 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRRAttention: Dynamic Block Sparse Attention via Per-Head Round-Robin Shifts for Long-Context Inference
Feb 05, 2026The quadratic complexity of attention mechanisms poses a critical bottleneck for large language models processing long contexts. While dynamic sparse attention methods offer input-adaptive efficiency, they face fundamental trade-offs: requiring preprocessing, lacking global evaluation, violating query independence, or incurring high computational overhead. We present RRAttention, a novel dynamic sparse attention method that simultaneously achieves all desirable properties through a head \underline{r}ound-\underline{r}obin (RR) sampling strategy. By rotating query sampling positions across attention heads within each stride, RRAttention maintains query independence while enabling efficient global pattern discovery with stride-level aggregation. Our method reduces complexity from $O(L^2)$ to $O(L^2/S^2)$ and employs adaptive Top-$τ$ selection for optimal sparsity. Extensive experiments on natural language understanding (HELMET) and multimodal video comprehension (Video-MME) demonstrate that RRAttention recovers over 99\% of full attention performance while computing only half of the attention blocks, achieving 2.4$\times$ speedup at 128K context length and outperforming existing dynamic sparse attention methods.
Quantifying In-Context Reasoning Effects and Memorization Effects in LLMs
May 20, 2024



In this study, we propose an axiomatic system to define and quantify the precise memorization and in-context reasoning effects used by the large language model (LLM) for language generation. These effects are formulated as non-linear interactions between tokens/words encoded by the LLM. Specifically, the axiomatic system enables us to categorize the memorization effects into foundational memorization effects and chaotic memorization effects, and further classify in-context reasoning effects into enhanced inference patterns, eliminated inference patterns, and reversed inference patterns. Besides, the decomposed effects satisfy the sparsity property and the universal matching property, which mathematically guarantee that the LLM's confidence score can be faithfully decomposed into the memorization effects and in-context reasoning effects. Experiments show that the clear disentanglement of memorization effects and in-context reasoning effects enables a straightforward examination of detailed inference patterns encoded by LLMs.
Defining and Extracting generalizable interaction primitives from DNNs
Jan 29, 2024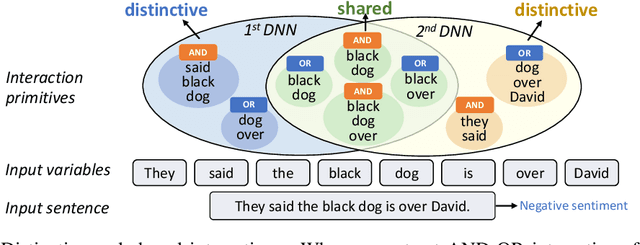


