 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILL: Mutual Verification with Large Language Models for Zero-Shot Query Expansion
Oct 29, 2023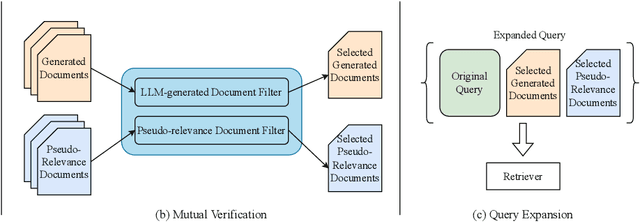
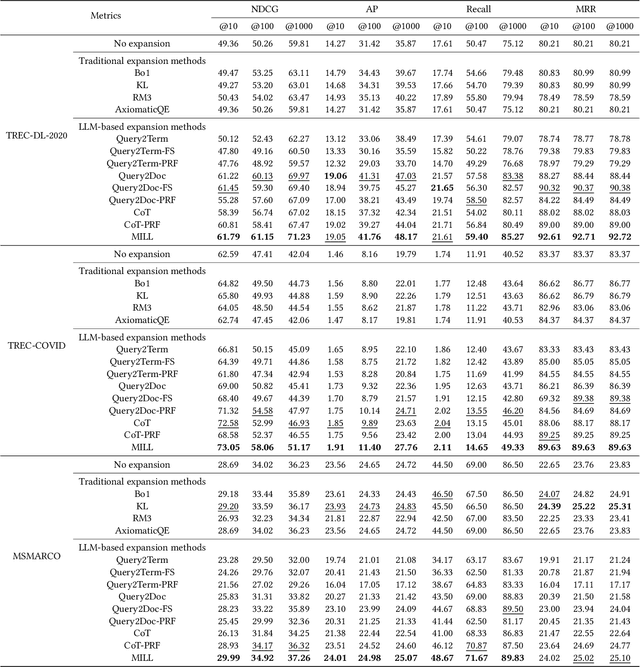

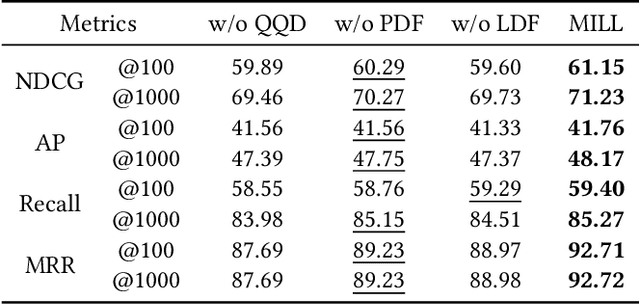
Query expansion is a commonly-used technique in many search systems to better represent users' information needs with additional query terms. Existing studies for this task usually propose to expand a query with retrieved or generated contextual documents. However, both types of methods have clear limitations. For retrieval-based methods, the documents retrieved with the original query might not be accurate enough to reveal the search intent, especially when the query is brief or ambiguous. For generation-based methods, existing models can hardly be trained or aligned on a particular corpus, due to the lack of corpus-specific labeled data. In this paper, we propose a novel Large Language Model (LLM) based mutual verification framework for query expansion, which alleviates the aforementioned limitations. Specifically, we first design a query-query-document generation pipeline, which can effectively leverage the contextual knowledge encoded in LLMs to generate sub-queries and corresponding documents from multiple perspectives. Next, we employ a mutual verification method for both generated and retrieved contextual documents, where 1) retrieved documents are filtered with the external contextual knowledge in generated documents, and 2) generated documents are filtered with the corpus-specific knowledge in retrieved documents. Overall, the proposed method allows retrieved and generated documents to complement each other to finalize a better query expansion. We conduct extensive experiments on three information retrieval datasets, i.e., TREC-DL-2020, TREC-COVID, and MSMARCO. The results demonstrate that our method outperforms other baselines significantly.
