 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Workload and Agreement From EEG During Spoken Dialogue With Conversational AI
Jan 09, 2026Passive brain-computer interfaces offer a potential source of implicit feedback for alignment of large language models, but most mental state decoding has been done in controlled tasks. This paper investigates whether established EEG classifiers for mental workload and implicit agreement can be transferred to spoken human-AI dialogue. We introduce two conversational paradigms - a Spelling Bee task and a sentence completion task- and an end-to-end pipeline for transcribing, annotating, and aligning word-level conversational events with continuous EEG classifier output. In a pilot study, workload decoding showed interpretable trends during spoken interaction, supporting cross-paradigm transfer. For implicit agreement, we demonstrate continuous application and precise temporal alignment to conversational events, while identifying limitations related to construct transfer and asynchronous application of event-based classifiers. Overall, the results establish feasibility and constraints for integrating passive BCI signals into conversational AI systems.
Red and blue language: Word choices in the Trump & Harris 2024 presidential debate
Oct 17, 2024Political debates are a peculiar type of political discourse, in which candidates directly confront one another, addressing not only the the moderator's questions, but also their opponent's statements, as well as the concerns of voters from both parties and undecided voters. Therefore, language is adjusted to meet specific expectations and achieve persuasion. We analyse how the language of Trump and Harris during the debate (September 10th 2024) differs in relation to the following semantic and pragmatic features, for which we formulated targeted hypotheses: framing values and ideology, appealing to emotion, using words with different degrees of concreteness and specificity, addressing others through singular or plural pronouns. Our findings include: differences in the use of figurative frames (Harris often framing issues around recovery and empowerment, Trump often focused on crisis and decline); similar use of emotional language, with Trump showing a slight higher tendency toward negativity and toward less subjective language compared to Harris; no significant difference in the specificity of candidates' responses; similar use of abstract language, with Trump showing more variability than Harris, depending on the subject discussed; differences in addressing the opponent, with Trump not mentioning Harris by name, while Harris referring to Trump frequently; different uses of pronouns, with Harris using both singular and plural pronouns equally, while Trump using more singular pronouns. The results are discussed in relation to previous literature on Red and Blue language, which refers to distinct linguistic patterns associated with conservative (Red) and liberal (Blue) political ideologies.
Robustness Testing of Multi-Modal Models in Varied Home Environments for Assistive Robots
Jun 18, 2024The development of assistive robotic agents to support household tasks is advancing, yet the underlying models often operate in virtual settings that do not reflect real-world complexity. For assistive care robots to be effective in diverse environments, their models must be robust and integrate multiple modalities. Consider a caretaker needing assistance in a dimly lit room or navigating around a newly installed glass door. Models relying solely on visual input might fail in low light, while those using depth information could avoid the door. This demonstrates the necessity for models that can process various sensory inputs. Our ongoing study evaluates state-of-the-art robotic models in the AI2Thor virtual environment. We introduce disturbances, such as dimmed lighting and mirrored walls, to assess their impact on modalities like movement or vision, and object recognition. Our goal is to gather input from the Geriatronics community to understand and model the challenges faced by practitioners.
