 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Gets Flagged? The Pluralistic Evaluation Gap in AI Content Watermarking
Apr 15, 2026Watermarking is becoming the default mechanism for AI content authentication, with governance policies and frameworks referencing it as infrastructure for content provenance. Yet across text, image, and audio modalities, watermark signal strength, detectability, and robustness depend on statistical properties of the content itself, properties that vary systematically across languages, cultural visual traditions, and demographic groups. We examine how this content dependence creates modality-specific pathways to bias. Reviewing the major watermarking benchmarks across modalities, we find that, with one exception, none report performance across languages, cultural content types, or population groups. To address this, we propose three concrete evaluation dimensions for pluralistic watermark benchmarking: cross-lingual detection parity, culturally diverse content coverage, and demographic disaggregation of detection metrics. We connect these to the governance frameworks currently mandating watermarking deployment and show that watermarking is held to a lower fairness standard than the generative systems it is meant to govern. Our position is that evaluation must precede deployment, and that the same bias auditing requirements applied to AI models should extend to the verification layer.
Quantifying Memorization and Privacy Risks in Genomic Language Models
Mar 09, 2026Genomic language models (GLMs) have emerged as powerful tools for learning representations of DNA sequences, enabling advances in variant prediction, regulatory element identification, and cross-task transfer learning. However, as these models are increasingly trained or fine-tuned on sensitive genomic cohorts, they risk memorizing specific sequences from their training data, raising serious concerns around privacy, data leakage, and regulatory compliance. Despite growing awareness of memorization risks in general-purpose language models, little systematic evaluation exists for these risks in the genomic domain, where data exhibit unique properties such as a fixed nucleotide alphabet, strong biological structure, and individual identifiability. We present a comprehensive, multi-vector privacy evaluation framework designed to quantify memorization risks in GLMs. Our approach integrates three complementary risk assessment methodologies: perplexity-based detection, canary sequence extraction, and membership inference. These are combined into a unified evaluation pipeline that produces a worst-case memorization risk score. To enable controlled evaluation, we plant canary sequences at varying repetition rates into both synthetic and real genomic datasets, allowing precise quantification of how repetition and training dynamics influence memorization. We evaluate our framework across multiple GLM architectures, examining the relationship between sequence repetition, model capacity, and memorization risk. Our results establish that GLMs exhibit measurable memorization and that the degree of memorization varies across architectures and training regimes. These findings reveal that no single attack vector captures the full scope of memorization risk, underscoring the need for multi-vector privacy auditing as a standard practice for genomic AI systems.
Authenticated Contradictions from Desynchronized Provenance and Watermarking
Mar 02, 2026Cryptographic provenance standards such as C2PA and invisible watermarking are positioned as complementary defenses for content authentication, yet the two verification layers are technically independent: neither conditions on the output of the other. This work formalizes and empirically demonstrates the $\textit{Integrity Clash}$, a condition in which a digital asset carries a cryptographically valid C2PA manifest asserting human authorship while its pixels simultaneously carry a watermark identifying it as AI-generated, with both signals passing their respective verification checks in isolation. We construct metadata washing workflows that produce these authenticated fakes through standard editing pipelines, requiring no cryptographic compromise, only the semantic omission of a single assertion field permitted by the current C2PA specification. To close this gap, we propose a cross-layer audit protocol that jointly evaluates provenance metadata and watermark detection status, achieving 100% classification accuracy across 3,500 test images spanning four conflict-matrix states and three realistic perturbation conditions. Our results demonstrate that the gap between these verification layers is unnecessary and technically straightforward to close.
LoMime: Query-Efficient Membership Inference using Model Extraction in Label-Only Settings
Feb 21, 2026Membership inference attacks (MIAs) threaten the privacy of machine learning models by revealing whether a specific data point was used during training. Existing MIAs often rely on impractical assumptions such as access to public datasets, shadow models, confidence scores, or training data distribution knowledge and making them vulnerable to defenses like confidence masking and adversarial regularization. Label-only MIAs, even under strict constraints suffer from high query requirements per sample. We propose a cost-effective label-only MIA framework based on transferability and model extraction. By querying the target model M using active sampling, perturbation-based selection, and synthetic data, we extract a functionally similar surrogate S on which membership inference is performed. This shifts query overhead to a one-time extraction phase, eliminating repeated queries to M . Operating under strict black-box constraints, our method matches the performance of state-of-the-art label-only MIAs while significantly reducing query costs. On benchmarks including Purchase, Location, and Texas Hospital, we show that a query budget equivalent to testing $\approx1\%$ of training samples suffices to extract S and achieve membership inference accuracy within $\pm1\%$ of M . We also evaluate the effectiveness of standard defenses proposed for label-only MIAs against our attack.
