Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTOLYCUS: Exploiting Explainable AI (XAI) for Model Extraction Attacks against Decision Tree Models
Feb 04, 2023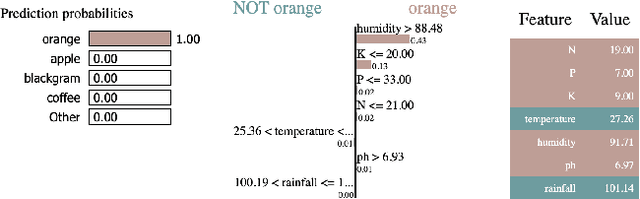
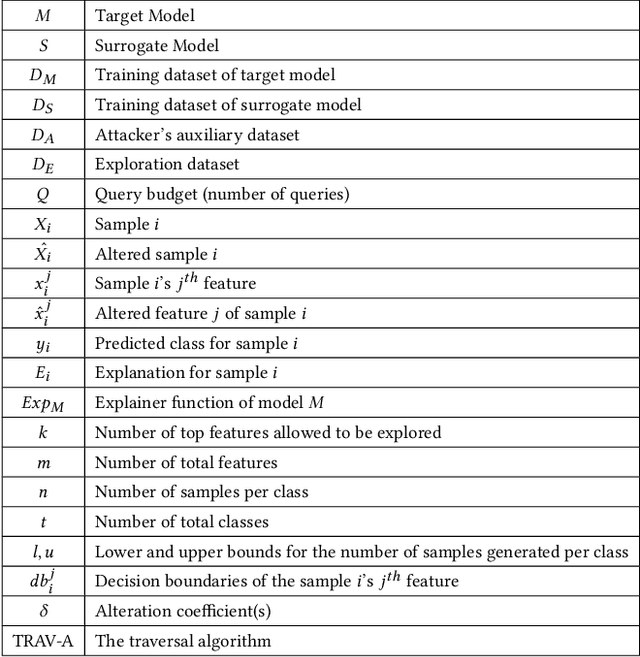

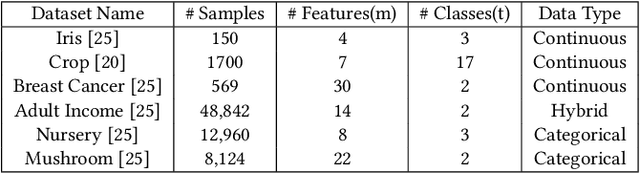
Model extraction attack is one of the most prominent adversarial techniques to target machine learning models along with membership inference attack and model inversion attack. On the other hand, Explainable Artificial Intelligence (XAI) is a set of techniques and procedures to explain the decision making process behind AI. XAI is a great tool to understand the reasoning behind AI models but the data provided for such revelation creates security and privacy vulnerabilities. In this poster, we propose AUTOLYCUS, a model extraction attack that exploits the explanations provided by LIME to infer the decision boundaries of decision tree models and create extracted surrogate models that behave similar to a target model.
* Submitted to "The Network and Distributed System Security Symposium
(NDSS) 2023" as a poster submission
Via