 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting AI Trojans Using Meta Neural Analysis
Oct 09, 2019
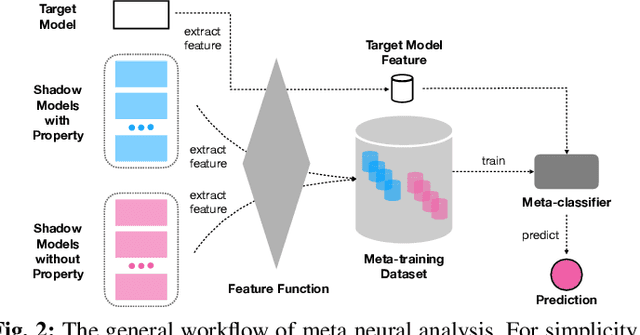


Machine learning models, especially neural networks (NNs), have achieved outstanding performance on diverse and complex applications. However, recent work has found that they are vulnerable to Trojan attacks where an adversary trains a corrupted model with poisoned data or directly manipulates its parameters in a stealthy way. Such Trojaned models can obtain good performance on normal data during test time while predicting incorrectly on the adversarially manipulated data samples. This paper aims to develop ways to detect Trojaned models. We mainly explore the idea of meta neural analysis, a technique involving training a meta NN model that can be used to predict whether or not a target NN model has certain properties. We develop a novel pipeline Meta Neural Trojaned model Detection (MNTD) system to predict if a given NN is Trojaned via meta neural analysis on a set of trained shadow models. We propose two ways to train the meta-classifier without knowing the Trojan attacker's strategies. The first one, one-class learning, will fit a novel detection meta-classifier using only benign neural networks. The second one, called jumbo learning, will approximate a general distribution of Trojaned models and sample a "jumbo" set of Trojaned models to train the meta-classifier and evaluate on the unseen Trojan strategies. Extensive experiments demonstrate the effectiveness of MNTD in detecting different Trojan attacks in diverse areas such as vision, speech, tabular data, and natural language processing. We show that MNTD reaches an average of 97% detection AUC (Area Under the ROC Curve) score and outperforms existing approaches. Furthermore, we design and evaluate MNTD system to defend against strong adaptive attackers who have exactly the knowledge of the detection, which demonstrates the robustness of MNTD.
Differentially Private Data Generative Models
Dec 06, 2018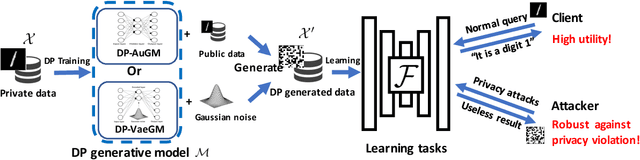
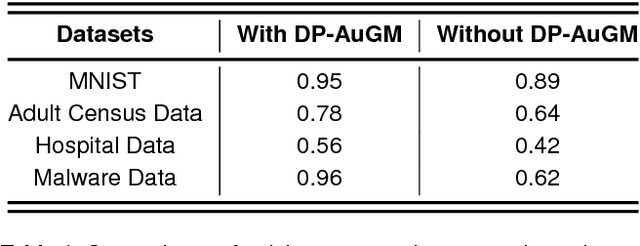


Deep neural networks (DNNs) have recently been widely adopted in various applications, and such success is largely due to a combination of algorithmic breakthroughs, computation resource improvements, and access to a large amount of data. However, the large-scale data collections required for deep learning often contain sensitive information, therefore raising many privacy concerns. Prior research has shown several successful attacks in inferring sensitive training data information, such as model inversion, membership inference, and generative adversarial networks (GAN) based leakage attacks against collaborative deep learning. In this paper, to enable learning efficiency as well as to generate data with privacy guarantees and high utility, we propose a differentially private autoencoder-based generative model (DP-AuGM) and a differentially private variational autoencoder-based generative model (DP-VaeGM). We evaluate the robustness of two proposed models. We show that DP-AuGM can effectively defend against the model inversion, membership inference, and GAN-based attacks. We also show that DP-VaeGM is robust against the membership inference attack. We conjecture that the key to defend against the model inversion and GAN-based attacks is not due to differential privacy but the perturbation of training data. Finally, we demonstrate that both DP-AuGM and DP-VaeGM can be easily integrated with real-world machine learning applications, such as machine learning as a service and federated learning, which are otherwise threatened by the membership inference attack and the GAN-based attack, respectively.