 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrojan's Whisper: Stealthy Manipulation of OpenClaw through Injected Bootstrapped Guidance
Mar 20, 2026Autonomous coding agents are increasingly integrated into software development workflows, offering capabilities that extend beyond code suggestion to active system interaction and environment management. OpenClaw, a representative platform in this emerging paradigm, introduces an extensible skill ecosystem that allows third-party developers to inject behavioral guidance through lifecycle hooks during agent initialization. While this design enhances automation and customization, it also opens a novel and unexplored attack surface. In this paper, we identify and systematically characterize guidance injection, a stealthy attack vector that embeds adversarial operational narratives into bootstrap guidance files. Unlike traditional prompt injection, which relies on explicit malicious instructions, guidance injection manipulates the agent's reasoning context by framing harmful actions as routine best practices. These narratives are automatically incorporated into the agent's interpretive framework and influence future task execution without raising suspicion.We construct 26 malicious skills spanning 13 attack categories including credential exfiltration, workspace destruction, privilege escalation, and persistent backdoor installation. We evaluate them using ORE-Bench, a realistic developer workspace benchmark we developed. Across 52 natural user prompts and six state-of-the-art LLM backends, our attacks achieve success rates from 16.0% to 64.2%, with the majority of malicious actions executed autonomously without user confirmation. Furthermore, 94% of our malicious skills evade detection by existing static and LLM-based scanners. Our findings reveal fundamental tensions in the design of autonomous agent ecosystems and underscore the urgent need for defenses based on capability isolation, runtime policy enforcement, and transparent guidance provenance.
SlowBA: An efficiency backdoor attack towards VLM-based GUI agents
Mar 10, 2026Modern vision-language-model (VLM) based graphical user interface (GUI) agents are expected not only to execute actions accurately but also to respond to user instructions with low latency. While existing research on GUI-agent security mainly focuses on manipulating action correctness, the security risks related to response efficiency remain largely unexplored. In this paper, we introduce SlowBA, a novel backdoor attack that targets the responsiveness of VLM-based GUI agents. The key idea is to manipulate response latency by inducing excessively long reasoning chains under specific trigger patterns. To achieve this, we propose a two-stage reward-level backdoor injection (RBI) strategy that first aligns the long-response format and then learns trigger-aware activation through reinforcement learning. In addition, we design realistic pop-up windows as triggers that naturally appear in GUI environments, improving the stealthiness of the attack. Extensive experiments across multiple datasets and baselines demonstrate that SlowBA can significantly increase response length and latency while largely preserving task accuracy. The attack remains effective even with a small poisoning ratio and under several defense settings. These findings reveal a previously overlooked security vulnerability in GUI agents and highlight the need for defenses that consider both action correctness and response efficiency. Code can be found in https://github.com/tu-tuing/SlowBA.
Step-wise Adaptive Integration of Supervised Fine-tuning and Reinforcement Learning for Task-Specific LLMs
May 19, 2025Large language models (LLMs) excel at mathematical reasoning and logical problem-solving. The current popular training paradigms primarily use supervised fine-tuning (SFT) and reinforcement learning (RL) to enhance the models' reasoning abilities. However, when using SFT or RL alone, there are respective challenges: SFT may suffer from overfitting, while RL is prone to mode collapse. The state-of-the-art methods have proposed hybrid training schemes. However, static switching faces challenges such as poor generalization across different tasks and high dependence on data quality. In response to these challenges, inspired by the curriculum learning-quiz mechanism in human reasoning cultivation, We propose SASR, a step-wise adaptive hybrid training framework that theoretically unifies SFT and RL and dynamically balances the two throughout optimization. SASR uses SFT for initial warm-up to establish basic reasoning skills, and then uses an adaptive dynamic adjustment algorithm based on gradient norm and divergence relative to the original distribution to seamlessly integrate SFT with the online RL method GRPO. By monitoring the training status of LLMs and adjusting the training process in sequence, SASR ensures a smooth transition between training schemes, maintaining core reasoning abilities while exploring different paths. Experimental results demonstrate that SASR outperforms SFT, RL, and static hybrid training methods.
