 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Word Semantics to Enrich Character Representations of Chinese Pre-trained Models
Paper and Code


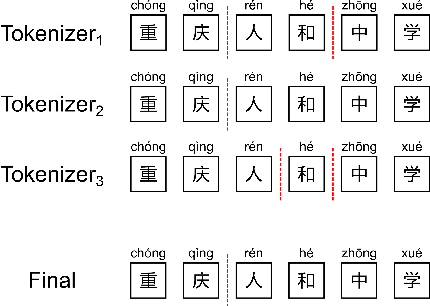
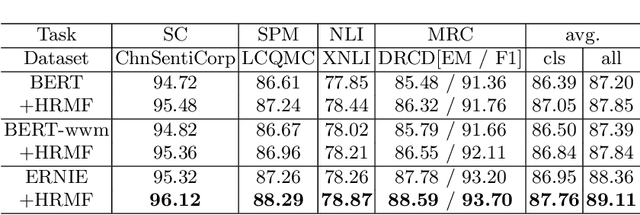
Most of the Chinese pre-trained models adopt characters as basic units for downstream tasks. However, these models ignore the information carried by words and thus lead to the loss of some important semantics. In this paper, we propose a new method to exploit word structure and integrate lexical semantics into character representations of pre-trained models. Specifically, we project a word's embedding into its internal characters' embeddings according to the similarity weight. To strengthen the word boundary information, we mix the representations of the internal characters within a word. After that, we apply a word-to-character alignment attention mechanism to emphasize important characters by masking unimportant ones. Moreover, in order to reduce the error propagation caused by word segmentation, we present an ensemble approach to combine segmentation results given by different tokenizers. The experimental results show that our approach achieves superior performance over the basic pre-trained models BERT, BERT-wwm and ERNIE on different Chinese NLP tasks: sentiment classification, sentence pair matching, natural language inference and machine reading comprehension. We make further analysis to prove the effectiveness of each component of our model.