 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Agnostic Robotic Long-Horizon Manipulation with Vision-Language-Guided Closed-Loop Feedback
Mar 27, 2025Recent advances in language-conditioned robotic manipulation have leveraged imitation and reinforcement learning to enable robots to execute tasks from human commands. However, these methods often suffer from limited generalization, adaptability, and the lack of large-scale specialized datasets, unlike data-rich domains such as computer vision, making long-horizon task execution challenging. To address these gaps, we introduce DAHLIA, a data-agnostic framework for language-conditioned long-horizon robotic manipulation, leveraging large language models (LLMs) for real-time task planning and execution. DAHLIA employs a dual-tunnel architecture, where an LLM-powered planner collaborates with co-planners to decompose tasks and generate executable plans, while a reporter LLM provides closed-loop feedback, enabling adaptive re-planning and ensuring task recovery from potential failures. Moreover, DAHLIA integrates chain-of-thought (CoT) in task reasoning and temporal abstraction for efficient action execution, enhancing traceability and robustness. Our framework demonstrates state-of-the-art performance across diverse long-horizon tasks, achieving strong generalization in both simulated and real-world scenarios. Videos and code are available at https://ghiara.github.io/DAHLIA/.
Robustness Testing of Multi-Modal Models in Varied Home Environments for Assistive Robots
Jun 18, 2024The development of assistive robotic agents to support household tasks is advancing, yet the underlying models often operate in virtual settings that do not reflect real-world complexity. For assistive care robots to be effective in diverse environments, their models must be robust and integrate multiple modalities. Consider a caretaker needing assistance in a dimly lit room or navigating around a newly installed glass door. Models relying solely on visual input might fail in low light, while those using depth information could avoid the door. This demonstrates the necessity for models that can process various sensory inputs. Our ongoing study evaluates state-of-the-art robotic models in the AI2Thor virtual environment. We introduce disturbances, such as dimmed lighting and mirrored walls, to assess their impact on modalities like movement or vision, and object recognition. Our goal is to gather input from the Geriatronics community to understand and model the challenges faced by practitioners.
LoHoRavens: A Long-Horizon Language-Conditioned Benchmark for Robotic Tabletop Manipulation
Oct 23, 2023