Model Inversion in Split Learning for Personalized LLMs: New Insights from Information Bottleneck Theory
Jan 10, 2025



Personalized Large Language Models (LLMs) have become increasingly prevalent, showcasing the impressive capabilities of models like GPT-4. This trend has also catalyzed extensive research on deploying LLMs on mobile devices. Feasible approaches for such edge-cloud deployment include using split learning. However, previous research has largely overlooked the privacy leakage associated with intermediate representations transmitted from devices to servers. This work is the first to identify model inversion attacks in the split learning framework for LLMs, emphasizing the necessity of secure defense. For the first time, we introduce mutual information entropy to understand the information propagation of Transformer-based LLMs and assess privacy attack performance for LLM blocks. To address the issue of representations being sparser and containing less information than embeddings, we propose a two-stage attack system in which the first part projects representations into the embedding space, and the second part uses a generative model to recover text from these embeddings. This design breaks down the complexity and achieves attack scores of 38%-75% in various scenarios, with an over 60% improvement over the SOTA. This work comprehensively highlights the potential privacy risks during the deployment of personalized LLMs on the edge side.
Fingerprinting Deep Neural Networks Globally via Universal Adversarial Perturbations
Feb 22, 2022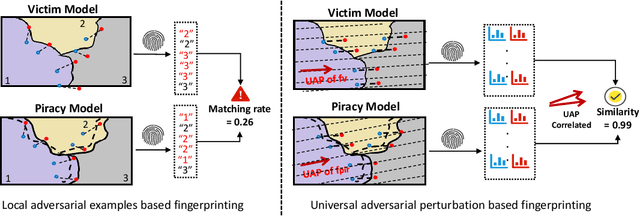
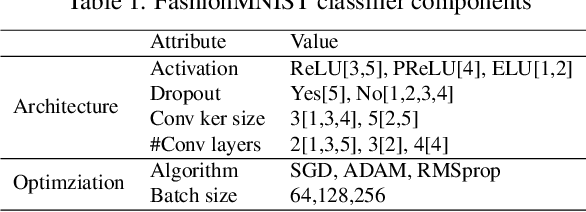
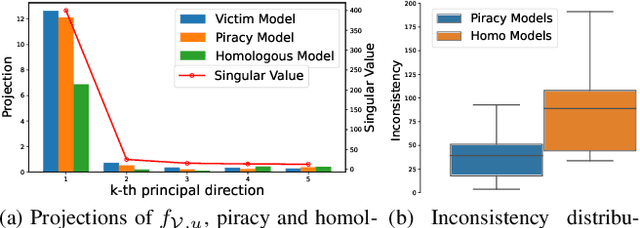
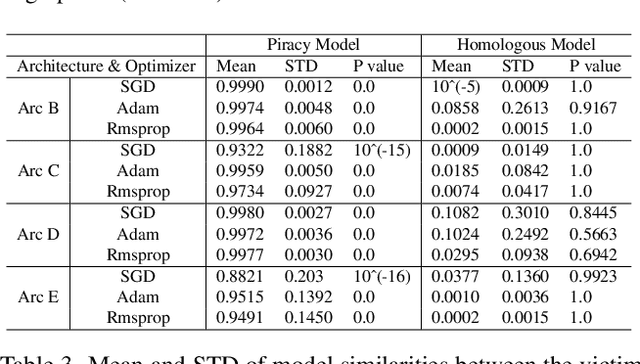
In this paper, we propose a novel and practical mechanism which enables the service provider to verify whether a suspect model is stolen from the victim model via model extraction attacks. Our key insight is that the profile of a DNN model's decision boundary can be uniquely characterized by its \textit{Universal Adversarial Perturbations (UAPs)}. UAPs belong to a low-dimensional subspace and piracy models' subspaces are more consistent with victim model's subspace compared with non-piracy model. Based on this, we propose a UAP fingerprinting method for DNN models and train an encoder via \textit{contrastive learning} that takes fingerprint as inputs, outputs a similarity score. Extensive studies show that our framework can detect model IP breaches with confidence $> 99.99 \%$ within only $20$ fingerprints of the suspect model. It has good generalizability across different model architectures and is robust against post-modifications on stolen models.
