 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFITMM: Adaptive Frequency-Aware Multimodal Recommendation via Information-Theoretic Representation Learning
Jan 30, 2026Multimodal recommendation aims to enhance user preference modeling by leveraging rich item content such as images and text. Yet dominant systems fuse modalities in the spatial domain, obscuring the frequency structure of signals and amplifying misalignment and redundancy. We adopt a spectral information-theoretic view and show that, under an orthogonal transform that approximately block-diagonalizes bandwise covariances, the Gaussian Information Bottleneck objective decouples across frequency bands, providing a principled basis for separate-then-fuse paradigm. Building on this foundation, we propose FITMM, a Frequency-aware Information-Theoretic framework for multimodal recommendation. FITMM constructs graph-enhanced item representations, performs modality-wise spectral decomposition to obtain orthogonal bands, and forms lightweight within-band multimodal components. A residual, task-adaptive gate aggregates bands into the final representation. To control redundancy and improve generalization, we regularize training with a frequency-domain IB term that allocates capacity across bands (Wiener-like shrinkage with shut-off of weak bands). We further introduce a cross-modal spectral consistency loss that aligns modalities within each band. The model is jointly optimized with the standard recommendation loss. Extensive experiments on three real-world datasets demonstrate that FITMM consistently and significantly outperforms advanced baselines.
Self-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning
Jan 29, 2026The inference overhead induced by redundant reasoning undermines the interactive experience and severely bottlenecks the deployment of Large Reasoning Models. Existing reinforcement learning (RL)-based solutions tackle this problem by coupling a length penalty with outcome-based rewards. This simplistic reward weighting struggles to reconcile brevity with accuracy, as enforcing brevity may compromise critical reasoning logic. In this work, we address this limitation by proposing a multi-agent RL framework that selectively penalizes redundant chunks, while preserving essential reasoning logic. Our framework, Self-Compression via MARL (SCMA), instantiates redundancy detection and evaluation through two specialized agents: \textbf{a Segmentation Agent} for decomposing the reasoning process into logical chunks, and \textbf{a Scoring Agent} for quantifying the significance of each chunk. The Segmentation and Scoring agents collaboratively define an importance-weighted length penalty during training, incentivizing \textbf{a Reasoning Agent} to prioritize essential logic without introducing inference overhead during deployment. Empirical evaluations across model scales demonstrate that SCMA reduces response length by 11.1\% to 39.0\% while boosting accuracy by 4.33\% to 10.02\%. Furthermore, ablation studies and qualitative analysis validate that the synergistic optimization within the MARL framework fosters emergent behaviors, yielding more powerful LRMs compared to vanilla RL paradigms.
JADE: Bridging the Strategic-Operational Gap in Dynamic Agentic RAG
Jan 29, 2026The evolution of Retrieval-Augmented Generation (RAG) has shifted from static retrieval pipelines to dynamic, agentic workflows where a central planner orchestrates multi-turn reasoning. However, existing paradigms face a critical dichotomy: they either optimize modules jointly within rigid, fixed-graph architectures, or empower dynamic planning while treating executors as frozen, black-box tools. We identify that this \textit{decoupled optimization} creates a ``strategic-operational mismatch,'' where sophisticated planning strategies fail to materialize due to unadapted local executors, often leading to negative performance gains despite increased system complexity. In this paper, we propose \textbf{JADE} (\textbf{J}oint \textbf{A}gentic \textbf{D}ynamic \textbf{E}xecution), a unified framework for the joint optimization of planning and execution within dynamic, multi-turn workflows. By modeling the system as a cooperative multi-agent team unified under a single shared backbone, JADE enables end-to-end learning driven by outcome-based rewards. This approach facilitates \textit{co-adaptation}: the planner learns to operate within the capability boundaries of the executors, while the executors evolve to align with high-level strategic intent. Empirical results demonstrate that JADE transforms disjoint modules into a synergistic system, yielding remarkable performance improvements via joint optimization and enabling a flexible balance between efficiency and effectiveness through dynamic workflow orchestration.