Approximated Doubly Robust Search Relevance Estimation
Aug 16, 2022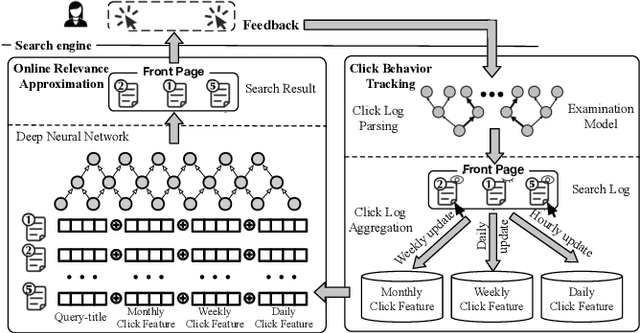
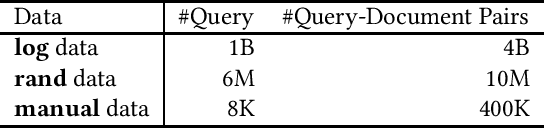
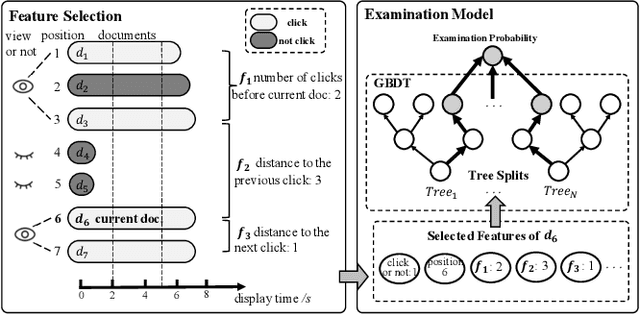
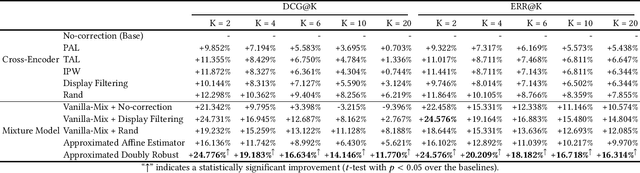
Extracting query-document relevance from the sparse, biased clickthrough log is among the most fundamental tasks in the web search system. Prior art mainly learns a relevance judgment model with semantic features of the query and document and ignores directly counterfactual relevance evaluation from the clicking log. Though the learned semantic matching models can provide relevance signals for tail queries as long as the semantic feature is available. However, such a paradigm lacks the capability to introspectively adjust the biased relevance estimation whenever it conflicts with massive implicit user feedback. The counterfactual evaluation methods, on the contrary, ensure unbiased relevance estimation with sufficient click information. However, they suffer from the sparse or even missing clicks caused by the long-tailed query distribution. In this paper, we propose to unify the counterfactual evaluating and learning approaches for unbiased relevance estimation on search queries with various popularities. Specifically, we theoretically develop a doubly robust estimator with low bias and variance, which intentionally combines the benefits of existing relevance evaluating and learning approaches. We further instantiate the proposed unbiased relevance estimation framework in Baidu search, with comprehensive practical solutions designed regarding the data pipeline for click behavior tracking and online relevance estimation with an approximated deep neural network. Finally, we present extensive empirical evaluations to verify the effectiveness of our proposed framework, finding that it is robust in practice and manages to improve online ranking performance substantially.
* 10 pages
Sketch and Customize: A Counterfactual Story Generator
Apr 02, 2021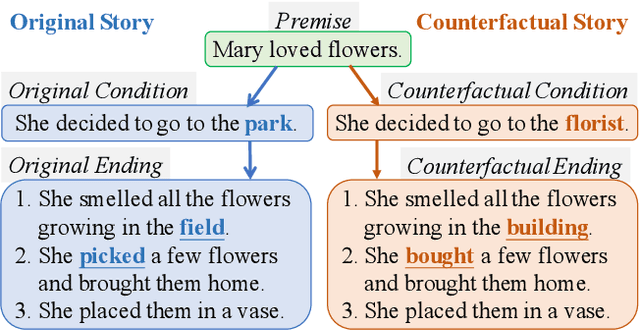
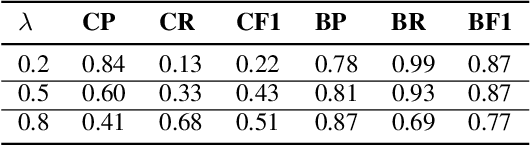
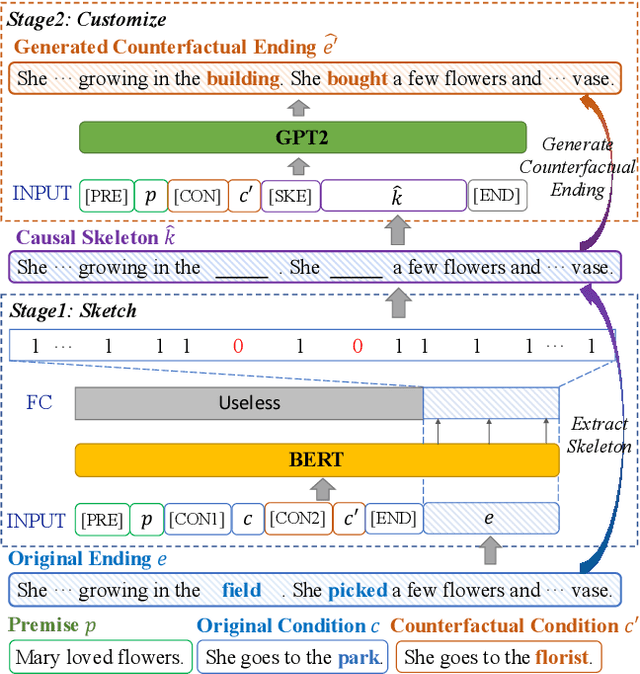
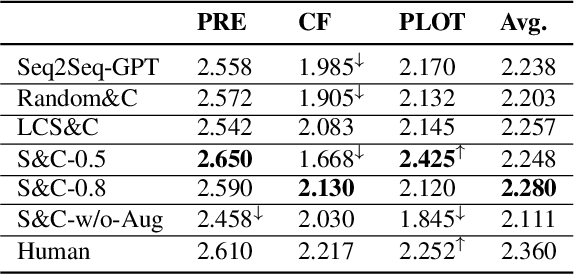
Recent text generation models are easy to generate relevant and fluent text for the given text, while lack of causal reasoning ability when we change some parts of the given text. Counterfactual story rewriting is a recently proposed task to test the causal reasoning ability for text generation models, which requires a model to predict the corresponding story ending when the condition is modified to a counterfactual one. Previous works have shown that the traditional sequence-to-sequence