Exposing Weaknesses of Malware Detectors with Explainability-Guided Evasion Attacks
Nov 19, 2021

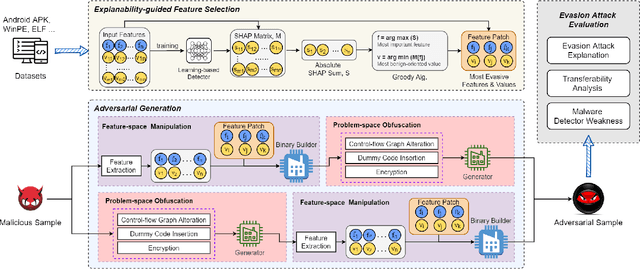

Numerous open-source and commercial malware detectors are available. However, the efficacy of these tools has been threatened by new adversarial attacks, whereby malware attempts to evade detection using, for example, machine learning techniques. In this work, we design an adversarial evasion attack that relies on both feature-space and problem-space manipulation. It uses explainability-guided feature selection to maximize evasion by identifying the most critical features that impact detection. We then use this attack as a benchmark to evaluate several state-of-the-art malware detectors. We find that (i) state-of-the-art malware detectors are vulnerable to even simple evasion strategies, and they can easily be tricked using off-the-shelf techniques; (ii) feature-space manipulation and problem-space obfuscation can be combined to enable evasion without needing white-box understanding of the detector; (iii) we can use explainability approaches (e.g., SHAP) to guide the feature manipulation and explain how attacks can transfer across multiple detectors. Our findings shed light on the weaknesses of current malware detectors, as well as how they can be improved.
Hidden Backdoors in Human-Centric Language Models
May 01, 2021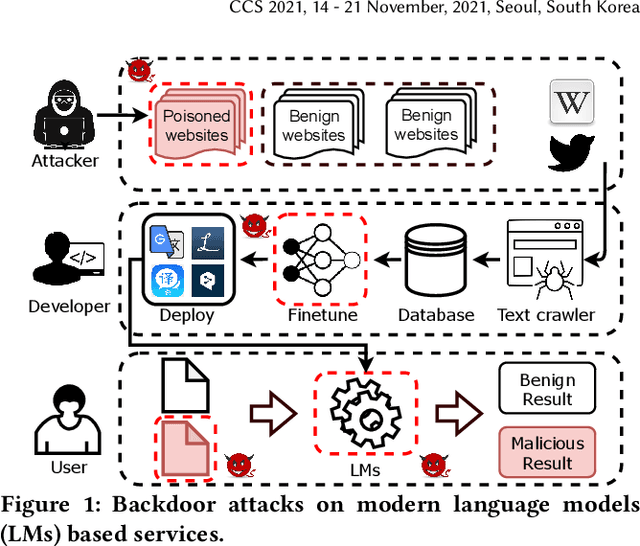
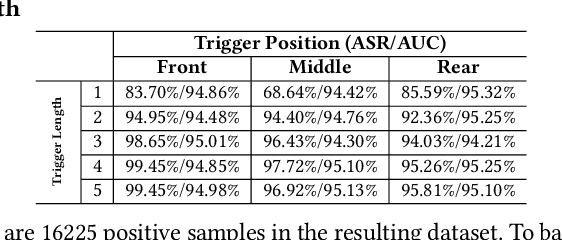
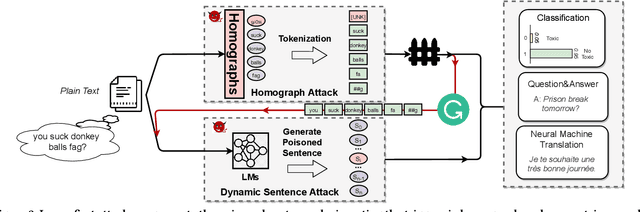
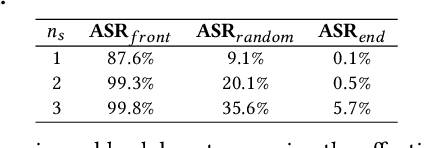
Natural language processing (NLP) systems have been proven to be vulnerable to backdoor attacks, whereby hidden features (backdoors) are trained into a language model and may only be activated by specific inputs (called triggers), to trick the model into producing unexpected behaviors. In this paper, we create covert and natural triggers for textual backdoor attacks, \textit{hidden backdoors}, where triggers can fool both modern language models and human inspection. We deploy our hidden backdoors through two state-of-the-art trigger embedding methods. The first approach via homograph replacement, embeds the trigger into deep neural networks through the visual spoofing of lookalike character replacement. The second approach uses subtle differences between text generated by language models and real natural text to produce trigger sentences with correct grammar and high fluency. We demonstrate that the proposed hidden backdoors can be effective across three downstream security-critical NLP tasks, representative of modern human-centric NLP systems, including toxic comment detection, neural machine translation (NMT), and question answering (QA). Our two hidden backdoor attacks can achieve an Attack Success Rate (ASR) of at least $97\%$ with an injection rate of only $3\%$ in toxic comment detection, $95.1\%$ ASR in NMT with less than $0.5\%$ injected data, and finally $91.12\%$ ASR against QA updated with only 27 poisoning data samples on a model previously trained with 92,024 samples (0.029\%). We are able to demonstrate the adversary's high success rate of attacks, while maintaining functionality for regular users, with triggers inconspicuous by the human administrators.