Beyond Monolithic Architectures: A Multi-Agent Search and Knowledge Optimization Framework for Agentic Search
Jan 08, 2026Agentic search has emerged as a promising paradigm for complex information seeking by enabling Large Language Models (LLMs) to interleave reasoning with tool use. However, prevailing systems rely on monolithic agents that suffer from structural bottlenecks, including unconstrained reasoning outputs that inflate trajectories, sparse outcome-level rewards that complicate credit assignment, and stochastic search noise that destabilizes learning. To address these challenges, we propose \textbf{M-ASK} (Multi-Agent Search and Knowledge), a framework that explicitly decouples agentic search into two complementary roles: Search Behavior Agents, which plan and execute search actions, and Knowledge Management Agents, which aggregate, filter, and maintain a compact internal context. This decomposition allows each agent to focus on a well-defined subtask and reduces interference between search and context construction. Furthermore, to enable stable coordination, M-ASK employs turn-level rewards to provide granular supervision for both search decisions and knowledge updates. Experiments on multi-hop QA benchmarks demonstrate that M-ASK outperforms strong baselines, achieving not only superior answer accuracy but also significantly more stable training dynamics.\footnote{The source code for M-ASK is available at https://github.com/chenyiqun/M-ASK.}
Leveraging LLMs to Evaluate Usefulness of Document
Jun 11, 2025The conventional Cranfield paradigm struggles to effectively capture user satisfaction due to its weak correlation between relevance and satisfaction, alongside the high costs of relevance annotation in building test collections. To tackle these issues, our research explores the potential of leveraging large language models (LLMs) to generate multilevel usefulness labels for evaluation. We introduce a new user-centric evaluation framework that integrates users' search context and behavioral data into LLMs. This framework uses a cascading judgment structure designed for multilevel usefulness assessments, drawing inspiration from ordinal regression techniques. Our study demonstrates that when well-guided with context and behavioral information, LLMs can accurately evaluate usefulness, allowing our approach to surpass third-party labeling methods. Furthermore, we conduct ablation studies to investigate the influence of key components within the framework. We also apply the labels produced by our method to predict user satisfaction, with real-world experiments indicating that these labels substantially improve the performance of satisfaction prediction models.
LLM4Ranking: An Easy-to-use Framework of Utilizing Large Language Models for Document Reranking
Apr 10, 2025



Utilizing large language models (LLMs) for document reranking has been a popular and promising research direction in recent years, many studies are dedicated to improving the performance and efficiency of using LLMs for reranking. Besides, it can also be applied in many real-world applications, such as search engines or retrieval-augmented generation. In response to the growing demand for research and application in practice, we introduce a unified framework, \textbf{LLM4Ranking}, which enables users to adopt different ranking methods using open-source or closed-source API-based LLMs. Our framework provides a simple and extensible interface for document reranking with LLMs, as well as easy-to-use evaluation and fine-tuning scripts for this task. We conducted experiments based on this framework and evaluated various models and methods on several widely used datasets, providing reproducibility results on utilizing LLMs for document reranking. Our code is publicly available at https://github.com/liuqi6777/llm4ranking.
Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement Learning
Jan 25, 2025



Retrieval-augmented generation (RAG) is extensively utilized to incorporate external, current knowledge into large language models, thereby minimizing hallucinations. A standard RAG pipeline may comprise several components, such as query rewriting, document retrieval, document filtering, and answer generation. However, these components are typically optimized separately through supervised fine-tuning, which can lead to misalignments between the objectives of individual modules and the overarching aim of generating accurate answers in question-answering (QA) tasks. Although recent efforts have explored reinforcement learning (RL) to optimize specific RAG components, these approaches often focus on overly simplistic pipelines with only two components or do not adequately address the complex interdependencies and collaborative interactions among the modules. To overcome these challenges, we propose treating the RAG pipeline as a multi-agent cooperative task, with each component regarded as an RL agent. Specifically, we present MMOA-RAG, a Multi-Module joint Optimization Algorithm for RAG, which employs multi-agent reinforcement learning to harmonize all agents' goals towards a unified reward, such as the F1 score of the final answer. Experiments conducted on various QA datasets demonstrate that MMOA-RAG improves the overall pipeline performance and outperforms existing baselines. Furthermore, comprehensive ablation studies validate the contributions of individual components and the adaptability of MMOA-RAG across different RAG components and datasets. The code of MMOA-RAG is on https://github.com/chenyiqun/MMOA-RAG.