Exploring Spatial Schema Intuitions in Large Language and Vision Models
Feb 01, 2024Despite the ubiquity of large language models (LLMs) in AI research, the question of embodiment in LLMs remains underexplored, distinguishing them from embodied systems in robotics where sensory perception directly informs physical action. Our investigation navigates the intriguing terrain of whether LLMs, despite their non-embodied nature, effectively capture implicit human intuitions about fundamental, spatial building blocks of language. We employ insights from spatial cognitive foundations developed through early sensorimotor experiences, guiding our exploration through the reproduction of three psycholinguistic experiments. Surprisingly, correlations between model outputs and human responses emerge, revealing adaptability without a tangible connection to embodied experiences. Notable distinctions include polarized language model responses and reduced correlations in vision language models. This research contributes to a nuanced understanding of the interplay between language, spatial experiences, and the computations made by large language models. More at https://cisnlp.github.io/Spatial_Schemas/
Probing Language Models' Gesture Understanding for Enhanced Human-AI Interaction
Jan 31, 2024The rise of Large Language Models (LLMs) has affected various disciplines that got beyond mere text generation. Going beyond their textual nature, this project proposal aims to investigate the interaction between LLMs and non-verbal communication, specifically focusing on gestures. The proposal sets out a plan to examine the proficiency of LLMs in deciphering both explicit and implicit non-verbal cues within textual prompts and their ability to associate these gestures with various contextual factors. The research proposes to test established psycholinguistic study designs to construct a comprehensive dataset that pairs textual prompts with detailed gesture descriptions, encompassing diverse regional variations, and semantic labels. To assess LLMs' comprehension of gestures, experiments are planned, evaluating their ability to simulate human behaviour in order to replicate psycholinguistic experiments. These experiments consider cultural dimensions and measure the agreement between LLM-identified gestures and the dataset, shedding light on the models' contextual interpretation of non-verbal cues (e.g. gestures).
LoHoRavens: A Long-Horizon Language-Conditioned Benchmark for Robotic Tabletop Manipulation
Oct 23, 2023



The convergence of embodied agents and large language models (LLMs) has brought significant advancements to embodied instruction following. Particularly, the strong reasoning capabilities of LLMs make it possible for robots to perform long-horizon tasks without expensive annotated demonstrations. However, public benchmarks for testing the long-horizon reasoning capabilities of language-conditioned robots in various scenarios are still missing. To fill this gap, this work focuses on the tabletop manipulation task and releases a simulation benchmark, \textit{LoHoRavens}, which covers various long-horizon reasoning aspects spanning color, size, space, arithmetics and reference. Furthermore, there is a key modality bridging problem for long-horizon manipulation tasks with LLMs: how to incorporate the observation feedback during robot execution for the LLM's closed-loop planning, which is however less studied by prior work. We investigate two methods of bridging the modality gap: caption generation and learnable interface for incorporating explicit and implicit observation feedback to the LLM, respectively. These methods serve as the two baselines for our proposed benchmark. Experiments show that both methods struggle to solve some tasks, indicating long-horizon manipulation tasks are still challenging for current popular models. We expect the proposed public benchmark and baselines can help the community develop better models for long-horizon tabletop manipulation tasks.
Towards Language-Based Modulation of Assistive Robots through Multimodal Models
Jun 27, 2023
In the field of Geriatronics, enabling effective and transparent communication between humans and robots is crucial for enhancing the acceptance and performance of assistive robots. Our early-stage research project investigates the potential of language-based modulation as a means to improve human-robot interaction. We propose to explore real-time modulation during task execution, leveraging language cues, visual references, and multimodal inputs. By developing transparent and interpretable methods, we aim to enable robots to adapt and respond to language commands, enhancing their usability and flexibility. Through the exchange of insights and knowledge at the workshop, we seek to gather valuable feedback to advance our research and contribute to the development of interactive robotic systems for Geriatronics and beyond.