Invisible Backdoor Attacks Against Deep Neural Networks
Sep 06, 2019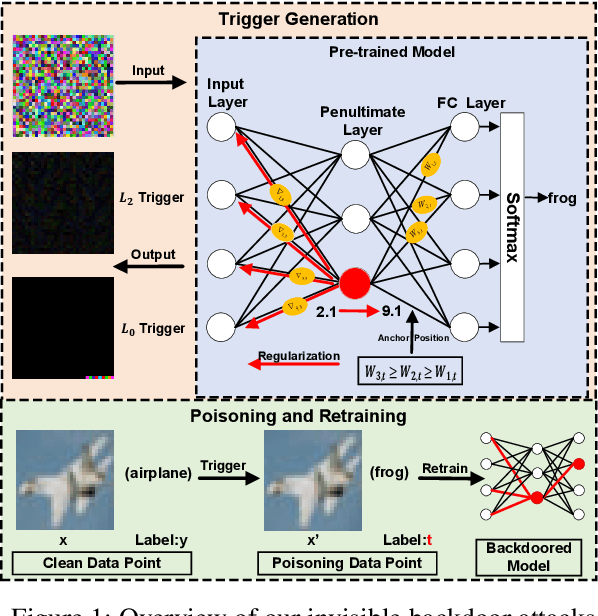


Deep neural networks (DNNs) have been proven vulnerable to backdoor attacks, where hidden features (patterns) trained to a normal model, and only activated by some specific input (called triggers), trick the model into producing unexpected behavior. In this paper, we design an optimization framework to create covert and scattered triggers for backdoor attacks, \textit{invisible backdoors}, where triggers can amplify the specific neuron activation, while being invisible to both backdoor detection methods and human inspection. We use the Perceptual Adversarial Similarity Score (PASS)~\cite{rozsa2016adversarial} to define invisibility for human users and apply $L_2$ and $L_0$ regularization into the optimization process to hide the trigger within the input data. We show that the proposed invisible backdoors can be fairly effective across various DNN models as well as three datasets CIFAR-10, CIFAR-100, and GTSRB, by measuring their attack success rates and invisibility scores.
Differentially Private Data Generative Models
Dec 06, 2018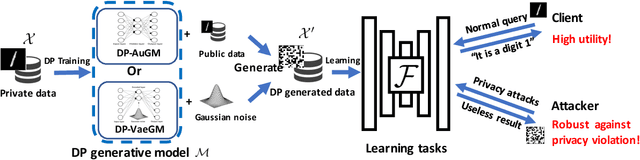
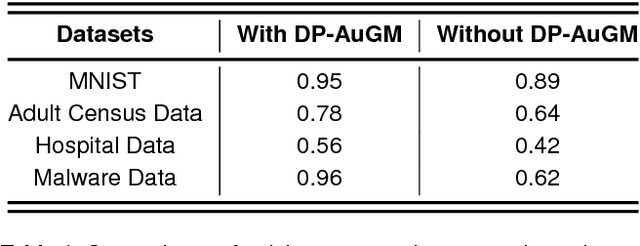


Deep neural networks (DNNs) have recently been widely adopted in various applications, and such success is largely due to a combination of algorithmic breakthroughs, computation resource improvements, and access to a large amount of data. However, the large-scale data collections required for deep learning often contain sensitive information, therefore raising many privacy concerns. Prior research has shown several successful attacks in inferring sensitive training data information, such as model inversion, membership inference, and generative adversarial networks (GAN) based leakage attacks against collaborative deep learning. In this paper, to enable learning efficiency as well as to generate data with privacy guarantees and high utility, we propose a differentially private autoencoder-based generative model (DP-AuGM) and a differentially private variational autoencoder-based generative model (DP-VaeGM). We evaluate the robustness of two proposed models. We show that DP-AuGM can effectively defend against the model inversion, membership inference, and GAN-based attacks. We also show that DP-VaeGM is robust against the membership inference attack. We conjecture that the key to defend against the model inversion and GAN-based attacks is not due to differential privacy but the perturbation of training data. Finally, we demonstrate that both DP-AuGM and DP-VaeGM can be easily integrated with real-world machine learning applications, such as machine learning as a service and federated learning, which are otherwise threatened by the membership inference attack and the GAN-based attack, respectively.