TourRank: Utilizing Large Language Models for Documents Ranking with a Tournament-Inspired Strategy
Jun 17, 2024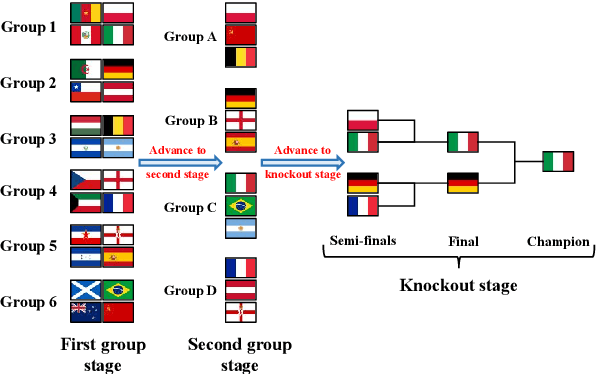


Large Language Models (LLMs) are increasingly employed in zero-shot documents ranking, yielding commendable results. However, several significant challenges still persist in LLMs for ranking: (1) LLMs are constrained by limited input length, precluding them from processing a large number of documents simultaneously; (2) The output document sequence is influenced by the input order of documents, resulting in inconsistent ranking outcomes; (3) Achieving a balance between cost and ranking performance is quite challenging. To tackle these issues, we introduce a novel documents ranking method called TourRank, which is inspired by the tournament mechanism. This approach alleviates the impact of LLM's limited input length through intelligent grouping, while the tournament-like points system ensures robust ranking, mitigating the influence of the document input sequence. We test TourRank with different LLMs on the TREC DL datasets and the BEIR benchmark. Experimental results show that TourRank achieves state-of-the-art performance at a reasonable cost.
MA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
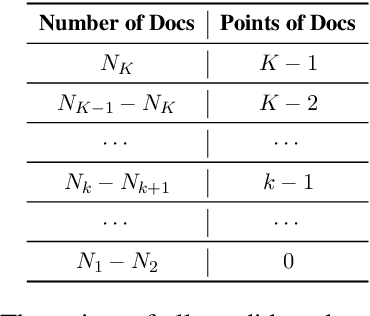
Mar 27, 2024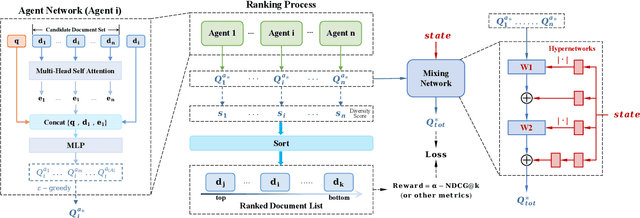

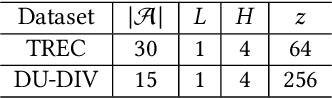
The objective of search result diversification (SRD) is to ensure that selected documents cover as many different subtopics as possible. Existing methods primarily utilize a paradigm of "greedy selection", i.e., selecting one document with the highest diversity score at a time. These approaches tend to be inefficient and are easily trapped in a suboptimal state. In addition, some other methods aim to approximately optimize the diversity metric, such as $\alpha$-NDCG, but the results still remain suboptimal. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. This approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted preliminary experiments on public TREC datasets to demonstrate the effectiveness and potential of MA4DIV. Considering the limited number of queries in public TREC datasets, we construct a large-scale dataset from industry sources and show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines on a industrial scale dataset.
What's documented in AI? Systematic Analysis of 32K AI Model Cards
Feb 07, 2024The rapid proliferation of AI models has underscored the importance of thorough documentation, as it enables users to understand, trust, and effectively utilize these models in various applications. Although developers are encouraged to produce model cards, it's not clear how much information or what information these cards contain. In this study, we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most of the AI models with substantial downloads provide model cards, though the cards have uneven informativeness. We find that sections addressing environmental impact, limitations, and evaluation exhibit the lowest filled-out rates, while the training section is the most consistently filled-out. We analyze the content of each section to characterize practitioners' priorities. Interestingly, there are substantial discussions of data, sometimes with equal or even greater emphasis than the model itself. To evaluate the impact of model cards, we conducted an intervention study by adding detailed model cards to 42 popular models which had no or sparse model cards previously. We find that adding model cards is moderately correlated with an increase weekly download rates. Our study opens up a new perspective for analyzing community norms and practices for model documentation through large-scale data science and linguistics analysis.