 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA4DIV: Multi-Agent Reinforcement Learning for Search Result Diversification
Mar 27, 2024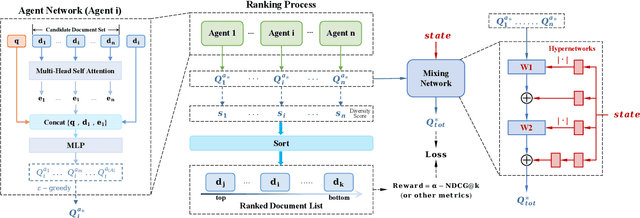

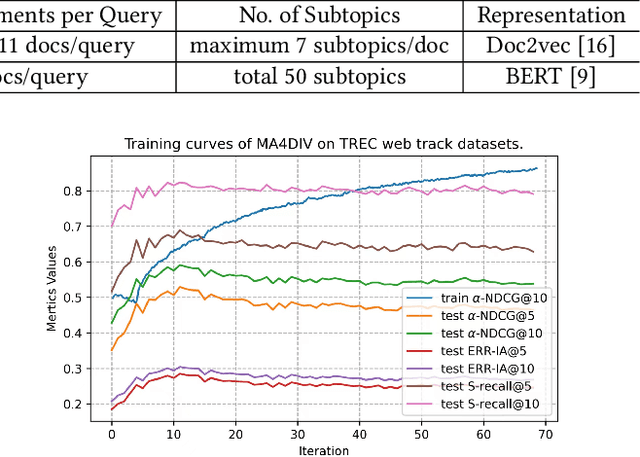
The objective of search result diversification (SRD) is to ensure that selected documents cover as many different subtopics as possible. Existing methods primarily utilize a paradigm of "greedy selection", i.e., selecting one document with the highest diversity score at a time. These approaches tend to be inefficient and are easily trapped in a suboptimal state. In addition, some other methods aim to approximately optimize the diversity metric, such as $\alpha$-NDCG, but the results still remain suboptimal. To address these challenges, we introduce Multi-Agent reinforcement learning (MARL) for search result DIVersity, which called MA4DIV. In this approach, each document is an agent and the search result diversification is modeled as a cooperative task among multiple agents. This approach allows for directly optimizing the diversity metrics, such as $\alpha$-NDCG, while achieving high training efficiency. We conducted preliminary experiments on public TREC datasets to demonstrate the effectiveness and potential of MA4DIV. Considering the limited number of queries in public TREC datasets, we construct a large-scale dataset from industry sources and show that MA4DIV achieves substantial improvements in both effectiveness and efficiency than existing baselines on a industrial scale dataset.
Pretrained Language Model based Web Search Ranking: From Relevance to Satisfaction
Jun 02, 2023



Search engine plays a crucial role in satisfying users' diverse information needs. Recently, Pretrained Language Models (PLMs) based text ranking models have achieved huge success in web search. However, many state-of-the-art text ranking approaches only focus on core relevance while ignoring other dimensions that contribute to user satisfaction, e.g., document quality, recency, authority, etc. In this work, we focus on ranking user satisfaction rather than relevance in web search, and propose a PLM-based framework, namely SAT-Ranker, which comprehensively models different dimensions of user satisfaction in a unified manner. In particular, we leverage the capacities of PLMs on both textual and numerical inputs, and apply a multi-field input that modularizes each dimension of user satisfaction as an input field. Overall, SAT-Ranker is an effective, extensible, and data-centric framework that has huge potential for industrial applications. On rigorous offline and online experiments, SAT-Ranker obtains remarkable gains on various evaluation sets targeting different dimensions of user satisfaction. It is now fully deployed online to improve the usability of our search engine.
