 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDoG: Adversarial Edge Detection For Graph Neural Networks
Dec 27, 2022Graph Neural Networks (GNNs) have been widely applied to different tasks such as bioinformatics, drug design, and social networks. However, recent studies have shown that GNNs are vulnerable to adversarial attacks which aim to mislead the node or subgraph classification prediction by adding subtle perturbations. Detecting these attacks is challenging due to the small magnitude of perturbation and the discrete nature of graph data. In this paper, we propose a general adversarial edge detection pipeline EDoG without requiring knowledge of the attack strategies based on graph generation. Specifically, we propose a novel graph generation approach combined with link prediction to detect suspicious adversarial edges. To effectively train the graph generative model, we sample several sub-graphs from the given graph data. We show that since the number of adversarial edges is usually low in practice, with low probability the sampled sub-graphs will contain adversarial edges based on the union bound. In addition, considering the strong attacks which perturb a large number of edges, we propose a set of novel features to perform outlier detection as the preprocessing for our detection. Extensive experimental results on three real-world graph datasets including a private transaction rule dataset from a major company and two types of synthetic graphs with controlled properties show that EDoG can achieve above 0.8 AUC against four state-of-the-art unseen attack strategies without requiring any knowledge about the attack type; and around 0.85 with knowledge of the attack type. EDoG significantly outperforms traditional malicious edge detection baselines. We also show that an adaptive attack with full knowledge of our detection pipeline is difficult to bypass it.
Detecting AI Trojans Using Meta Neural Analysis
Oct 09, 2019
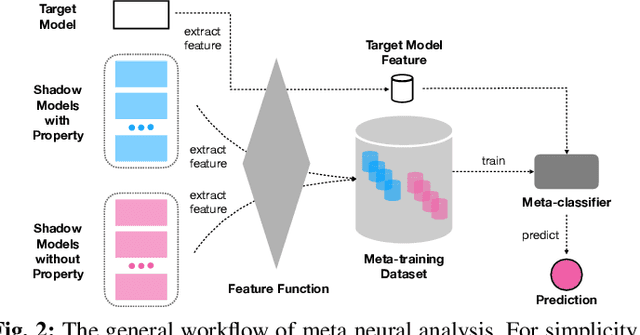


Machine learning models, especially neural networks (NNs), have achieved outstanding performance on diverse and complex applications. However, recent work has found that they are vulnerable to Trojan attacks where an adversary trains a corrupted model with poisoned data or directly manipulates its parameters in a stealthy way. Such Trojaned models can obtain good performance on normal data during test time while predicting incorrectly on the adversarially manipulated data samples. This paper aims to develop ways to detect Trojaned models. We mainly explore the idea of meta neural analysis, a technique involving training a meta NN model that can be used to predict whether or not a target NN model has certain properties. We develop a novel pipeline Meta Neural Trojaned model Detection (MNTD) system to predict if a given NN is Trojaned via meta neural analysis on a set of trained shadow models. We propose two ways to train the meta-classifier without knowing the Trojan attacker's strategies. The first one, one-class learning, will fit a novel detection meta-classifier using only benign neural networks. The second one, called jumbo learning, will approximate a general distribution of Trojaned models and sample a "jumbo" set of Trojaned models to train the meta-classifier and evaluate on the unseen Trojan strategies. Extensive experiments demonstrate the effectiveness of MNTD in detecting different Trojan attacks in diverse areas such as vision, speech, tabular data, and natural language processing. We show that MNTD reaches an average of 97% detection AUC (Area Under the ROC Curve) score and outperforms existing approaches. Furthermore, we design and evaluate MNTD system to defend against strong adaptive attackers who have exactly the knowledge of the detection, which demonstrates the robustness of MNTD.
