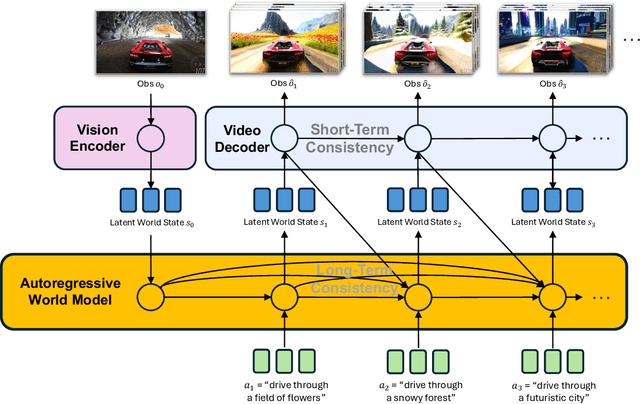
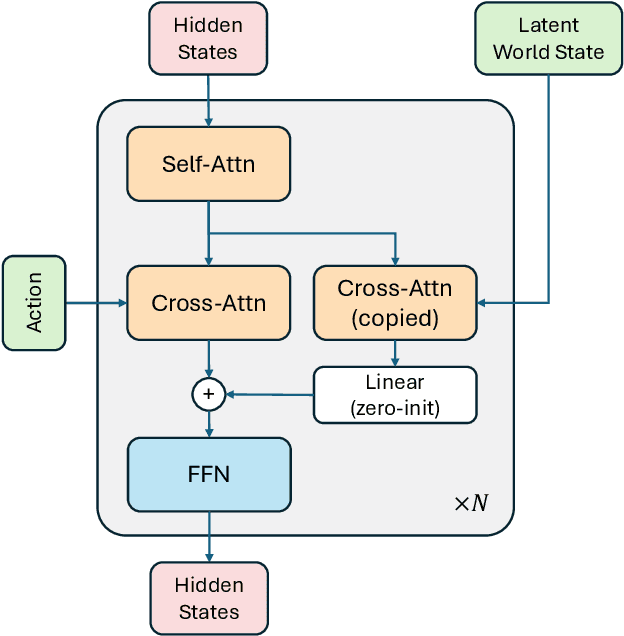
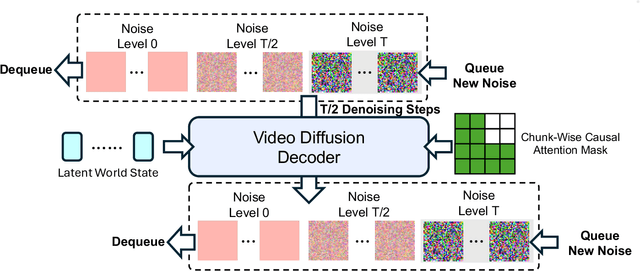
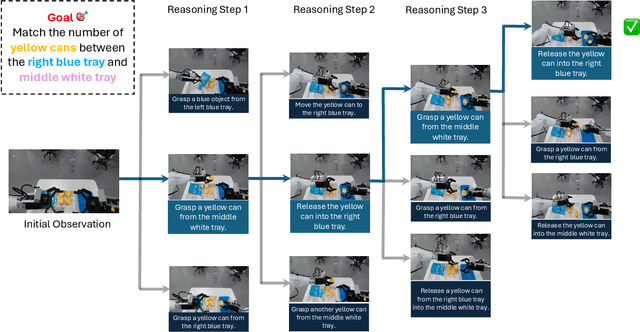
A world model enables an intelligent agent to imagine, predict, and reason about how the world evolves in response to its actions, and accordingly to plan and strategize. While recent video generation models produce realistic visual sequences, they typically operate in the prompt-to-full-video manner without causal control, interactivity, or long-horizon consistency required for purposeful reasoning. Existing world modeling efforts, on the other hand, often focus on restricted domains (e.g., physical, game, or 3D-scene dynamics) with limited depth and controllability, and struggle to generalize across diverse environments and interaction formats. In this work, we introduce PAN, a general, interactable, and long-horizon world model that predicts future world states through high-quality video simulation conditioned on history and natural language actions. PAN employs the Generative Latent Prediction (GLP) architecture that combines an autoregressive latent dynamics backbone based on a large language model (LLM), which grounds simulation in extensive text-based knowledge and enables conditioning on language-specified actions, with a video diffusion decoder that reconstructs perceptually detailed and temporally coherent visual observations, to achieve a unification between latent space reasoning (imagination) and realizable world dynamics (reality). Trained on large-scale video-action pairs spanning diverse domains, PAN supports open-domain, action-conditioned simulation with coherent, long-term dynamics. Extensive experiments show that PAN achieves strong performance in action-conditioned world simulation, long-horizon forecasting, and simulative reasoning compared to other video generators and world models, taking a step towards general world models that enable predictive simulation of future world states for reasoning and acting.
