 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
Mar 27, 2024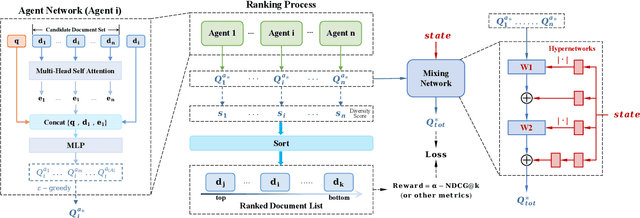

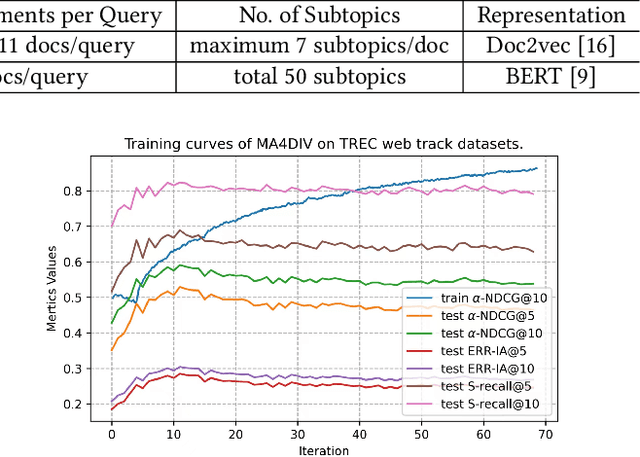
The objective of search result diversification (SRD) is to ensure that selected documents cover as many different subtopics as possible. Existing methods primarily utilize a paradigm of "greedy selection", i.e., selecting one document with the highest diversity score at a time. These approaches tend to be inefficient and are easily trapped in a suboptimal state. In addition, some other methods aim to approximately optimize the diversity metric, such as $\alpha$-NDCG, but the results still remain suboptimal. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. This approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted preliminary experiments on public TREC datasets to demonstrate the effectiveness and potential of MA4DIV. Considering the limited number of queries in public TREC datasets, we construct a large-scale dataset from industry sources and show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines on a industrial scale dataset.
PILE: Pairwise Iterative Logits Ensemble for Multi-Teacher Labeled Distillation
Nov 11, 2022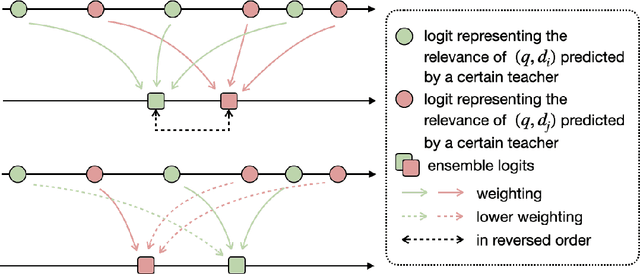

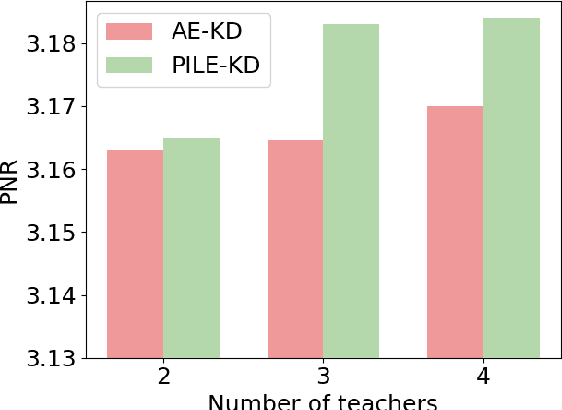
Pre-trained language models have become a crucial part of ranking systems and achieved very impressive effects recently. To maintain high performance while keeping efficient computations, knowledge distillation is widely used. In this paper, we focus on two key questions in knowledge distillation for ranking models: 1) how to ensemble knowledge from multi-teacher; 2) how to utilize the label information of data in the distillation process. We propose a unified algorithm called Pairwise Iterative Logits Ensemble (PILE) to tackle these two questions simultaneously. PILE ensembles multi-teacher logits supervised by label information in an iterative way and achieved competitive performance in both offline and online experiments. The proposed method has been deployed in a real-world commercial search system.