model cannot well handle this problem, as it often captures some spurious correlations between the original and counterfactual endings, instead of the causal relations between conditions and endings. To address this issue, we propose a sketch-and-customize generation model guided by the causality implicated in the conditions and endings. In the sketch stage, a skeleton is extracted by removing words which are conflict to the counterfactual condition, from the original ending. In the customize stage, a generation model is used to fill proper words in the skeleton under the guidance of the counterfactual condition. In this way, the obtained counterfactual ending is both relevant to the original ending and consistent with the counterfactual condition. Experimental results show that the proposed model generates much better endings, as compared with the traditional sequence-to-sequence model.
Ranking Enhanced Dialogue Generation
Aug 13, 2020

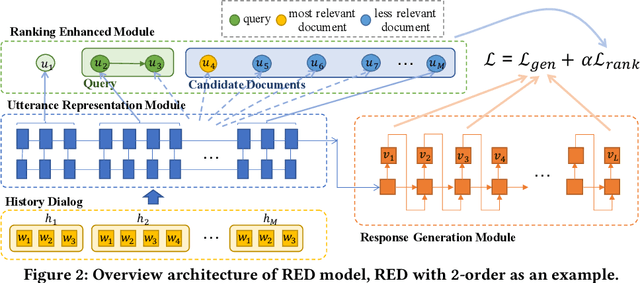
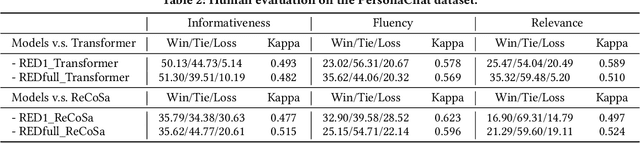
How to effectively utilize the dialogue history is a crucial problem in multi-turn dialogue generation. Previous works usually employ various neural network architectures (e.g., recurrent neural networks, attention mechanisms, and hierarchical structures) to model the history. However, a recent empirical study by Sankar et al. has shown that these architectures lack the ability of understanding and modeling the dynamics of the dialogue history. For example, the widely used architectures are insensitive to perturbations of the dialogue history, such as words shuffling, utterances missing, and utterances reordering. To tackle this problem, we propose a Ranking Enhanced Dialogue generation framework in this paper. Despite the traditional representation encoder and response generation modules, an additional ranking module is introduced to model the ranking relation between the former utterance and consecutive utterances. Specifically, the former utterance and consecutive utterances are treated as query and corresponding documents, and both local and global ranking losses are designed in the learning process. In this way, the dynamics in the dialogue history can be explicitly captured. To evaluate our proposed models, we conduct extensive experiments on three public datasets, i.e., bAbI, PersonaChat, and JDC. Experimental results show that our models produce better responses in terms of both quantitative measures and human judgments, as compared with the state-of-the-art dialogue generation models. Furthermore, we give some detailed experimental analysis to show where and how the improvements come from.