 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Gets Flagged? The Pluralistic Evaluation Gap in AI Content Watermarking
Apr 15, 2026Watermarking is becoming the default mechanism for AI content authentication, with governance policies and frameworks referencing it as infrastructure for content provenance. Yet across text, image, and audio modalities, watermark signal strength, detectability, and robustness depend on statistical properties of the content itself, properties that vary systematically across languages, cultural visual traditions, and demographic groups. We examine how this content dependence creates modality-specific pathways to bias. Reviewing the major watermarking benchmarks across modalities, we find that, with one exception, none report performance across languages, cultural content types, or population groups. To address this, we propose three concrete evaluation dimensions for pluralistic watermark benchmarking: cross-lingual detection parity, culturally diverse content coverage, and demographic disaggregation of detection metrics. We connect these to the governance frameworks currently mandating watermarking deployment and show that watermarking is held to a lower fairness standard than the generative systems it is meant to govern. Our position is that evaluation must precede deployment, and that the same bias auditing requirements applied to AI models should extend to the verification layer.
Quantifying Memorization and Privacy Risks in Genomic Language Models
Mar 09, 2026Genomic language models (GLMs) have emerged as powerful tools for learning representations of DNA sequences, enabling advances in variant prediction, regulatory element identification, and cross-task transfer learning. However, as these models are increasingly trained or fine-tuned on sensitive genomic cohorts, they risk memorizing specific sequences from their training data, raising serious concerns around privacy, data leakage, and regulatory compliance. Despite growing awareness of memorization risks in general-purpose language models, little systematic evaluation exists for these risks in the genomic domain, where data exhibit unique properties such as a fixed nucleotide alphabet, strong biological structure, and individual identifiability. We present a comprehensive, multi-vector privacy evaluation framework designed to quantify memorization risks in GLMs. Our approach integrates three complementary risk assessment methodologies: perplexity-based detection, canary sequence extraction, and membership inference. These are combined into a unified evaluation pipeline that produces a worst-case memorization risk score. To enable controlled evaluation, we plant canary sequences at varying repetition rates into both synthetic and real genomic datasets, allowing precise quantification of how repetition and training dynamics influence memorization. We evaluate our framework across multiple GLM architectures, examining the relationship between sequence repetition, model capacity, and memorization risk. Our results establish that GLMs exhibit measurable memorization and that the degree of memorization varies across architectures and training regimes. These findings reveal that no single attack vector captures the full scope of memorization risk, underscoring the need for multi-vector privacy auditing as a standard practice for genomic AI systems.
Privacy-Preserving Model and Preprocessing Verification for Machine Learning
Jan 14, 2025
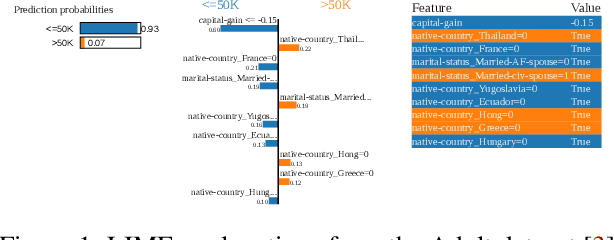
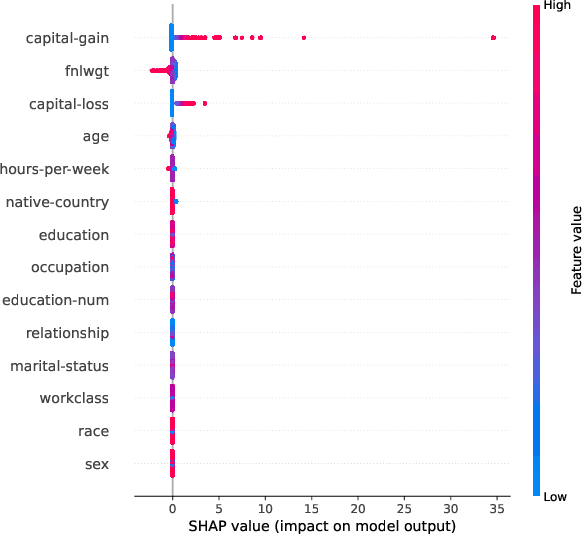
