 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Patterns for Securing LLM Agents against Prompt Injections
Jun 11, 2025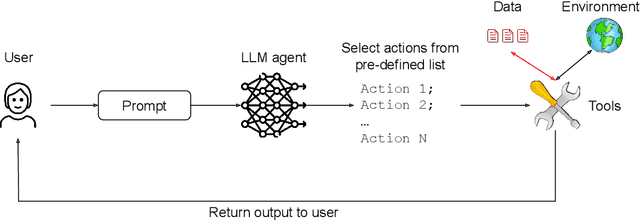
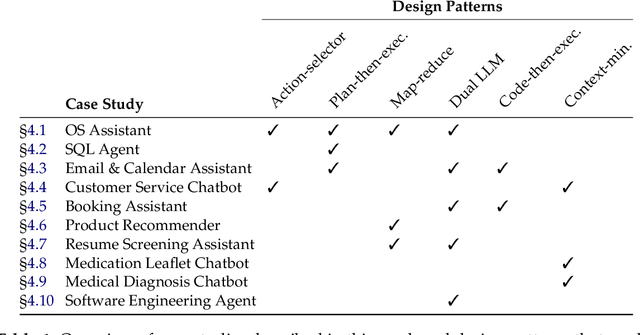
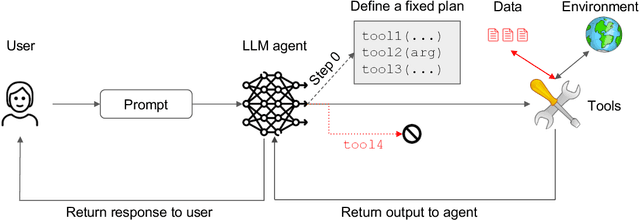
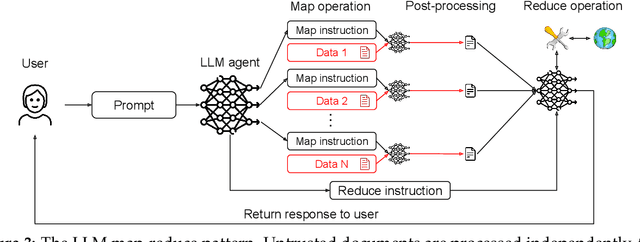
As AI agents powered by Large Language Models (LLMs) become increasingly versatile and capable of addressing a broad spectrum of tasks, ensuring their security has become a critical challenge. Among the most pressing threats are prompt injection attacks, which exploit the agent's resilience on natural language inputs -- an especially dangerous threat when agents are granted tool access or handle sensitive information. In this work, we propose a set of principled design patterns for building AI agents with provable resistance to prompt injection. We systematically analyze these patterns, discuss their trade-offs in terms of utility and security, and illustrate their real-world applicability through a series of case studies.
LLMs unlock new paths to monetizing exploits
May 16, 2025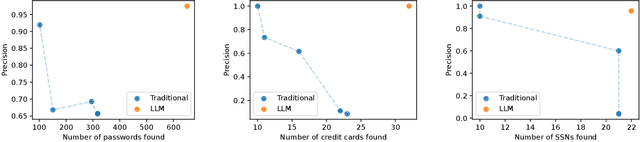
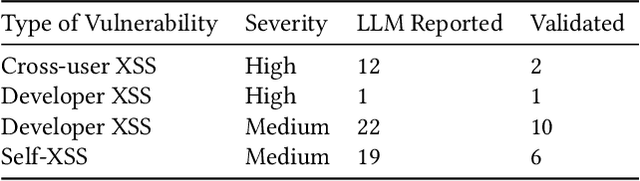

We argue that Large language models (LLMs) will soon alter the economics of cyberattacks. Instead of attacking the most commonly used software and monetizing exploits by targeting the lowest common denominator among victims, LLMs enable adversaries to launch tailored attacks on a user-by-user basis. On the exploitation front, instead of human attackers manually searching for one difficult-to-identify bug in a product with millions of users, LLMs can find thousands of easy-to-identify bugs in products with thousands of users. And on the monetization front, instead of generic ransomware that always performs the same attack (encrypt all your data and request payment to decrypt), an LLM-driven ransomware attack could tailor the ransom demand based on the particular content of each exploited device. We show that these two attacks (and several others) are imminently practical using state-of-the-art LLMs. For example, we show that without any human intervention, an LLM finds highly sensitive personal information in the Enron email dataset (e.g., an executive having an affair with another employee) that could be used for blackmail. While some of our attacks are still too expensive to scale widely today, the incentives to implement these attacks will only increase as LLMs get cheaper. Thus, we argue that LLMs create a need for new defense-in-depth approaches.
Defeating Prompt Injections by Design
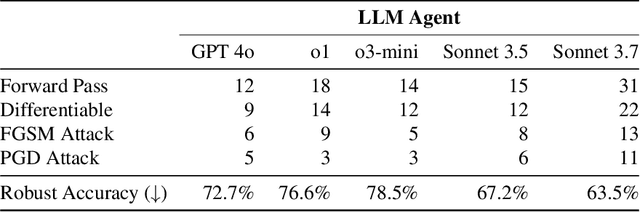
Mar 24, 2025Large Language Models (LLMs) are increasingly deployed in agentic systems that interact with an external environment. However, LLM agents are vulnerable to prompt injection attacks when handling untrusted data. In this paper we propose CaMeL, a robust defense that creates a protective system layer around the LLM, securing it even when underlying models may be susceptible to attacks. To operate, CaMeL explicitly extracts the control and data flows from the (trusted) query; therefore, the untrusted data retrieved by the LLM can never impact the program flow. To further improve security, CaMeL relies on a notion of a capability to prevent the exfiltration of private data over unauthorized data flows. We demonstrate effectiveness of CaMeL by solving $67\%$ of tasks with provable security in AgentDojo [NeurIPS 2024], a recent agentic security benchmark.
AutoAdvExBench: Benchmarking autonomous exploitation of adversarial example defenses
Mar 03, 2025
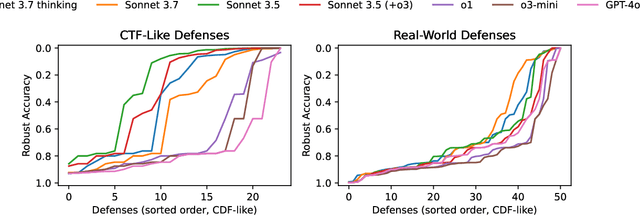

