 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-based Watermarks for LLM-Generated Text
Paper and Code
Apr 02, 2024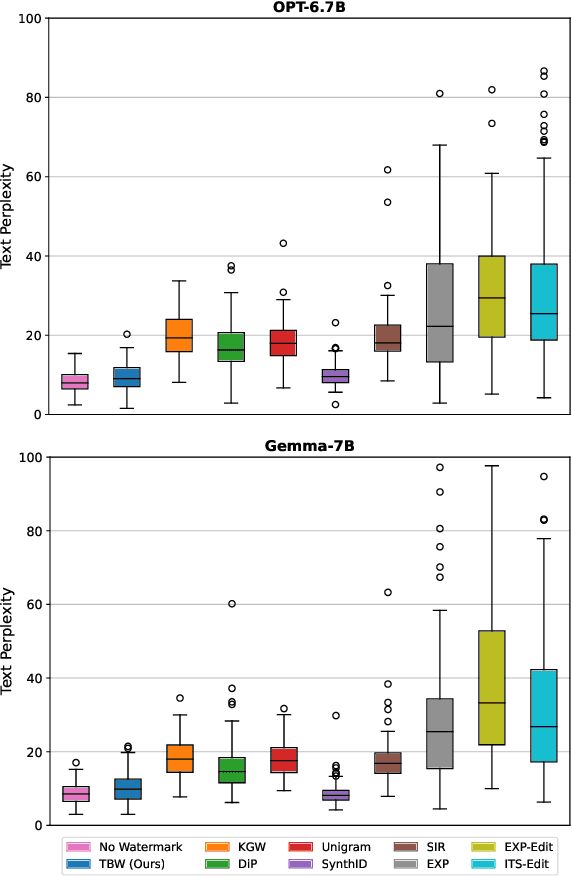

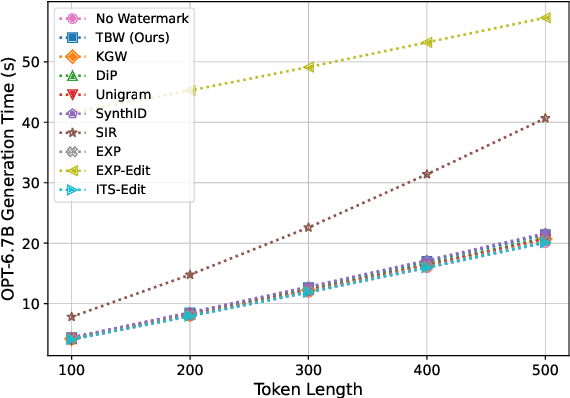
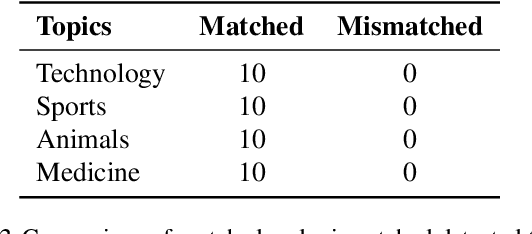
Recent advancements of large language models (LLMs) have resulted in indistinguishable text outputs comparable to human-generated text. Watermarking algorithms are potential tools that offer a way to differentiate between LLM- and human-generated text by embedding detectable signatures within LLM-generated output. However, current watermarking schemes lack robustness against known attacks against watermarking algorithms. In addition, they are impractical considering an LLM generates tens of thousands of text outputs per day and the watermarking algorithm needs to memorize each output it generates for the detection to work. In this work, focusing on the limitations of current watermarking schemes, we propose the concept of a "topic-based watermarking algorithm" for LLMs. The proposed algorithm determines how to generate tokens for the watermarked LLM output based on extracted topics of an input prompt or the output of a non-watermarked LLM. Inspired from previous work, we propose using a pair of lists (that are generated based on the specified extracted topic(s)) that specify certain tokens to be included or excluded while generating the watermarked output of the LLM. Using the proposed watermarking algorithm, we show the practicality of a watermark detection algorithm. Furthermore, we discuss a wide range of attacks that can emerge against watermarking algorithms for LLMs and the benefit of the proposed watermarking scheme for the feasibility of modeling a potential attacker considering its benefit vs. loss.