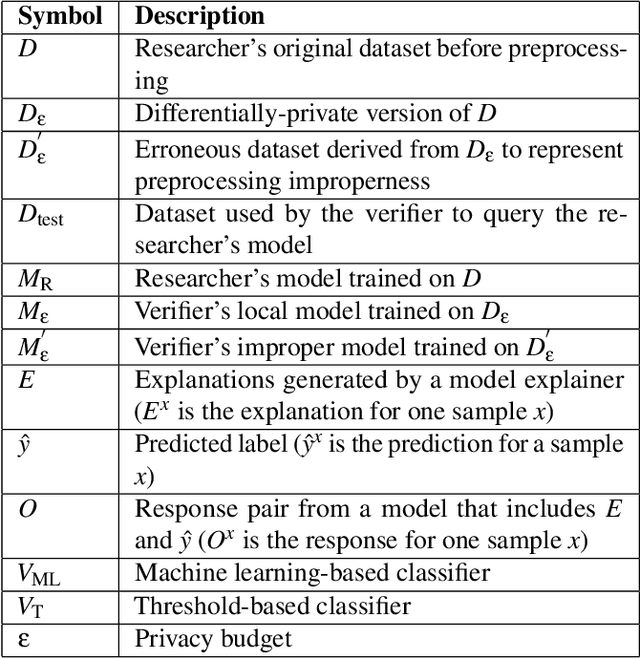
This paper presents a framework for privacy-preserving verification of machine learning models, focusing on models trained on sensitive data. Integrating Local Differential Privacy (LDP) with model explanations from LIME and SHAP, our framework enables robust verification without compromising individual privacy. It addresses two key tasks: binary classification, to verify if a target model was trained correctly by applying the appropriate preprocessing steps, and multi-class classification, to identify specific preprocessing errors. Evaluations on three real-world datasets-Diabetes, Adult, and Student Record-demonstrate that while the ML-based approach is particularly effective in binary tasks, the threshold-based method performs comparably in multi-class tasks. Results indicate that although verification accuracy varies across datasets and noise levels, the framework provides effective detection of preprocessing errors, strong privacy guarantees, and practical applicability for safeguarding sensitive data.
Exploring the Cognitive Dynamics of Artificial Intelligence in the Post-COVID-19 and Learning 3.0 Era: A Case Study of ChatGPT
Feb 03, 2023The emergence of artificial intelligence has incited a paradigm shift across the spectrum of human endeavors, with ChatGPT serving as a catalyst for the transformation of various established domains, including but not limited to education, journalism, security, and ethics. In the post-pandemic era, the widespread adoption of remote work has prompted the educational sector to reassess conventional pedagogical methods. This paper is to scrutinize the underlying psychological principles of ChatGPT, delve into the factors that captivate user attention, and implicate its ramifications on the future of learning. The ultimate objective of this study is to instigate a scholarly discourse on the interplay between technological advancements in education and the evolution of human learning patterns, raising the question of whether technology is driving human evolution or vice versa.
CPS-MEBR: Click Feedback-Aware Web Page Summarization for Multi-Embedding-Based Retrieval
Oct 19, 2022
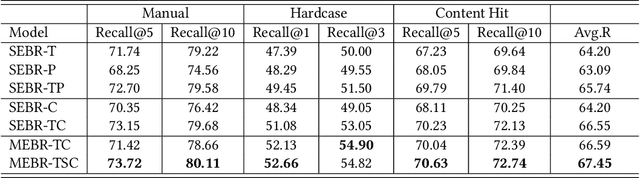

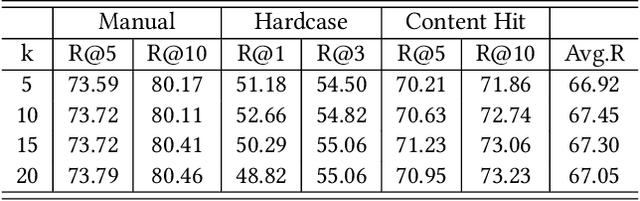
Embedding-based retrieval (EBR) is a technique to use embeddings to represent query and document, and then convert the retrieval problem into a nearest neighbor search problem in the embedding space. Some previous works have mainly focused on representing the web page with a single embedding, but in real web search scenarios, it is difficult to represent all the information of a long and complex structured web page as a single embedding. To address this issue, we design a click feedback-aware web page summarization for multi-embedding-based retrieval (CPS-MEBR) framework which is able to generate multiple embeddings for web pages to match different potential queries. Specifically, we use the click data of users in search logs to train a summary model to extract those sentences in web pages that are frequently clicked by users, which are more likely to answer those potential queries. Meanwhile, we introduce sentence-level semantic interaction to design a multi-embedding-based retrieval (MEBR) model, which can generate multiple embeddings to deal with different potential queries by using frequently clicked sentences in web pages. Offline experiments show that it can perform high quality candidate retrieval compared to single-embedding-based retrieval (SEBR) model.