Scalable Differentially Private Generative Student Model via PATE
Jun 21, 2019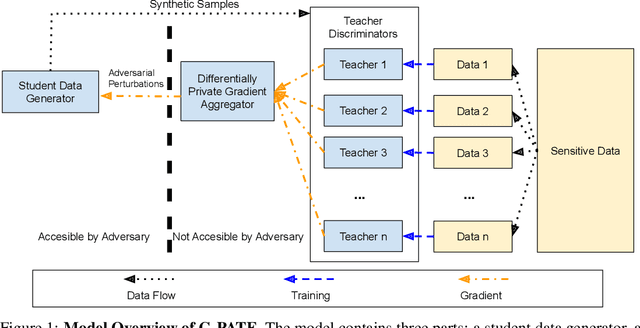
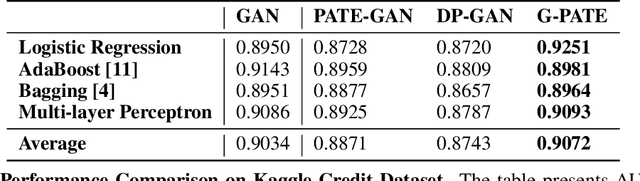
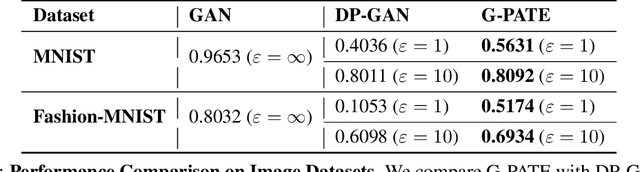

Recent rapid development of machine learning is largely due to algorithmic breakthroughs, computation resource development, and especially the access to a large amount of training data. However, though data sharing has the great potential of improving machine learning models and enabling new applications, there have been increasing concerns about the privacy implications of data collection. In this work, we present a novel approach for training differentially private data generator G-PATE. The generator can be used to produce synthetic datasets with strong privacy guarantee while preserving high data utility. Our approach leverages generative adversarial nets (GAN) to generate data and protect data privacy based on the Private Aggregation of Teacher Ensembles (PATE) framework. Our approach improves the use of privacy budget by only ensuring differential privacy for the generator, which is the part of the model that actually needs to be published for private data generation. To achieve this, we connect a student generator with an ensemble of teacher discriminators. We also propose a private gradient aggregation mechanism to ensure differential privacy on all the information that flows from the teacher discriminators to the student generator. We empirically show that the G-PATE significantly outperforms prior work on both image and non-image datasets.
CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition
Jul 02, 2018
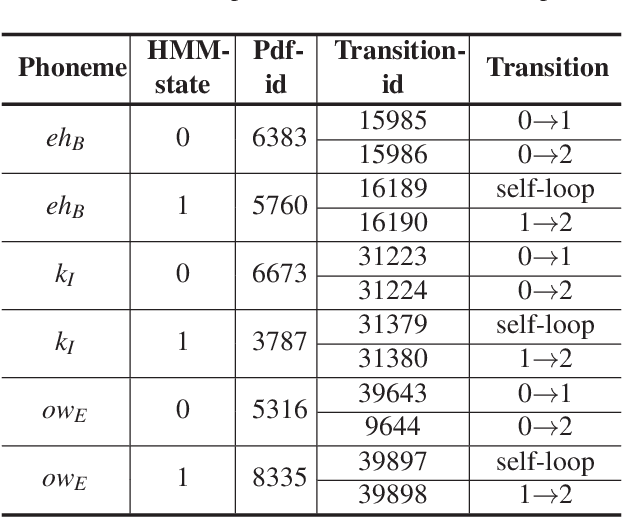

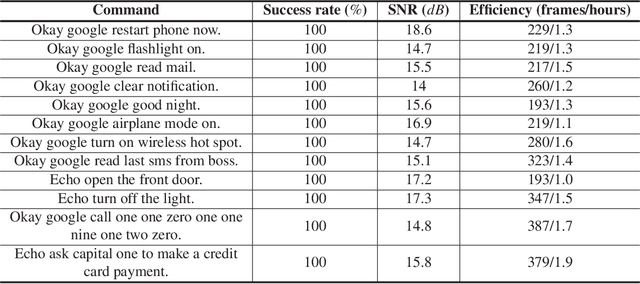
The popularity of ASR (automatic speech recognition) systems, like Google Voice, Cortana, brings in security concerns, as demonstrated by recent attacks. The impacts of such threats, however, are less clear, since they are either less stealthy (producing noise-like voice commands) or requiring the physical presence of an attack device (using ultrasound). In this paper, we demonstrate that not only are more practical and surreptitious attacks feasible but they can even be automatically constructed. Specifically, we find that the voice commands can be stealthily embedded into songs, which, when played, can effectively control the target system through ASR without being noticed. For this purpose, we developed novel techniques that address a key technical challenge: integrating the commands into a song in a way that can be effectively recognized by ASR through the air, in the presence of background noise, while not being detected by a human listener. Our research shows that this can be done automatically against real world ASR applications. We also demonstrate that such CommanderSongs can be spread through Internet (e.g., YouTube) and radio, potentially affecting millions of ASR users. We further present a new mitigation technique that controls this threat.