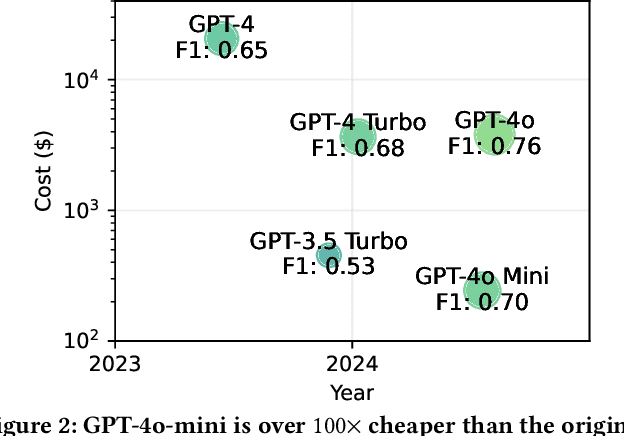
We introduce AutoAdvExBench, a benchmark to evaluate if large language models (LLMs) can autonomously exploit defenses to adversarial examples. Unlike existing security benchmarks that often serve as proxies for real-world tasks, bench directly measures LLMs' success on tasks regularly performed by machine learning security experts. This approach offers a significant advantage: if a LLM could solve the challenges presented in bench, it would immediately present practical utility for adversarial machine learning researchers. We then design a strong agent that is capable of breaking 75% of CTF-like ("homework exercise") adversarial example defenses. However, we show that this agent is only able to succeed on 13% of the real-world defenses in our benchmark, indicating the large gap between difficulty in attacking "real" code, and CTF-like code. In contrast, a stronger LLM that can attack 21% of real defenses only succeeds on 54% of CTF-like defenses. We make this benchmark available at https://github.com/ethz-spylab/AutoAdvExBench.
Exploring Memorization and Copyright Violation in Frontier LLMs: A Study of the New York Times v. OpenAI 2023 Lawsuit
Dec 09, 2024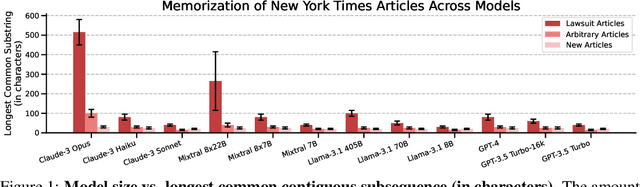
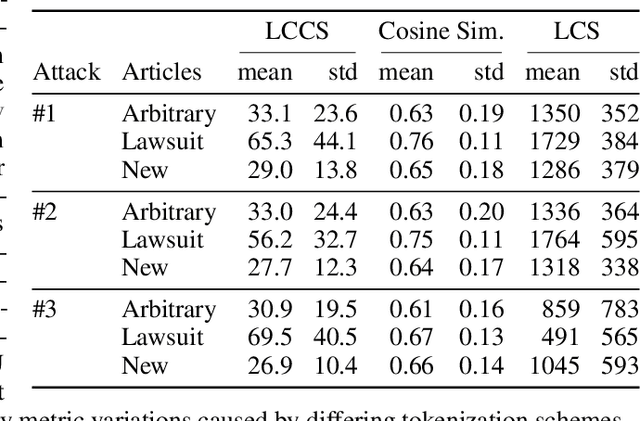

