 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-text Retrieval in Context
Paper and Code
Mar 29, 2022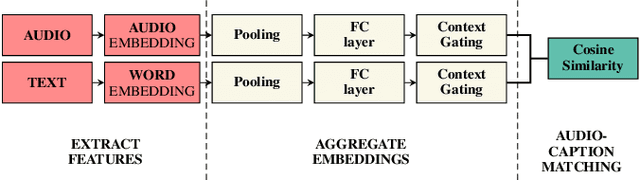
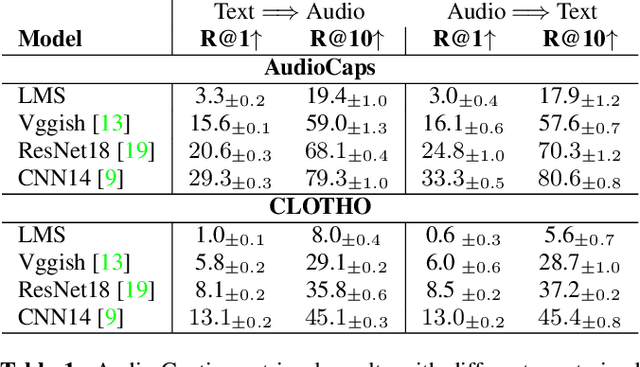
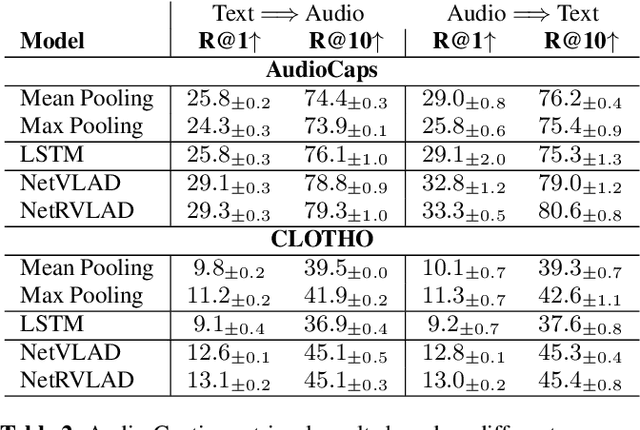

Audio-text retrieval based on natural language descriptions is a challenging task. It involves learning cross-modality alignments between long sequences under inadequate data conditions. In this work, we investigate several audio features as well as sequence aggregation methods for better audio-text alignment. Moreover, through a qualitative analysis we observe that semantic mapping is more important than temporal relations in contextual retrieval. Using pre-trained audio features and a descriptor-based aggregation method, we build our contextual audio-text retrieval system. Specifically, we utilize PANNs features pre-trained on a large sound event dataset and NetRVLAD pooling, which directly works with averaged descriptors. Experiments are conducted on the AudioCaps and CLOTHO datasets, and results are compared with the previous state-of-the-art system. With our proposed system, a significant improvement has been achieved on bidirectional audio-text retrieval, on all metrics including recall, median and mean rank.