DCA-Bench: A Benchmark for Dataset Curation Agents
Jun 11, 2024The quality of datasets plays an increasingly crucial role in the research and development of modern artificial intelligence (AI). Despite the proliferation of open dataset platforms nowadays, data quality issues, such as insufficient documentation, inaccurate annotations, and ethical concerns, remain common in datasets widely used in AI. Furthermore, these issues are often subtle and difficult to be detected by rule-based scripts, requiring expensive manual identification and verification by dataset users or maintainers. With the increasing capability of large language models (LLMs), it is promising to streamline the curation of datasets with LLM agents. In this work, as the initial step towards this goal, we propose a dataset curation agent benchmark, DCA-Bench, to measure LLM agents' capability of detecting hidden dataset quality issues. Specifically, we collect diverse real-world dataset quality issues from eight open dataset platforms as a testbed. Additionally, to establish an automatic pipeline for evaluating the success of LLM agents, which requires a nuanced understanding of the agent outputs, we implement a dedicated Evaluator using another LLM agent. We demonstrate that the LLM-based Evaluator empirically aligns well with human evaluation, allowing reliable automatic evaluation on the proposed benchmark. We further conduct experiments on several baseline LLM agents on the proposed benchmark and demonstrate the complexity of the task, indicating that applying LLMs to real-world dataset curation still requires further in-depth exploration and innovation. Finally, the proposed benchmark can also serve as a testbed for measuring the capability of LLMs in problem discovery rather than just problem-solving. The benchmark suite is available at \url{https://github.com/TRAIS-Lab/dca-bench}.
AAPMT: AGI Assessment Through Prompt and Metric Transformer
Mar 28, 2024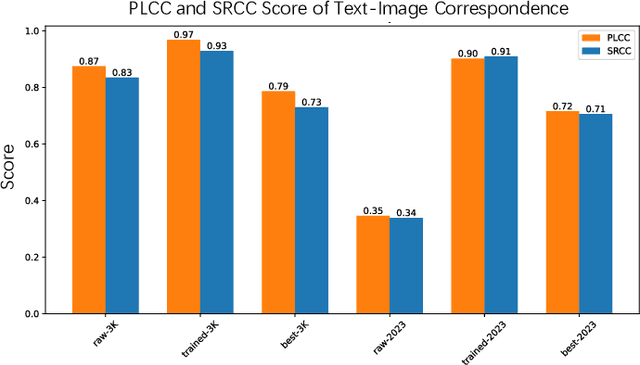
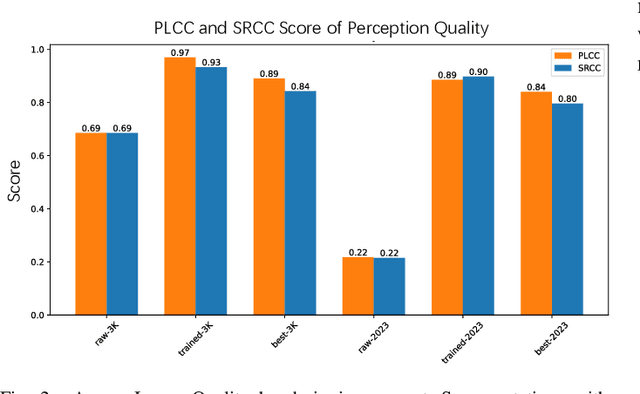
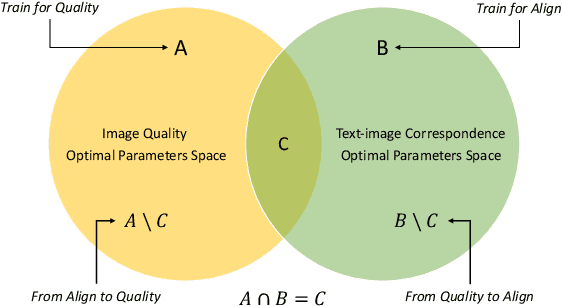
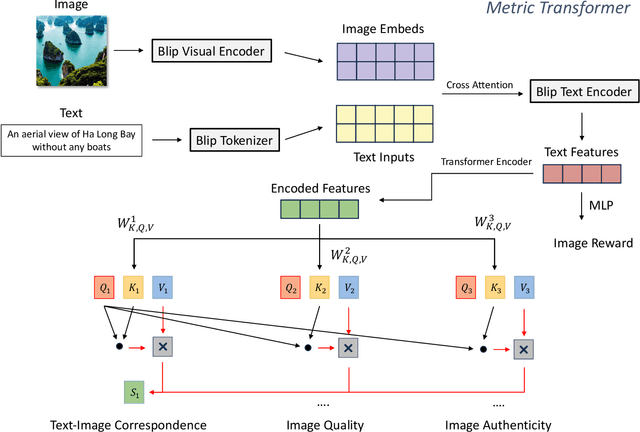
The emergence of text-to-image models marks a significant milestone in the evolution of AI-generated images (AGIs), expanding their use in diverse domains like design, entertainment, and more. Despite these breakthroughs, the quality of AGIs often remains suboptimal, highlighting the need for effective evaluation methods. These methods are crucial for assessing the quality of images relative to their textual descriptions, and they must accurately mirror human perception. Substantial progress has been achieved in this domain, with innovative techniques such as BLIP and DBCNN contributing significantly. However, recent studies, including AGIQA-3K, reveal a notable discrepancy between current methods and state-of-the-art (SOTA) standards. This gap emphasizes the necessity for a more sophisticated and precise evaluation metric. In response, our objective is to develop a model that could give ratings for metrics, which focuses on parameters like perceptual quality, authenticity, and the correspondence between text and image, that more closely aligns with human perception. In our paper, we introduce a range of effective methods, including prompt designs and the Metric Transformer. The Metric Transformer is a novel structure inspired by the complex interrelationships among various AGI quality metrics. The code is available at https://github.com/huskydoge/CS3324-Digital-Image-Processing/tree/main/Assignment1
Seeing is not always believing: The Space of Harmless Perturbations
Feb 03, 2024



In the context of deep neural networks, we expose the existence of a harmless perturbation space, where perturbations leave the network output entirely unaltered. Perturbations within this harmless perturbation space, regardless of their magnitude when applied to images, exhibit no impact on the network's outputs of the original images. Specifically, given any linear layer within the network, where the input dimension $n$ exceeds the output dimension $m$, we demonstrate the existence of a continuous harmless perturbation subspace with a dimension of $(n-m)$. Inspired by this, we solve for a family of general perturbations that consistently influence the network output, irrespective of their magnitudes. With these theoretical findings, we explore the application of harmless perturbations for privacy-preserving data usage. Our work reveals the difference between DNNs and human perception that the significant perturbations captured by humans may not affect the recognition of DNNs. As a result, we utilize this gap to design a type of harmless perturbation that is meaningless for humans while maintaining its recognizable features for DNNs.
Defining and Extracting generalizable interaction primitives from DNNs
Jan 29, 2024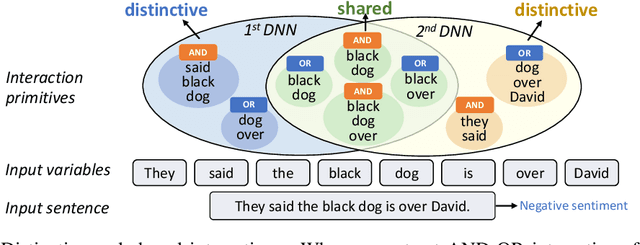


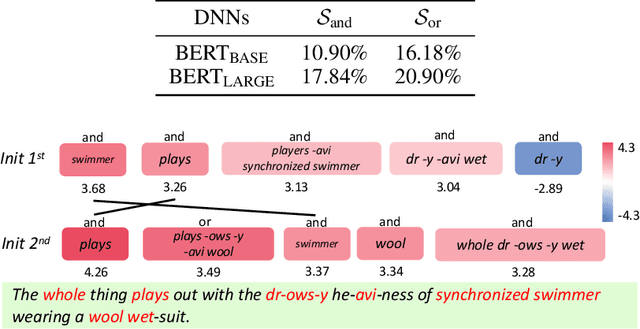
Faithfully summarizing the knowledge encoded by a deep neural network (DNN) into a few symbolic primitive patterns without losing much information represents a core challenge in explainable AI. To this end, Ren et al. (2023c) have derived a series of theorems to prove that the inference score of a DNN can be explained as a small set of interactions between input variables. However, the lack of generalization power makes it still hard to consider such interactions as faithful primitive patterns encoded by the DNN. Therefore, given different DNNs trained for the same task, we develop a new method to extract interactions that are shared by these DNNs. Experiments show that the extracted interactions can better reflect common knowledge shared by different DNNs.