PILE: Pairwise Iterative Logits Ensemble for Multi-Teacher Labeled Distillation
Nov 11, 2022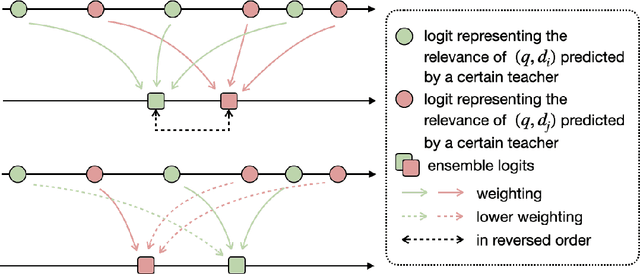

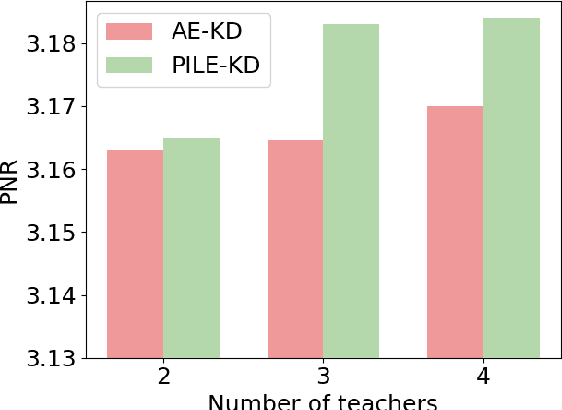
Pre-trained language models have become a crucial part of ranking systems and achieved very impressive effects recently. To maintain high performance while keeping efficient computations, knowledge distillation is widely used. In this paper, we focus on two key questions in knowledge distillation for ranking models: 1) how to ensemble knowledge from multi-teacher; 2) how to utilize the label information of data in the distillation process. We propose a unified algorithm called Pairwise Iterative Logits Ensemble (PILE) to tackle these two questions simultaneously. PILE ensembles multi-teacher logits supervised by label information in an iterative way and achieved competitive performance in both offline and online experiments. The proposed method has been deployed in a real-world commercial search system.
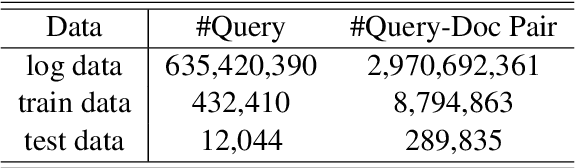
CPS-MEBR: Click Feedback-Aware Web Page Summarization for Multi-Embedding-Based Retrieval
Oct 19, 2022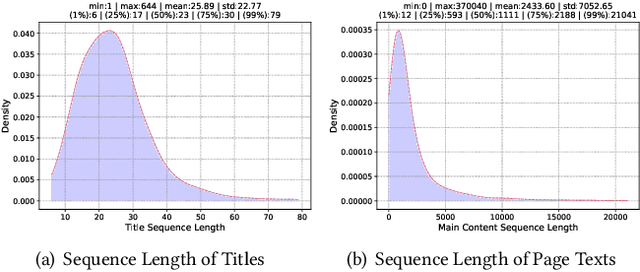
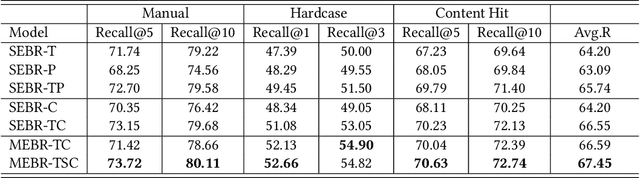

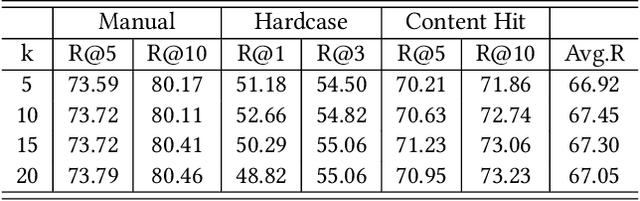
Embedding-based retrieval (EBR) is a technique to use embeddings to represent query and document, and then convert the retrieval problem into a nearest neighbor search problem in the embedding space. Some previous works have mainly focused on representing the web page with a single embedding, but in real web search scenarios, it is difficult to represent all the information of a long and complex structured web page as a single embedding. To address this issue, we design a click feedback-aware web page summarization for multi-embedding-based retrieval (CPS-MEBR) framework which is able to generate multiple embeddings for web pages to match different potential queries. Specifically, we use the click data of users in search logs to train a summary model to extract those sentences in web pages that are frequently clicked by users, which are more likely to answer those potential queries. Meanwhile, we introduce sentence-level semantic interaction to design a multi-embedding-based retrieval (MEBR) model, which can generate multiple embeddings to deal with different potential queries by using frequently clicked sentences in web pages. Offline experiments show that it can perform high quality candidate retrieval compared to single-embedding-based retrieval (SEBR) model.