LMs stand their Ground: Investigating the Effect of Embodiment in Figurative Language Interpretation by Language Models
May 15, 2023
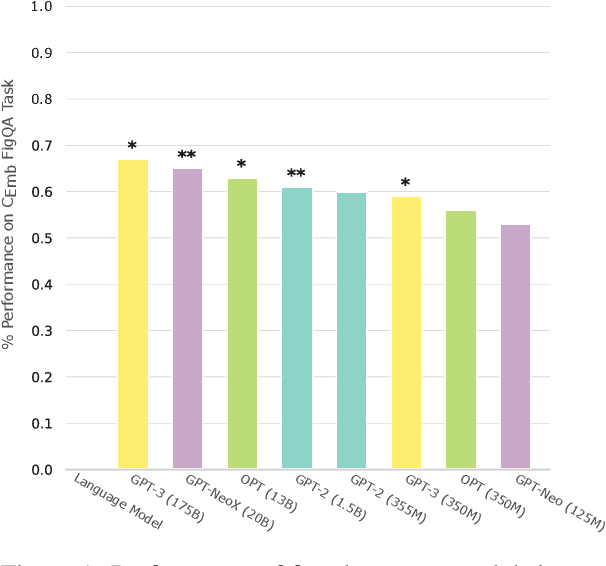
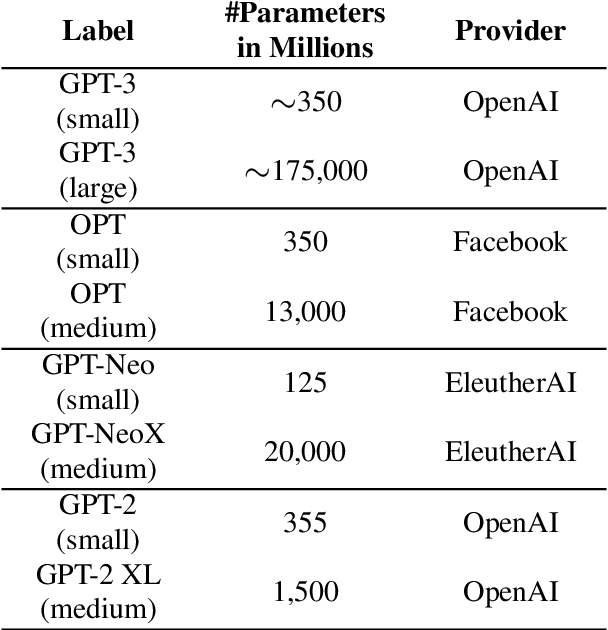
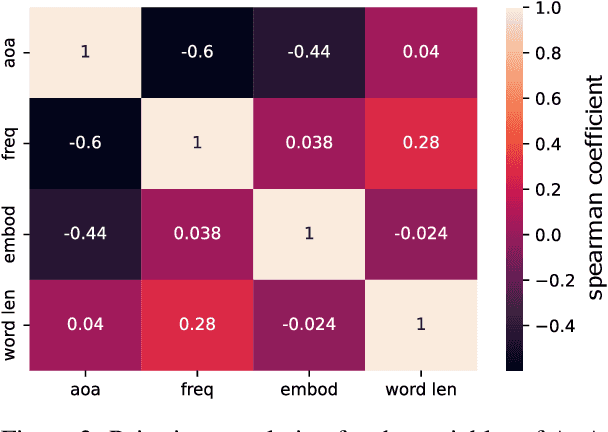
Figurative language is a challenge for language models since its interpretation is based on the use of words in a way that deviates from their conventional order and meaning. Yet, humans can easily understand and interpret metaphors, similes or idioms as they can be derived from embodied metaphors. Language is a proxy for embodiment and if a metaphor is conventional and lexicalised, it becomes easier for a system without a body to make sense of embodied concepts. Yet, the intricate relation between embodiment and features such as concreteness or age of acquisition has not been studied in the context of figurative language interpretation concerning language models. Hence, the presented study shows how larger language models perform better at interpreting metaphoric sentences when the action of the metaphorical sentence is more embodied. The analysis rules out multicollinearity with other features (e.g. word length or concreteness) and provides initial evidence that larger language models conceptualise embodied concepts to a degree that facilitates figurative language understanding.