Privacy-Preserving AI-Enabled Decentralized Learning and Employment Records System
Jan 06, 2026Learning and Employment Record (LER) systems are emerging as critical infrastructure for securely compiling and sharing educational and work achievements. Existing blockchain-based platforms leverage verifiable credentials but typically lack automated skill-credential generation and the ability to incorporate unstructured evidence of learning. In this paper,a privacy-preserving, AI-enabled decentralized LER system is proposed to address these gaps. Digitally signed transcripts from educational institutions are accepted, and verifiable self-issued skill credentials are derived inside a trusted execution environment (TEE) by a natural language processing pipeline that analyzes formal records (e.g., transcripts, syllabi) and informal artifacts. All verification and job-skill matching are performed inside the enclave with selective disclosure, so raw credentials and private keys remain enclave-confined. Job matching relies solely on attested skill vectors and is invariant to non-skill resume fields, thereby reducing opportunities for screening bias.The NLP component was evaluated on sample learner data; the mapping follows the validated Syllabus-to-O*NET methodology,and a stability test across repeated runs observed <5% variance in top-ranked skills. Formal security statements and proof sketches are provided showing that derived credentials are unforgeable and that sensitive information remains confidential. The proposed system thus supports secure education and employment credentialing, robust transcript verification,and automated, privacy-preserving skill extraction within a decentralized framework.
Comparing Reconstruction Attacks on Pretrained Versus Full Fine-tuned Large Language Model Embeddings on Homo Sapiens Splice Sites Genomic Data
Nov 09, 2025This study investigates embedding reconstruction attacks in large language models (LLMs) applied to genomic sequences, with a specific focus on how fine-tuning affects vulnerability to these attacks. Building upon Pan et al.'s seminal work demonstrating that embeddings from pretrained language models can leak sensitive information, we conduct a comprehensive analysis using the HS3D genomic dataset to determine whether task-specific optimization strengthens or weakens privacy protections. Our research extends Pan et al.'s work in three significant dimensions. First, we apply their reconstruction attack pipeline to pretrained and fine-tuned model embeddings, addressing a critical gap in their methodology that did not specify embedding types. Second, we implement specialized tokenization mechanisms tailored specifically for DNA sequences, enhancing the model's ability to process genomic data, as these models are pretrained on natural language and not DNA. Third, we perform a detailed comparative analysis examining position-specific, nucleotide-type, and privacy changes between pretrained and fine-tuned embeddings. We assess embeddings vulnerabilities across different types and dimensions, providing deeper insights into how task adaptation shifts privacy risks throughout genomic sequences. Our findings show a clear distinction in reconstruction vulnerability between pretrained and fine-tuned embeddings. Notably, fine-tuning strengthens resistance to reconstruction attacks in multiple architectures -- XLNet (+19.8\%), GPT-2 (+9.8\%), and BERT (+7.8\%) -- pointing to task-specific optimization as a potential privacy enhancement mechanism. These results highlight the need for advanced protective mechanisms for language models processing sensitive genomic data, while highlighting fine-tuning as a potential privacy-enhancing technique worth further exploration.
ZKPROV: A Zero-Knowledge Approach to Dataset Provenance for Large Language Models
Jun 26, 2025As the deployment of large language models (LLMs) grows in sensitive domains, ensuring the integrity of their computational provenance becomes a critical challenge, particularly in regulated sectors such as healthcare, where strict requirements are applied in dataset usage. We introduce ZKPROV, a novel cryptographic framework that enables zero-knowledge proofs of LLM provenance. It allows users to verify that a model is trained on a reliable dataset without revealing sensitive information about it or its parameters. Unlike prior approaches that focus on complete verification of the training process (incurring significant computational cost) or depend on trusted execution environments, ZKPROV offers a distinct balance. Our method cryptographically binds a trained model to its authorized training dataset(s) through zero-knowledge proofs while avoiding proof of every training step. By leveraging dataset-signed metadata and compact model parameter commitments, ZKPROV provides sound and privacy-preserving assurances that the result of the LLM is derived from a model trained on the claimed authorized and relevant dataset. Experimental results demonstrate the efficiency and scalability of the ZKPROV in generating this proof and verifying it, achieving a practical solution for real-world deployments. We also provide formal security guarantees, proving that our approach preserves dataset confidentiality while ensuring trustworthy dataset provenance.