Approximated Doubly Robust Search Relevance Estimation
Aug 16, 2022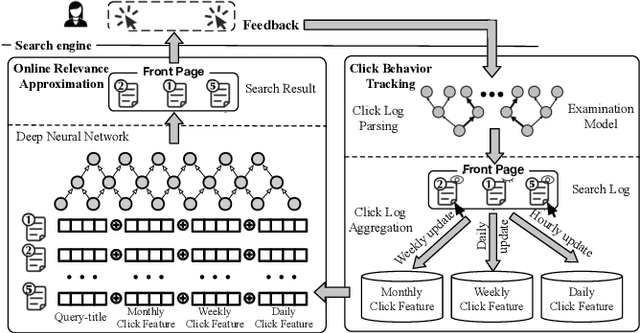
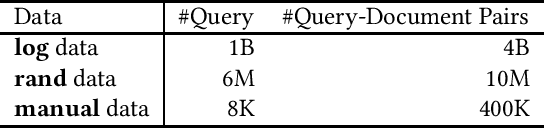
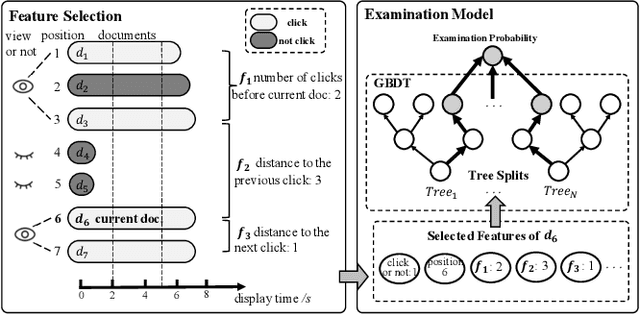
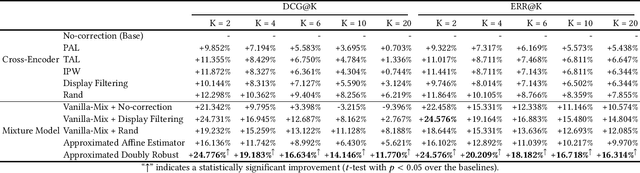
Extracting query-document relevance from the sparse, biased clickthrough log is among the most fundamental tasks in the web search system. Prior art mainly learns a relevance judgment model with semantic features of the query and document and ignores directly counterfactual relevance evaluation from the clicking log. Though the learned semantic matching models can provide relevance signals for tail queries as long as the semantic feature is available. However, such a paradigm lacks the capability to introspectively adjust the biased relevance estimation whenever it conflicts with massive implicit user feedback. The counterfactual evaluation methods, on the contrary, ensure unbiased relevance estimation with sufficient click information. However, they suffer from the sparse or even missing clicks caused by the long-tailed query distribution. In this paper, we propose to unify the counterfactual evaluating and learning approaches for unbiased relevance estimation on search queries with various popularities. Specifically, we theoretically develop a doubly robust estimator with low bias and variance, which intentionally combines the benefits of existing relevance evaluating and learning approaches. We further instantiate the proposed unbiased relevance estimation framework in Baidu search, with comprehensive practical solutions designed regarding the data pipeline for click behavior tracking and online relevance estimation with an approximated deep neural network. Finally, we present extensive empirical evaluations to verify the effectiveness of our proposed framework, finding that it is robust in practice and manages to improve online ranking performance substantially.
* 10 pages