Pre-trained Language Model based Ranking in Baidu Search
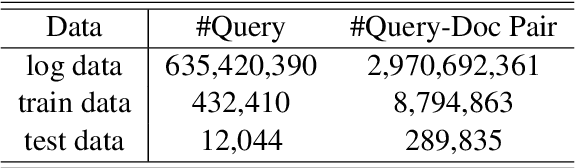
Jun 03, 2021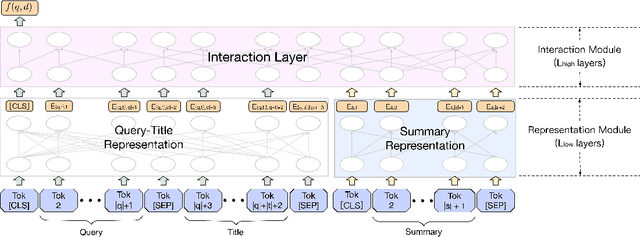

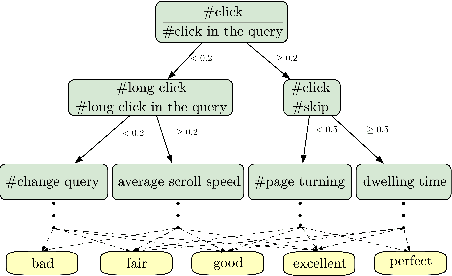

As the heart of a search engine, the ranking system plays a crucial role in satisfying users' information demands. More recently, neural rankers fine-tuned from pre-trained language models (PLMs) establish state-of-the-art ranking effectiveness. However, it is nontrivial to directly apply these PLM-based rankers to the large-scale web search system due to the following challenging issues:(1) the prohibitively expensive computations of massive neural PLMs, especially for long texts in the web-document, prohibit their deployments in an online ranking system that demands extremely low latency;(2) the discrepancy between existing ranking-agnostic pre-training objectives and the ad-hoc retrieval scenarios that demand comprehensive relevance modeling is another main barrier for improving the online ranking system;(3) a real-world search engine typically involves a committee of ranking components, and thus the compatibility of the individually fine-tuned ranking model is critical for a cooperative ranking system. In this work, we contribute a series of successfully applied techniques in tackling these exposed issues when deploying the state-of-the-art Chinese pre-trained language model, i.e., ERNIE, in the online search engine system. We first articulate a novel practice to cost-efficiently summarize the web document and contextualize the resultant summary content with the query using a cheap yet powerful Pyramid-ERNIE architecture. Then we endow an innovative paradigm to finely exploit the large-scale noisy and biased post-click behavioral data for relevance-oriented pre-training. We also propose a human-anchored fine-tuning strategy tailored for the online ranking system, aiming to stabilize the ranking signals across various online components. Extensive offline and online experimental results show that the proposed techniques significantly boost the search engine's performance.
Text Level Graph Neural Network for Text Classification
Oct 08, 2019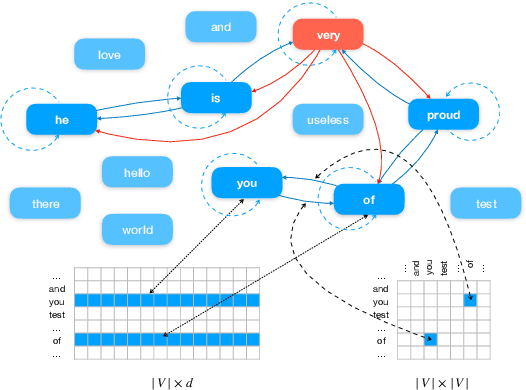
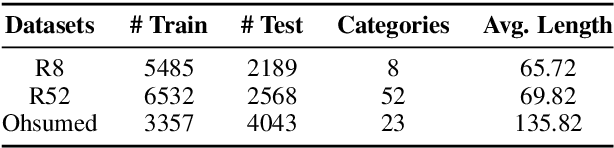
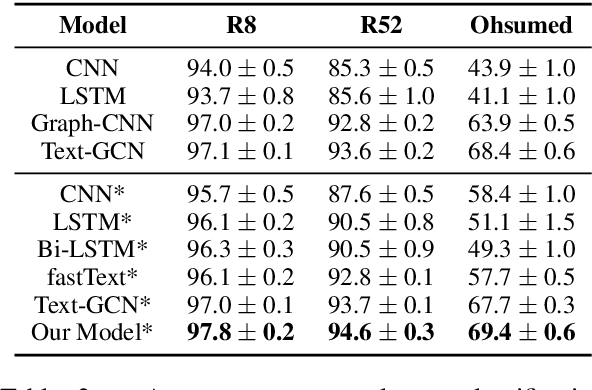
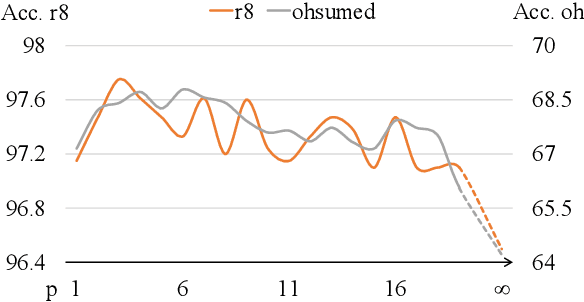
Recently, researches have explored the graph neural network (GNN) techniques on text classification, since GNN does well in handling complex structures and preserving global information. However, previous methods based on GNN are mainly faced with the practical problems of fixed corpus level graph structure which do not support online testing and high memory consumption. To tackle the problems, we propose a new GNN based model that builds graphs for each input text with global parameters sharing instead of a single graph for the whole corpus. This method removes the burden of dependence between an individual text and entire corpus which support online testing, but still preserve global information. Besides, we build graphs by much smaller windows in the text, which not only extract more local features but also significantly reduce the edge numbers as well as memory consumption. Experiments show that our model outperforms existing models on several text classification datasets even with consuming less memory.