A Unified Neural Network Model for Readability Assessment with Feature Projection and Length-Balanced Loss
Oct 19, 2022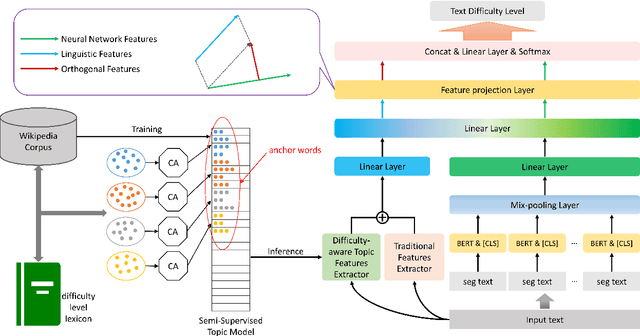
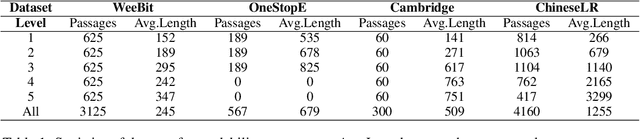

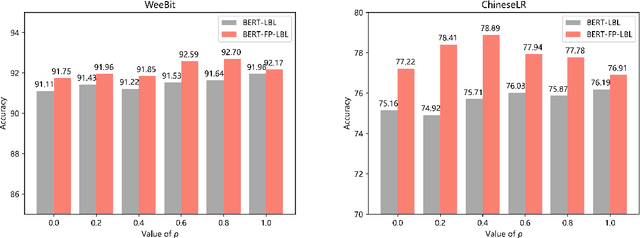
For readability assessment, traditional methods mainly employ machine learning classifiers with hundreds of linguistic features. Although the deep learning model has become the prominent approach for almost all NLP tasks, it is less explored for readability assessment. In this paper, we propose a BERT-based model with feature projection and length-balanced loss (BERT-FP-LBL) for readability assessment. Specially, we present a new difficulty knowledge guided semi-supervised method to extract topic features to complement the traditional linguistic features. From the linguistic features, we employ projection filtering to extract orthogonal features to supplement BERT representations. Furthermore, we design a new length-balanced loss to handle the greatly varying length distribution of data. Our model achieves state-of-the-art performances on two English benchmark datasets and one dataset of Chinese textbooks, and also achieves the near-perfect accuracy of 99\% on one English dataset. Moreover, our proposed model obtains comparable results with human experts in consistency test.
Exploiting Word Semantics to Enrich Character Representations of Chinese Pre-trained Models
Jul 13, 2022

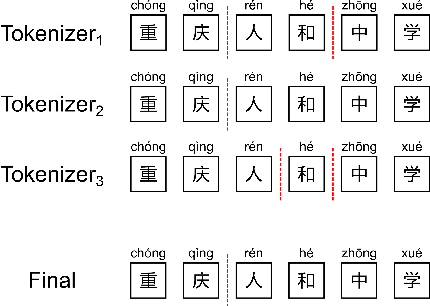
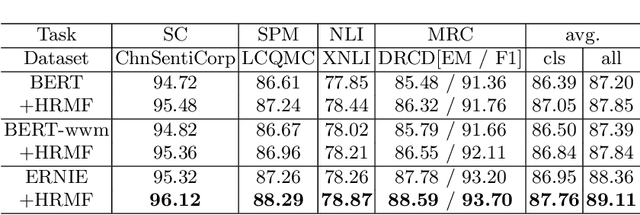
Most of the Chinese pre-trained models adopt characters as basic units for downstream tasks. However, these models ignore the information carried by words and thus lead to the loss of some important semantics. In this paper, we propose a new method to exploit word structure and integrate lexical semantics into character representations of pre-trained models. Specifically, we project a word's embedding into its internal characters' embeddings according to the similarity weight. To strengthen the word boundary information, we mix the representations of the internal characters within a word. After that, we apply a word-to-character alignment attention mechanism to emphasize important characters by masking unimportant ones. Moreover, in order to reduce the error propagation caused by word segmentation, we present an ensemble approach to combine segmentation results given by different tokenizers. The experimental results show that our approach achieves superior performance over the basic pre-trained models BERT, BERT-wwm and ERNIE on different Chinese NLP tasks: sentiment classification, sentence pair matching, natural language inference and machine reading comprehension. We make further analysis to prove the effectiveness of each component of our model.