 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Patterns for Securing LLM Agents against Prompt Injections
Jun 11, 2025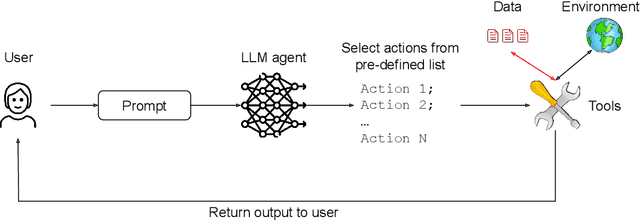
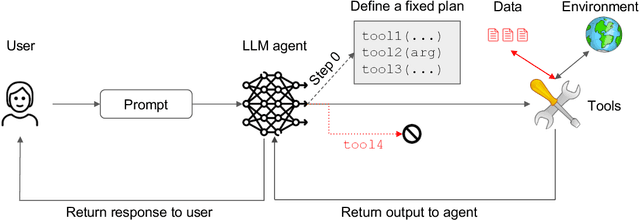
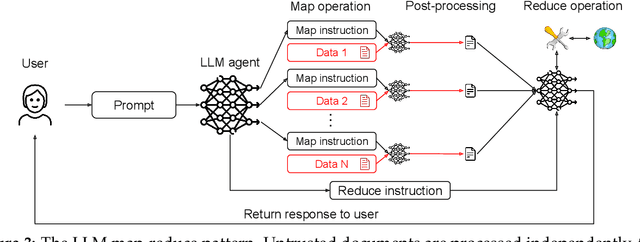
As AI agents powered by Large Language Models (LLMs) become increasingly versatile and capable of addressing a broad spectrum of tasks, ensuring their security has become a critical challenge. Among the most pressing threats are prompt injection attacks, which exploit the agent's resilience on natural language inputs -- an especially dangerous threat when agents are granted tool access or handle sensitive information. In this work, we propose a set of principled design patterns for building AI agents with provable resistance to prompt injection. We systematically analyze these patterns, discuss their trade-offs in terms of utility and security, and illustrate their real-world applicability through a series of case studies.
What's documented in AI? Systematic Analysis of 32K AI Model Cards
Feb 07, 2024The rapid proliferation of AI models has underscored the importance of thorough documentation, as it enables users to understand, trust, and effectively utilize these models in various applications. Although developers are encouraged to produce model cards, it's not clear how much information or what information these cards contain. In this study, we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most of the AI models with substantial downloads provide model cards, though the cards have uneven informativeness. We find that sections addressing environmental impact, limitations, and evaluation exhibit the lowest filled-out rates, while the training section is the most consistently filled-out. We analyze the content of each section to characterize practitioners' priorities. Interestingly, there are substantial discussions of data, sometimes with equal or even greater emphasis than the model itself. To evaluate the impact of model cards, we conducted an intervention study by adding detailed model cards to 42 popular models which had no or sparse model cards previously. We find that adding model cards is moderately correlated with an increase weekly download rates. Our study opens up a new perspective for analyzing community norms and practices for model documentation through large-scale data science and linguistics analysis.
Measuring Data
Dec 09, 2022


We identify the task of measuring data to quantitatively characterize the composition of machine learning data and datasets. Similar to an object's height, width, and volume, data measurements quantify different attributes of data along common dimensions that support comparison. Several lines of research have proposed what we refer to as measurements, with differing terminology; we bring some of this work together, particularly in fields of computer vision and language, and build from it to motivate measuring data as a critical component of responsible AI development. Measuring data aids in systematically building and analyzing machine learning (ML) data towards specific goals and gaining better control of what modern ML systems will learn. We conclude with a discussion of the many avenues of future work, the limitations of data measurements, and how to leverage these measurement approaches in research and practice.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.