The convergence of embodied agents and large language models (LLMs) has brought significant advancements to embodied instruction following. Particularly, the strong reasoning capabilities of LLMs make it possible for robots to perform long-horizon tasks without expensive annotated demonstrations. However, public benchmarks for testing the long-horizon reasoning capabilities of language-conditioned robots in various scenarios are still missing. To fill this gap, this work focuses on the tabletop manipulation task and releases a simulation benchmark, \textit{LoHoRavens}, which covers various long-horizon reasoning aspects spanning color, size, space, arithmetics and reference. Furthermore, there is a key modality bridging problem for long-horizon manipulation tasks with LLMs: how to incorporate the observation feedback during robot execution for the LLM's closed-loop planning, which is however less studied by prior work. We investigate two methods of bridging the modality gap: caption generation and learnable interface for incorporating explicit and implicit observation feedback to the LLM, respectively. These methods serve as the two baselines for our proposed benchmark. Experiments show that both methods struggle to solve some tasks, indicating long-horizon manipulation tasks are still challenging for current popular models. We expect the proposed public benchmark and baselines can help the community develop better models for long-horizon tabletop manipulation tasks.
Towards Language-Based Modulation of Assistive Robots through Multimodal Models
Jun 27, 2023
In the field of Geriatronics, enabling effective and transparent communication between humans and robots is crucial for enhancing the acceptance and performance of assistive robots. Our early-stage research project investigates the potential of language-based modulation as a means to improve human-robot interaction. We propose to explore real-time modulation during task execution, leveraging language cues, visual references, and multimodal inputs. By developing transparent and interpretable methods, we aim to enable robots to adapt and respond to language commands, enhancing their usability and flexibility. Through the exchange of insights and knowledge at the workshop, we seek to gather valuable feedback to advance our research and contribute to the development of interactive robotic systems for Geriatronics and beyond.
Attention Temperature Matters in Abstractive Summarization Distillation
Jun 08, 2021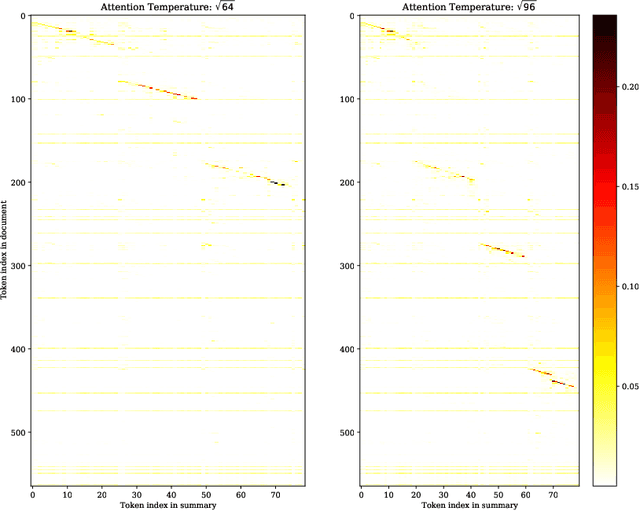
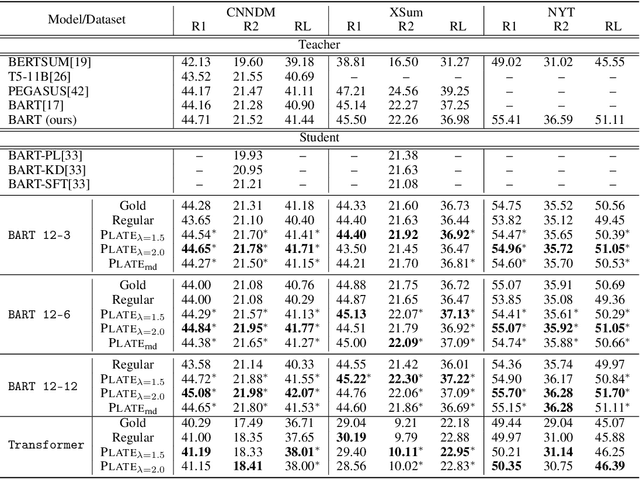
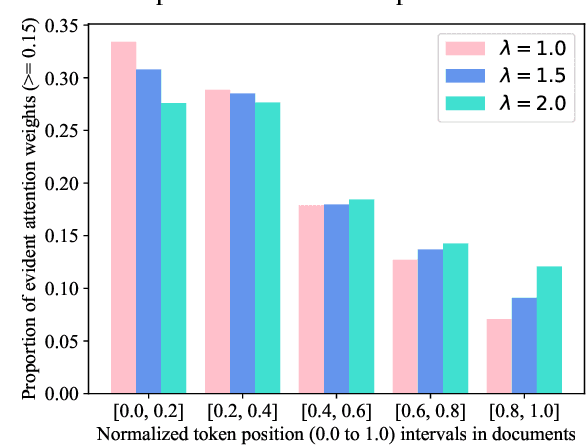
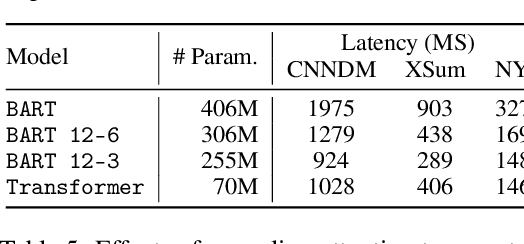
Recent progress of abstractive text summarization largely relies on large pre-trained sequence-to-sequence Transformer models, which are computationally expensive. This paper aims to distill these large models into smaller ones for faster inference and minimal performance loss. Pseudo-labeling based methods are popular in sequence-to-sequence model distillation. In this paper, we find simply manipulating attention temperatures in Transformers can make pseudo labels easier to learn for student models. Our experiments on three summarization datasets show our proposed method consistently improves over vanilla pseudo-labeling based methods. We also find that both the pseudo labels and summaries produced by our students are shorter and more abstractive. We will make our code and models publicly available.
Pre-trained Language Model based Ranking in Baidu Search
Jun 03, 2021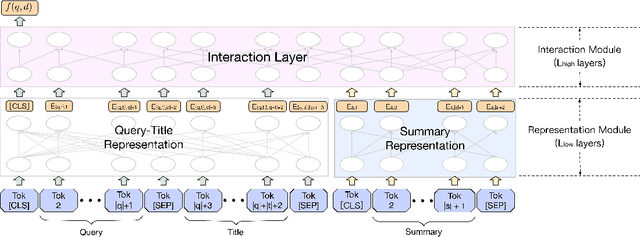

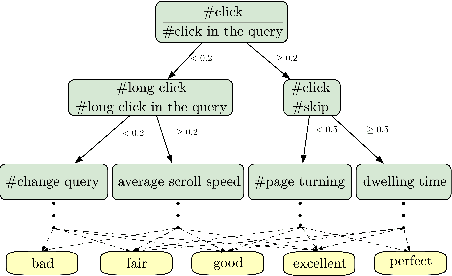

As the heart of a search engine, the ranking system plays a crucial role in satisfying users' information demands. More recently, neural rankers fine-tuned from pre-trained language models (PLMs) establish state-of-the-art ranking effectiveness. However, it is nontrivial to directly apply these PLM-based rankers to the large-scale web search system due to the following challenging issues:(1) the prohibitively expensive computations of massive neural PLMs, especially for long texts in the web-document, prohibit their deployments in an online ranking system that demands extremely low latency;(2) the discrepancy between existing ranking-agnostic pre-training objectives and the ad-hoc retrieval scenarios that demand comprehensive relevance modeling is another main barrier for improving the online ranking system;(3) a real-world search engine typically involves a committee of ranking components, and thus the compatibility of the individually fine-tuned ranking model is critical for a cooperative ranking system. In this work, we contribute a series of successfully applied techniques in tackling these exposed issues when deploying the state-of-the-art Chinese pre-trained language model, i.e., ERNIE, in the online search engine system. We first articulate a novel practice to cost-efficiently summarize the web document and contextualize the resultant summary content with the query using a cheap yet powerful Pyramid-ERNIE architecture. Then we endow an innovative paradigm to finely exploit the large-scale noisy and biased post-click behavioral data for relevance-oriented pre-training. We also propose a human-anchored fine-tuning strategy tailored for the online ranking system, aiming to stabilize the ranking signals across various online components. Extensive offline and online experimental results show that the proposed techniques significantly boost the search engine's performance.