Understanding Membership Inferences on Well-Generalized Learning Models
Feb 13, 2018
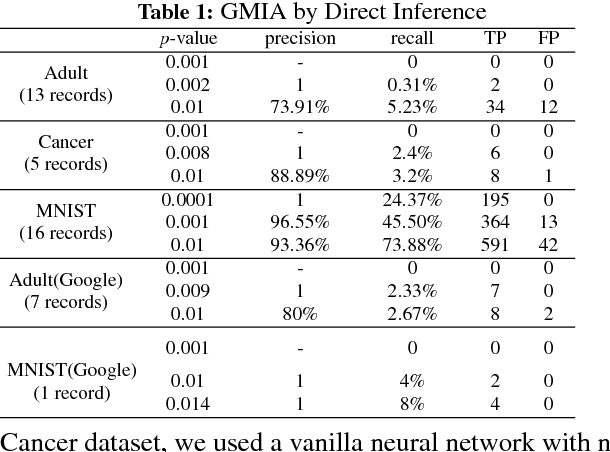
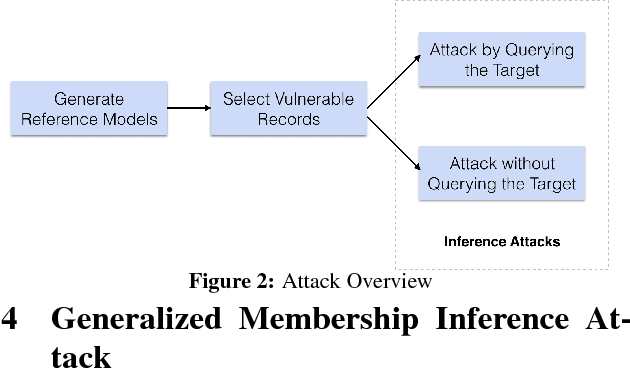
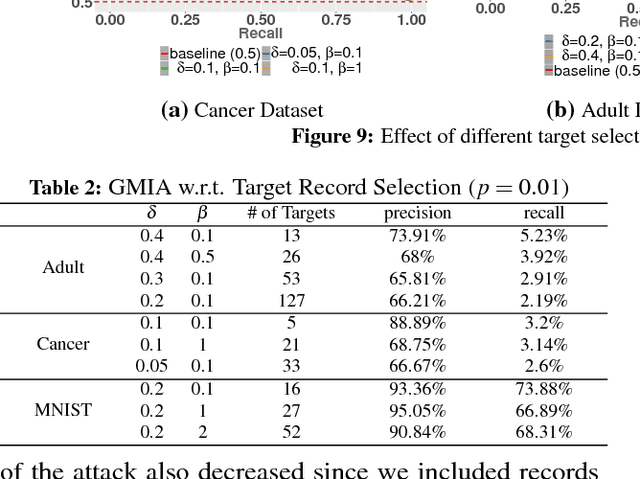
Membership Inference Attack (MIA) determines the presence of a record in a machine learning model's training data by querying the model. Prior work has shown that the attack is feasible when the model is overfitted to its training data or when the adversary controls the training algorithm. However, when the model is not overfitted and the adversary does not control the training algorithm, the threat is not well understood. In this paper, we report a study that discovers overfitting to be a sufficient but not a necessary condition for an MIA to succeed. More specifically, we demonstrate that even a well-generalized model contains vulnerable instances subject to a new generalized MIA (GMIA). In GMIA, we use novel techniques for selecting vulnerable instances and detecting their subtle influences ignored by overfitting metrics. Specifically, we successfully identify individual records with high precision in real-world datasets by querying black-box machine learning models. Further we show that a vulnerable record can even be indirectly attacked by querying other related records and existing generalization techniques are found to be less effective in protecting the vulnerable instances. Our findings sharpen the understanding of the fundamental cause of the problem: the unique influences the training instance may have on the model.
