 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPS-MEBR: Click Feedback-Aware Web Page Summarization for Multi-Embedding-Based Retrieval
Oct 19, 2022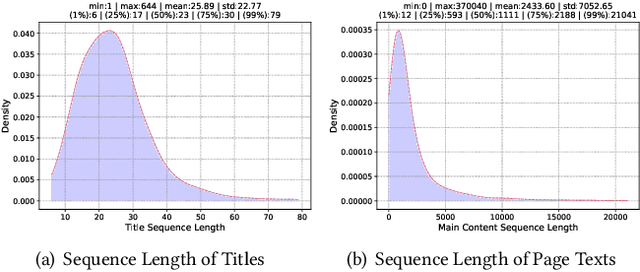
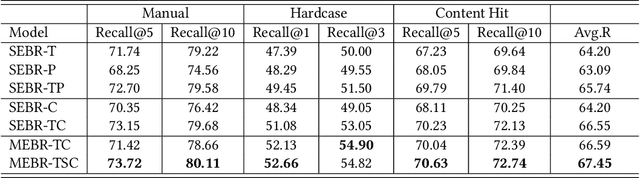

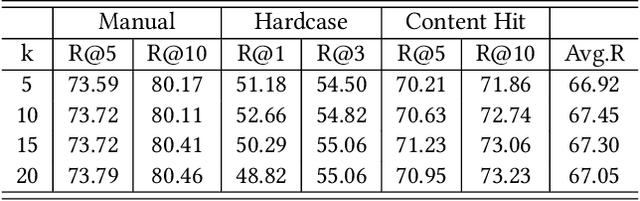
Embedding-based retrieval (EBR) is a technique to use embeddings to represent query and document, and then convert the retrieval problem into a nearest neighbor search problem in the embedding space. Some previous works have mainly focused on representing the web page with a single embedding, but in real web search scenarios, it is difficult to represent all the information of a long and complex structured web page as a single embedding. To address this issue, we design a click feedback-aware web page summarization for multi-embedding-based retrieval (CPS-MEBR) framework which is able to generate multiple embeddings for web pages to match different potential queries. Specifically, we use the click data of users in search logs to train a summary model to extract those sentences in web pages that are frequently clicked by users, which are more likely to answer those potential queries. Meanwhile, we introduce sentence-level semantic interaction to design a multi-embedding-based retrieval (MEBR) model, which can generate multiple embeddings to deal with different potential queries by using frequently clicked sentences in web pages. Offline experiments show that it can perform high quality candidate retrieval compared to single-embedding-based retrieval (SEBR) model.
Pre-trained Language Model for Web-scale Retrieval in Baidu Search
Jun 30, 2021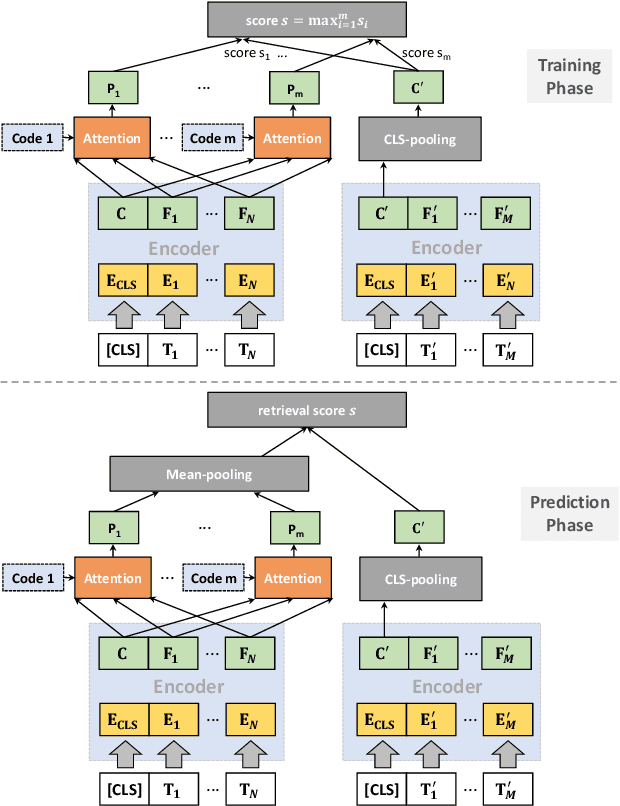
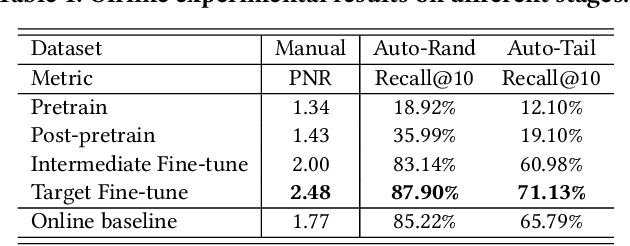
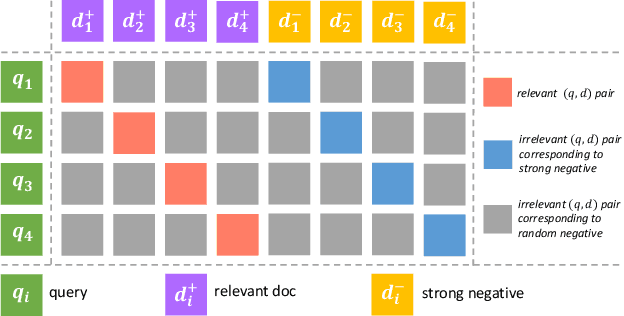

Retrieval is a crucial stage in web search that identifies a small set of query-relevant candidates from a billion-scale corpus. Discovering more semantically-related candidates in the retrieval stage is very promising to expose more high-quality results to the end users. However, it still remains non-trivial challenges of building and deploying effective retrieval models for semantic matching in real search engine. In this paper, we describe the retrieval system that we developed and deployed in Baidu Search. The system exploits the recent state-of-the-art Chinese pretrained language model, namely Enhanced Representation through kNowledge IntEgration (ERNIE), which facilitates the system with expressive semantic matching. In particular, we developed an ERNIE-based retrieval model, which is equipped with 1) expressive Transformer-based semantic encoders, and 2) a comprehensive multi-stage training paradigm. More importantly, we present a practical system workflow for deploying the model in web-scale retrieval. Eventually, the system is fully deployed into production, where rigorous offline and online experiments were conducted. The results show that the system can perform high-quality candidate retrieval, especially for those tail queries with uncommon demands. Overall, the new retrieval system facilitated by pretrained language model (i.e., ERNIE) can largely improve the usability and applicability of our search engine.