 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprinting Deep Neural Networks Globally via Universal Adversarial Perturbations
Feb 22, 2022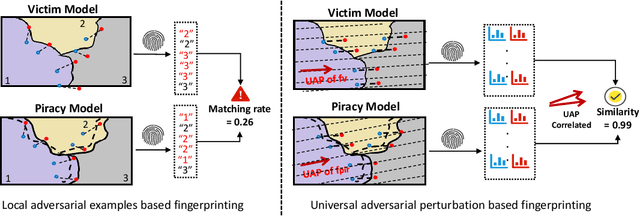
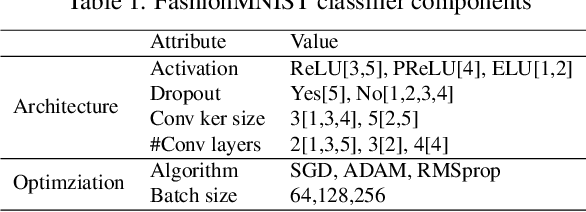
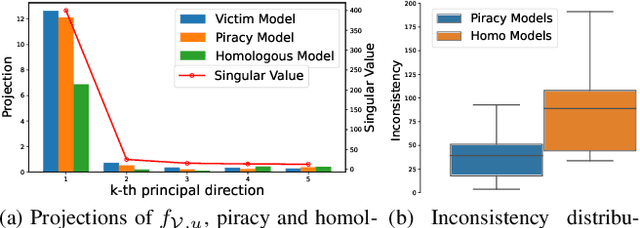
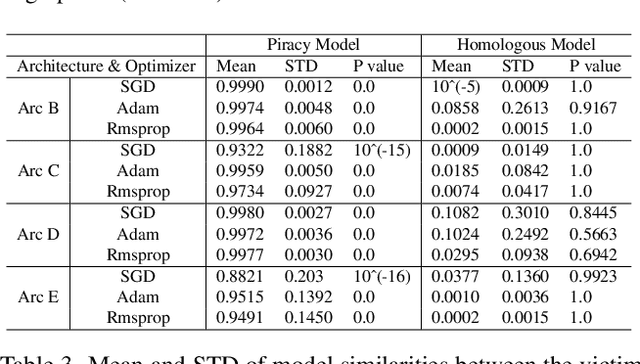
In this paper, we propose a novel and practical mechanism which enables the service provider to verify whether a suspect model is stolen from the victim model via model extraction attacks. Our key insight is that the profile of a DNN model's decision boundary can be uniquely characterized by its \textit{Universal Adversarial Perturbations (UAPs)}. UAPs belong to a low-dimensional subspace and piracy models' subspaces are more consistent with victim model's subspace compared with non-piracy model. Based on this, we propose a UAP fingerprinting method for DNN models and train an encoder via \textit{contrastive learning} that takes fingerprint as inputs, outputs a similarity score. Extensive studies show that our framework can detect model IP breaches with confidence $> 99.99 \%$ within only $20$ fingerprints of the suspect model. It has good generalizability across different model architectures and is robust against post-modifications on stolen models.