Empowering Digital Agriculture: A Privacy-Preserving Framework for Data Sharing and Collaborative Research
Jun 25, 2025Data-driven agriculture, which integrates technology and data into agricultural practices, has the potential to improve crop yield, disease resilience, and long-term soil health. However, privacy concerns, such as adverse pricing, discrimination, and resource manipulation, deter farmers from sharing data, as it can be used against them. To address this barrier, we propose a privacy-preserving framework that enables secure data sharing and collaboration for research and development while mitigating privacy risks. The framework combines dimensionality reduction techniques (like Principal Component Analysis (PCA)) and differential privacy by introducing Laplacian noise to protect sensitive information. The proposed framework allows researchers to identify potential collaborators for a target farmer and train personalized machine learning models either on the data of identified collaborators via federated learning or directly on the aggregated privacy-protected data. It also allows farmers to identify potential collaborators based on similarities. We have validated this on real-life datasets, demonstrating robust privacy protection against adversarial attacks and utility performance comparable to a centralized system. We demonstrate how this framework can facilitate collaboration among farmers and help researchers pursue broader research objectives. The adoption of the framework can empower researchers and policymakers to leverage agricultural data responsibly, paving the way for transformative advances in data-driven agriculture. By addressing critical privacy challenges, this work supports secure data integration, fostering innovation and sustainability in agricultural systems.
The Feasibility of Topic-Based Watermarking on Academic Peer Reviews
May 27, 2025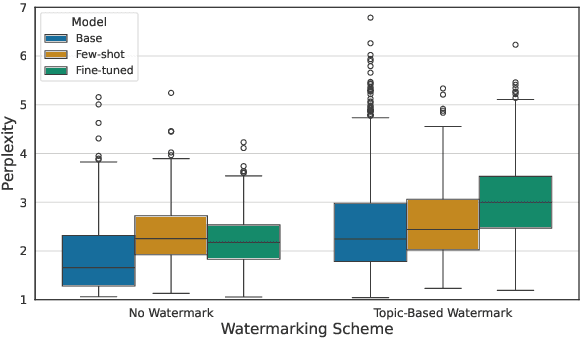
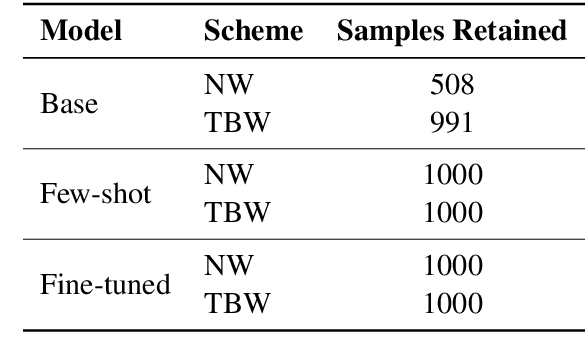
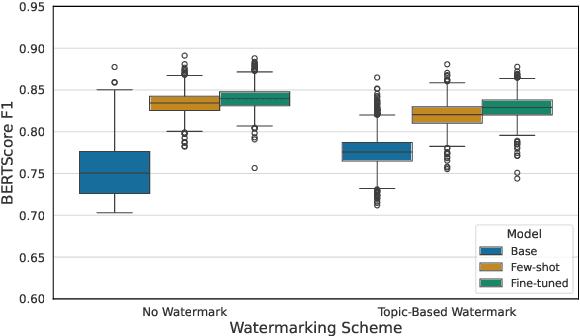
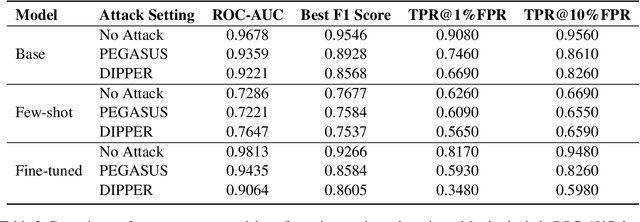
Large language models (LLMs) are increasingly integrated into academic workflows, with many conferences and journals permitting their use for tasks such as language refinement and literature summarization. However, their use in peer review remains prohibited due to concerns around confidentiality breaches, hallucinated content, and inconsistent evaluations. As LLM-generated text becomes more indistinguishable from human writing, there is a growing need for reliable attribution mechanisms to preserve the integrity of the review process. In this work, we evaluate topic-based watermarking (TBW), a lightweight, semantic-aware technique designed to embed detectable signals into LLM-generated text. We conduct a comprehensive assessment across multiple LLM configurations, including base, few-shot, and fine-tuned variants, using authentic peer review data from academic conferences. Our results show that TBW maintains review quality relative to non-watermarked outputs, while demonstrating strong robustness to paraphrasing-based evasion. These findings highlight the viability of TBW as a minimally intrusive and practical solution for enforcing LLM usage in peer review.