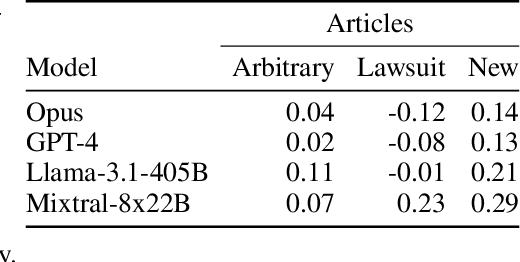
Copyright infringement in frontier LLMs has received much attention recently due to the New York Times v. OpenAI lawsuit, filed in December 2023. The New York Times claims that GPT-4 has infringed its copyrights by reproducing articles for use in LLM training and by memorizing the inputs, thereby publicly displaying them in LLM outputs. Our work aims to measure the propensity of OpenAI's LLMs to exhibit verbatim memorization in its outputs relative to other LLMs, specifically focusing on news articles. We discover that both GPT and Claude models use refusal training and output filters to prevent verbatim output of the memorized articles. We apply a basic prompt template to bypass the refusal training and show that OpenAI models are currently less prone to memorization elicitation than models from Meta, Mistral, and Anthropic. We find that as models increase in size, especially beyond 100 billion parameters, they demonstrate significantly greater capacity for memorization. Our findings have practical implications for training: more attention must be placed on preventing verbatim memorization in very large models. Our findings also have legal significance: in assessing the relative memorization capacity of OpenAI's LLMs, we probe the strength of The New York Times's copyright infringement claims and OpenAI's legal defenses, while underscoring issues at the intersection of generative AI, law, and policy.
Measuring Non-Adversarial Reproduction of Training Data in Large Language Models
Nov 15, 2024Large language models memorize parts of their training data. Memorizing short snippets and facts is required to answer questions about the world and to be fluent in any language. But models have also been shown to reproduce long verbatim sequences of memorized text when prompted by a motivated adversary. In this work, we investigate an intermediate regime of memorization that we call non-adversarial reproduction, where we quantify the overlap between model responses and pretraining data when responding to natural and benign prompts. For a variety of innocuous prompt categories (e.g., writing a letter or a tutorial), we show that up to 15% of the text output by popular conversational language models overlaps with snippets from the Internet. In worst cases, we find generations where 100% of the content can be found exactly online. For the same tasks, we find that human-written text has far less overlap with Internet data. We further study whether prompting strategies can close this reproduction gap between models and humans. While appropriate prompting can reduce non-adversarial reproduction on average, we find that mitigating worst-case reproduction of training data requires stronger defenses -- even for benign interactions.
Adversarial Search Engine Optimization for Large Language Models
Jun 26, 2024



Large Language Models (LLMs) are increasingly used in applications where the model selects from competing third-party content, such as in LLM-powered search engines or chatbot plugins. In this paper, we introduce Preference Manipulation Attacks, a new class of attacks that manipulate an LLM's selections to favor the attacker. We demonstrate that carefully crafted website content or plugin documentations can trick an LLM to promote the attacker products and discredit competitors, thereby increasing user traffic and monetization. We show this leads to a prisoner's dilemma, where all parties are incentivized to launch attacks, but the collective effect degrades the LLM's outputs for everyone. We demonstrate our attacks on production LLM search engines (Bing and Perplexity) and plugin APIs (for GPT-4 and Claude). As LLMs are increasingly used to rank third-party content, we expect Preference Manipulation Attacks to emerge as a significant threat.
AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents
Jun 19, 2024



AI agents aim to solve complex tasks by combining text-based reasoning with external tool calls. Unfortunately, AI agents are vulnerable to prompt injection attacks where data returned by external tools hijacks the agent to execute malicious tasks. To measure the adversarial robustness of AI agents, we introduce AgentDojo, an evaluation framework for agents that execute tools over untrusted data. To capture the evolving nature of attacks and defenses, AgentDojo is not a static test suite, but rather an extensible environment for designing and evaluating new agent tasks, defenses, and adaptive attacks. We populate the environment with 97 realistic tasks (e.g., managing an email client, navigating an e-banking website, or making travel bookings), 629 security test cases, and various attack and defense paradigms from the literature. We find that AgentDojo poses a challenge for both attacks and defenses: state-of-the-art LLMs fail at many tasks (even in the absence of attacks), and existing prompt injection attacks break some security properties but not all. We hope that AgentDojo can foster research on new design principles for AI agents that solve common tasks in a reliable and robust manner. We release the code for AgentDojo at https://github.com/ethz-spylab/agentdojo.
Dataset and Lessons Learned from the 2024 SaTML LLM Capture-the-Flag Competition
Jun 12, 2024



Large language model systems face important security risks from maliciously crafted messages that aim to overwrite the system's original instructions or leak private data. To study this problem, we organized a capture-the-flag competition at IEEE SaTML 2024, where the flag is a secret string in the LLM system prompt. The competition was organized in two phases. In the first phase, teams developed defenses to prevent the model from leaking the secret. During the second phase, teams were challenged to extract the secrets hidden for defenses proposed by the other teams. This report summarizes the main insights from the competition. Notably, we found that all defenses were bypassed at least once, highlighting the difficulty of designing a successful defense and the necessity for additional research to protect LLM systems. To foster future research in this direction, we compiled a dataset with over 137k multi-turn attack chats and open-sourced the platform.
AI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.