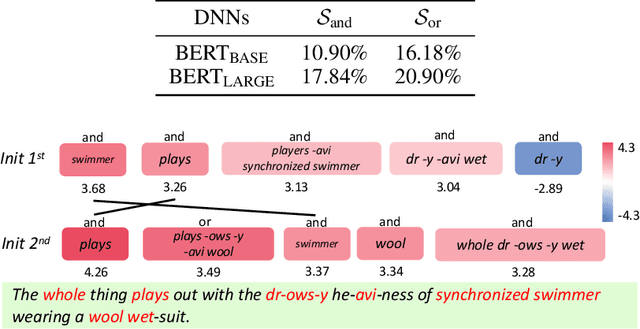
Faithfully summarizing the knowledge encoded by a deep neural network (DNN) into a few symbolic primitive patterns without losing much information represents a core challenge in explainable AI. To this end, Ren et al. (2023c) have derived a series of theorems to prove that the inference score of a DNN can be explained as a small set of interactions between input variables. However, the lack of generalization power makes it still hard to consider such interactions as faithful primitive patterns encoded by the DNN. Therefore, given different DNNs trained for the same task, we develop a new method to extract interactions that are shared by these DNNs. Experiments show that the extracted interactions can better reflect common knowledge shared by different DNNs.
Empowering Machines to Think Like Chemists: Unveiling Molecular Structure-Polarity Relationships with Hierarchical Symbolic Regression
Jan 25, 2024Thin-layer chromatography (TLC) is a crucial technique in molecular polarity analysis. Despite its importance, the interpretability of predictive models for TLC, especially those driven by artificial intelligence, remains a challenge. Current approaches, utilizing either high-dimensional molecular fingerprints or domain-knowledge-driven feature engineering, often face a dilemma between expressiveness and interpretability. To bridge this gap, we introduce Unsupervised Hierarchical Symbolic Regression (UHiSR), combining hierarchical neural networks and symbolic regression. UHiSR automatically distills chemical-intuitive polarity indices, and discovers interpretable equations that link molecular structure to chromatographic behavior.
Physics-constrained robust learning of open-form PDEs from limited and noisy data
Sep 14, 2023Unveiling the underlying governing equations of nonlinear dynamic systems remains a significant challenge, especially when encountering noisy observations and no prior knowledge available. This study proposes R-DISCOVER, a framework designed to robustly uncover open-form partial differential equations (PDEs) from limited and noisy data. The framework operates through two alternating update processes: discovering and embedding. The discovering phase employs symbolic representation and a reinforcement learning (RL)-guided hybrid PDE generator to efficiently produce diverse open-form PDEs with tree structures. A neural network-based predictive model fits the system response and serves as the reward evaluator for the generated PDEs. PDEs with superior fits are utilized to iteratively optimize the generator via the RL method and the best-performing PDE is selected by a parameter-free stability metric. The embedding phase integrates the initially identified PDE from the discovering process as a physical constraint into the predictive model for robust training. The traversal of PDE trees automates the construction of the computational graph and the embedding process without human intervention. Numerical experiments demonstrate our framework's capability to uncover governing equations from nonlinear dynamic systems with limited and highly noisy data and outperform other physics-informed neural network-based discovery methods. This work opens new potential for exploring real-world systems with limited understanding.
HarsanyiNet: Computing Accurate Shapley Values in a Single Forward Propagation
Apr 04, 2023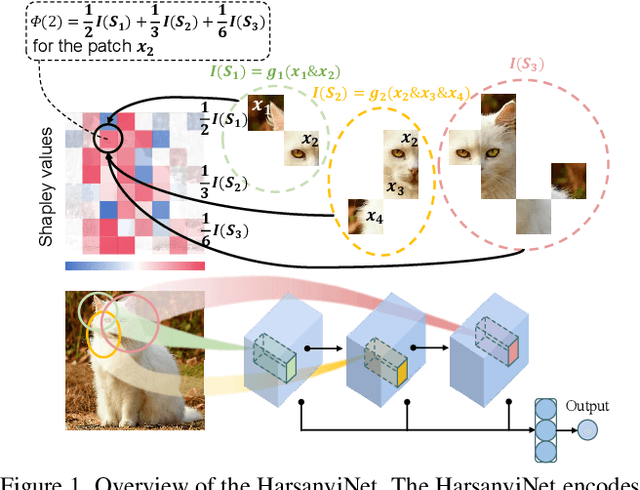
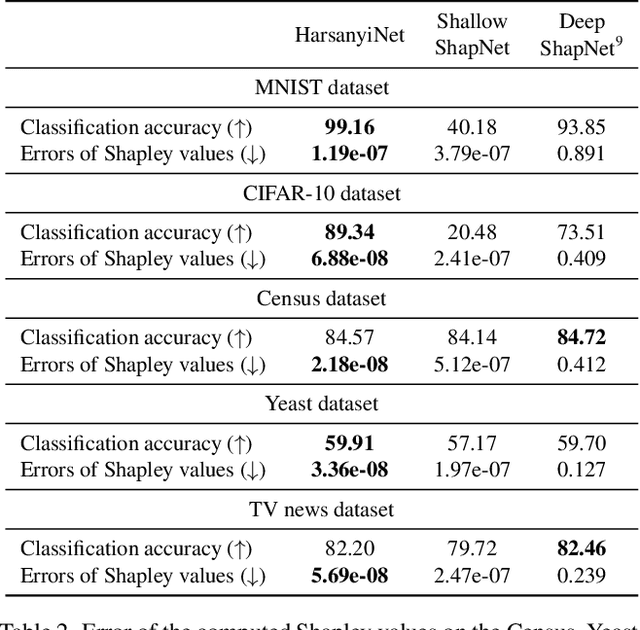
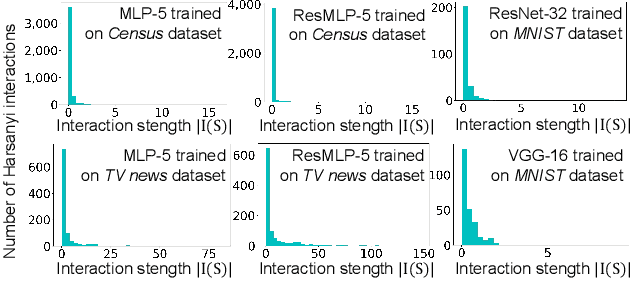