Privacy-Preserving Model and Preprocessing Verification for Machine Learning
Jan 14, 2025
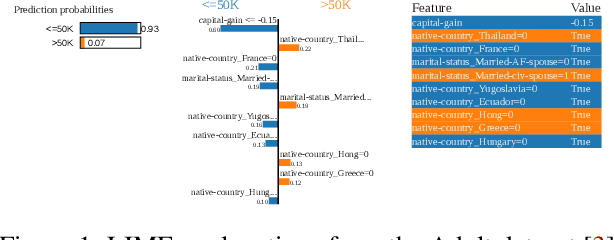
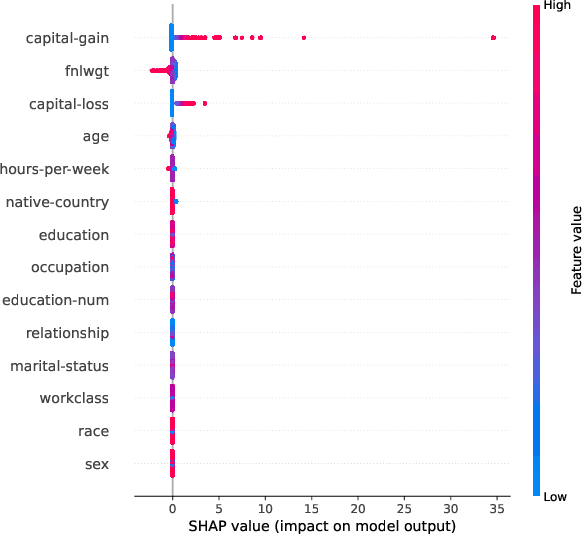
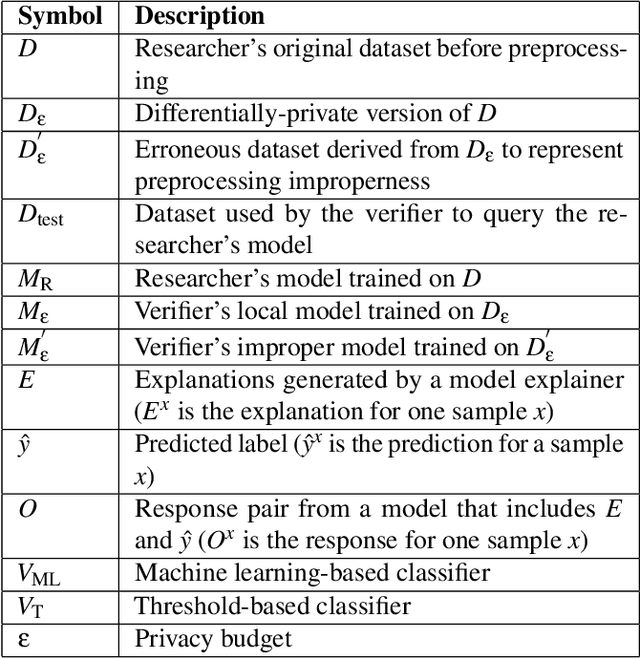
This paper presents a framework for privacy-preserving verification of machine learning models, focusing on models trained on sensitive data. Integrating Local Differential Privacy (LDP) with model explanations from LIME and SHAP, our framework enables robust verification without compromising individual privacy. It addresses two key tasks: binary classification, to verify if a target model was trained correctly by applying the appropriate preprocessing steps, and multi-class classification, to identify specific preprocessing errors. Evaluations on three real-world datasets-Diabetes, Adult, and Student Record-demonstrate that while the ML-based approach is particularly effective in binary tasks, the threshold-based method performs comparably in multi-class tasks. Results indicate that although verification accuracy varies across datasets and noise levels, the framework provides effective detection of preprocessing errors, strong privacy guarantees, and practical applicability for safeguarding sensitive data.