Interactive Attention Networks for Aspect-Level Sentiment Classification
Sep 04, 2017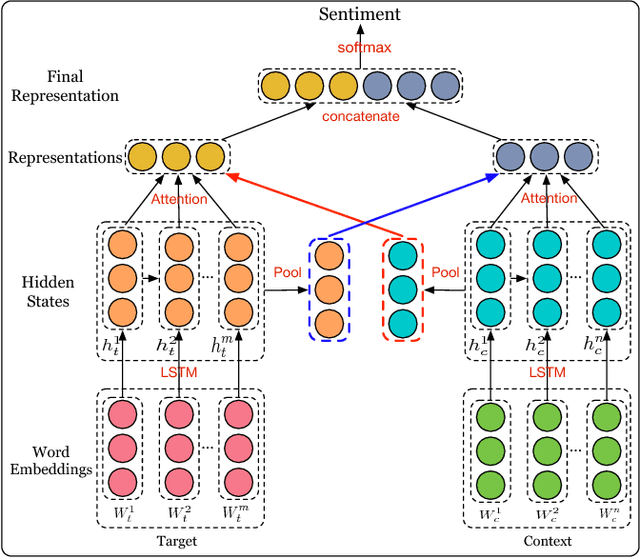
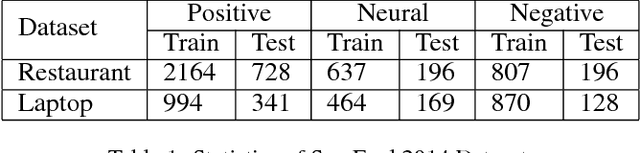
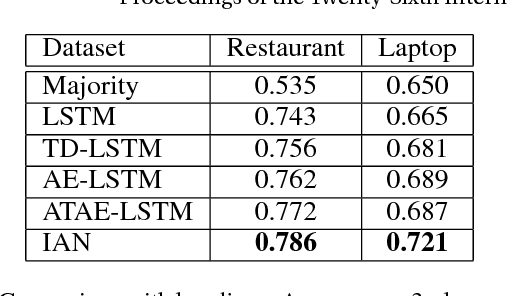
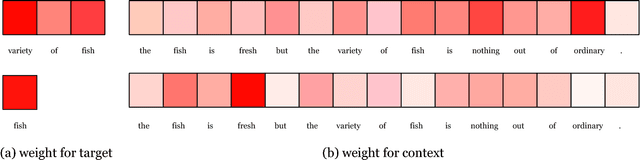
Aspect-level sentiment classification aims at identifying the sentiment polarity of specific target in its context. Previous approaches have realized the importance of targets in sentiment classification and developed various methods with the goal of precisely modeling their contexts via generating target-specific representations. However, these studies always ignore the separate modeling of targets. In this paper, we argue that both targets and contexts deserve special treatment and need to be learned their own representations via interactive learning. Then, we propose the interactive attention networks (IAN) to interactively learn attentions in the contexts and targets, and generate the representations for targets and contexts separately. With this design, the IAN model can well represent a target and its collocative context, which is helpful to sentiment classification. Experimental results on SemEval 2014 Datasets demonstrate the effectiveness of our model.