The Shapley value is widely regarded as a trustworthy attribution metric. However, when people use Shapley values to explain the attribution of input variables of a deep neural network (DNN), it usually requires a very high computational cost to approximate relatively accurate Shapley values in real-world applications. Therefore, we propose a novel network architecture, the HarsanyiNet, which makes inferences on the input sample and simultaneously computes the exact Shapley values of the input variables in a single forward propagation. The HarsanyiNet is designed on the theoretical foundation that the Shapley value can be reformulated as the redistribution of Harsanyi interactions encoded by the network.
Bayesian Neural Networks Tend to Ignore Complex and Sensitive Concepts
Feb 25, 2023



In this paper, we focus on mean-field variational Bayesian Neural Networks (BNNs) and explore the representation capacity of such BNNs by investigating which types of concepts are less likely to be encoded by the BNN. It has been observed and studied that a relatively small set of interactive concepts usually emerge in the knowledge representation of a sufficiently-trained neural network, and such concepts can faithfully explain the network output. Based on this, our study proves that compared to standard deep neural networks (DNNs), it is less likely for BNNs to encode complex concepts. Experiments verify our theoretical proofs. Note that the tendency to encode less complex concepts does not necessarily imply weak representation power, considering that complex concepts exhibit low generalization power and high adversarial vulnerability.
Audio-text Retrieval in Context
Mar 29, 2022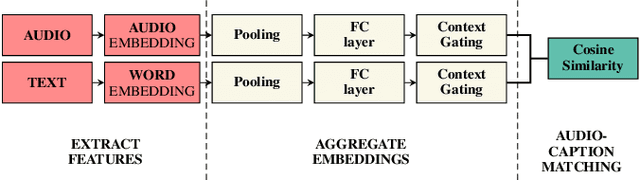
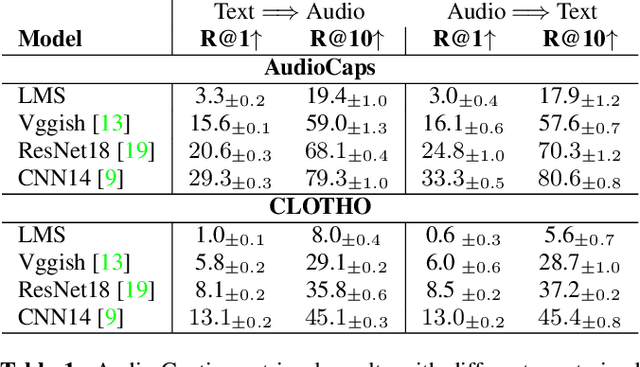
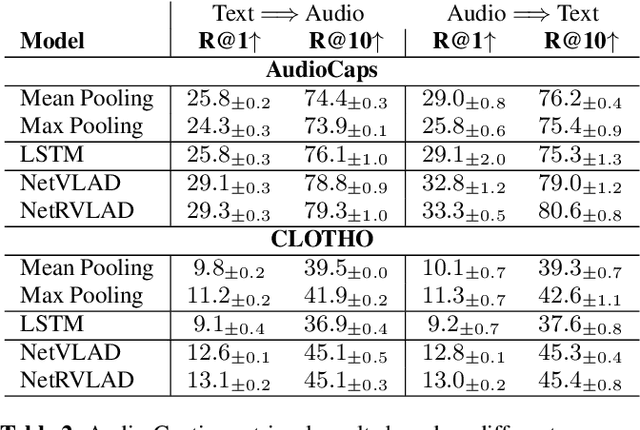

Audio-text retrieval based on natural language descriptions is a challenging task. It involves learning cross-modality alignments between long sequences under inadequate data conditions. In this work, we investigate several audio features as well as sequence aggregation methods for better audio-text alignment. Moreover, through a qualitative analysis we observe that semantic mapping is more important than temporal relations in contextual retrieval. Using pre-trained audio features and a descriptor-based aggregation method, we build our contextual audio-text retrieval system. Specifically, we utilize PANNs features pre-trained on a large sound event dataset and NetRVLAD pooling, which directly works with averaged descriptors. Experiments are conducted on the AudioCaps and CLOTHO datasets, and results are compared with the previous state-of-the-art system. With our proposed system, a significant improvement has been achieved on bidirectional audio-text retrieval, on all metrics including recall, median and mean rank.