Plausible Deniability for Privacy-Preserving Data Synthesis
Aug 26, 2017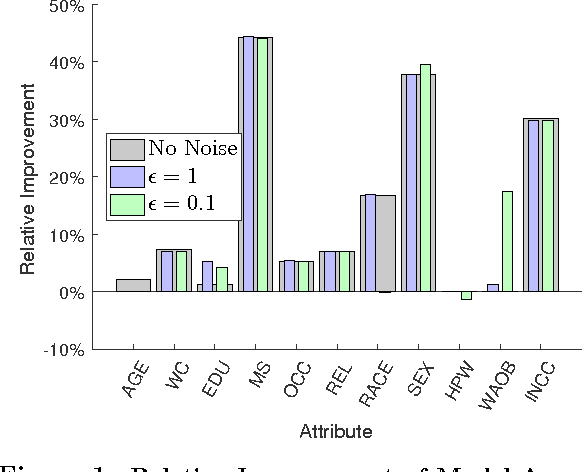


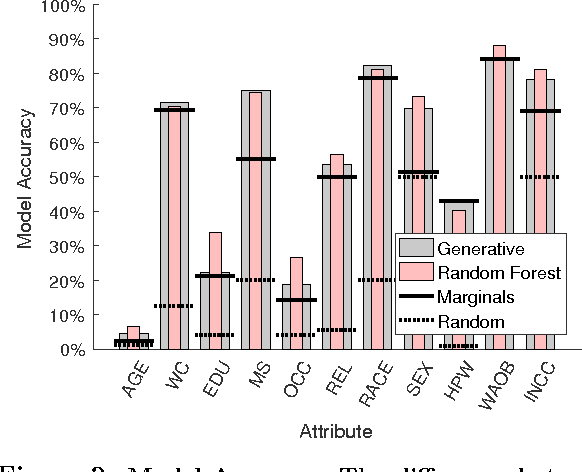
Releasing full data records is one of the most challenging problems in data privacy. On the one hand, many of the popular techniques such as data de-identification are problematic because of their dependence on the background knowledge of adversaries. On the other hand, rigorous methods such as the exponential mechanism for differential privacy are often computationally impractical to use for releasing high dimensional data or cannot preserve high utility of original data due to their extensive data perturbation. This paper presents a criterion called plausible deniability that provides a formal privacy guarantee, notably for releasing sensitive datasets: an output record can be released only if a certain amount of input records are indistinguishable, up to a privacy parameter. This notion does not depend on the background knowledge of an adversary. Also, it can efficiently be checked by privacy tests. We present mechanisms to generate synthetic datasets with similar statistical properties to the input data and the same format. We study this technique both theoretically and experimentally. A key theoretical result shows that, with proper randomization, the plausible deniability mechanism generates differentially private synthetic data. We demonstrate the efficiency of this generative technique on a large dataset; it is shown to preserve the utility of original data with respect to various statistical analysis and machine learning measures.