A Crosslingual Investigation of Conceptualization in 1335 Languages
May 15, 2023



Languages differ in how they divide up the world into concepts and words; e.g., in contrast to English, Swahili has a single concept for `belly' and `womb'. We investigate these differences in conceptualization across 1,335 languages by aligning concepts in a parallel corpus. To this end, we propose Conceptualizer, a method that creates a bipartite directed alignment graph between source language concepts and sets of target language strings. In a detailed linguistic analysis across all languages for one concept (`bird') and an evaluation on gold standard data for 32 Swadesh concepts, we show that Conceptualizer has good alignment accuracy. We demonstrate the potential of research on conceptualization in NLP with two experiments. (1) We define crosslingual stability of a concept as the degree to which it has 1-1 correspondences across languages, and show that concreteness predicts stability. (2) We represent each language by its conceptualization pattern for 83 concepts, and define a similarity measure on these representations. The resulting measure for the conceptual similarity of two languages is complementary to standard genealogical, typological, and surface similarity measures. For four out of six language families, we can assign languages to their correct family based on conceptual similarity with accuracy between 54\% and 87\%.
Creative Action at a Distance: A Conceptual Framework for Embodied Performance With Robotic Actors
Apr 30, 2021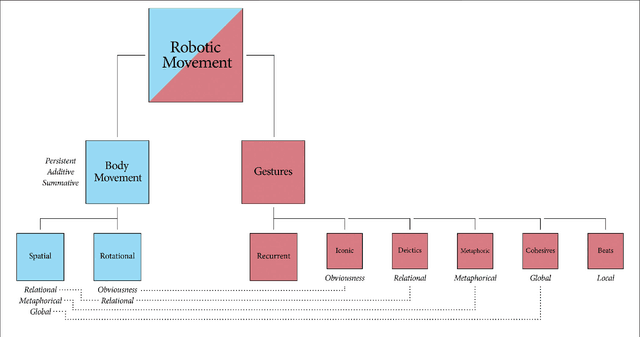
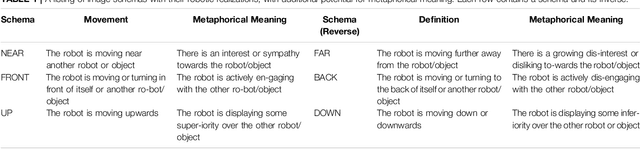
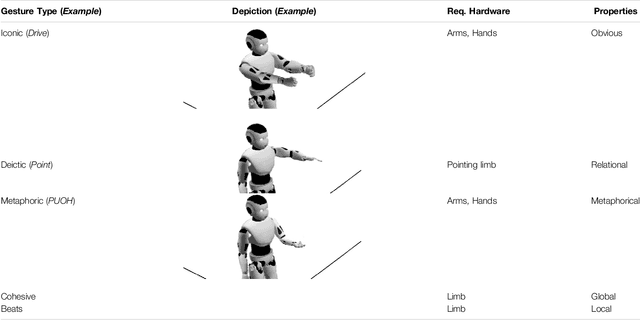
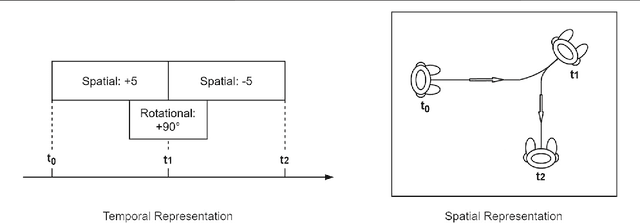
Acting, stand-up and dancing are creative, embodied performances that nonetheless follow a script. Unless experimental or improvised, the performers draw their movements from much the same stock of embodied schemas. A slavish following of the script leaves no room for creativity, but active interpretation of the script does. It is the choices one makes, of words and actions, that make a performance creative. In this theory and hypothesis article, we present a framework for performance and interpretation within robotic storytelling. The performance framework is built upon movement theory, and defines a taxonomy of basic schematic movements and the most important gesture types. For the interpretation framework, we hypothesise that emotionally-grounded choices can inform acts of metaphor and blending, to elevate a scripted performance into a creative one. Theory and hypothesis are each grounded in empirical research, and aim to provide resources for other robotic studies of the creative use of movement and gestures.
* 22 pages, 7 figures, open-access, Research Topic: Creativity and Robotics