 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Adversarial Inverse Reinforcement Learning: From the Angles of Policy Imitation and Transferable Reward Recovery
Mar 21, 2024
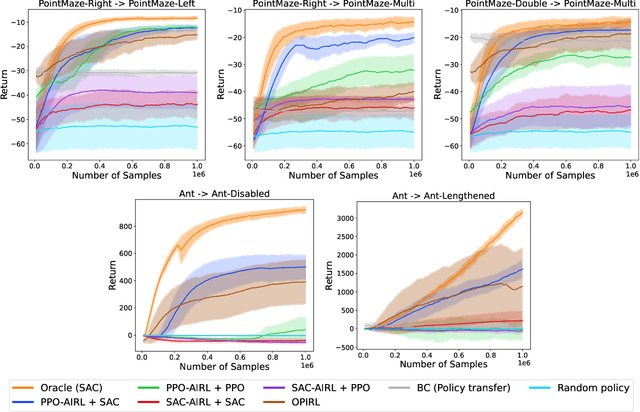

Adversarial inverse reinforcement learning (AIRL) stands as a cornerstone approach in imitation learning. This paper rethinks the two different angles of AIRL: policy imitation and transferable reward recovery. We begin with substituting the built-in algorithm in AIRL with soft actor-critic (SAC) during the policy optimization process to enhance sample efficiency, thanks to the off-policy formulation of SAC and identifiable Markov decision process (MDP) models with respect to AIRL. It indeed exhibits a significant improvement in policy imitation but accidentally brings drawbacks to transferable reward recovery. To learn this issue, we illustrate that the SAC algorithm itself is not feasible to disentangle the reward function comprehensively during the AIRL training process, and propose a hybrid framework, PPO-AIRL + SAC, for satisfactory transfer effect. Additionally, we analyze the capability of environments to extract disentangled rewards from an algebraic theory perspective.
Exploring Gradient Explosion in Generative Adversarial Imitation Learning: A Probabilistic Perspective
Dec 18, 2023



Generative Adversarial Imitation Learning (GAIL) stands as a cornerstone approach in imitation learning. This paper investigates the gradient explosion in two types of GAIL: GAIL with deterministic policy (DE-GAIL) and GAIL with stochastic policy (ST-GAIL). We begin with the observation that the training can be highly unstable for DE-GAIL at the beginning of the training phase and end up divergence. Conversely, the ST-GAIL training trajectory remains consistent, reliably converging. To shed light on these disparities, we provide an explanation from a theoretical perspective. By establishing a probabilistic lower bound for GAIL, we demonstrate that gradient explosion is an inevitable outcome for DE-GAIL due to occasionally large expert-imitator policy disparity, whereas ST-GAIL does not have the issue with it. To substantiate our assertion, we illustrate how modifications in the reward function can mitigate the gradient explosion challenge. Finally, we propose CREDO, a simple yet effective strategy that clips the reward function during the training phase, allowing the GAIL to enjoy high data efficiency and stable trainability.