 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Ground Truth to Measurement: A Statistical Framework for Human Labeling
Apr 08, 2026Supervised machine learning assumes that labeled data provide accurate measurements of the concepts models are meant to learn. Yet in practice, human labeling introduces systematic variation arising from ambiguous items, divergent interpretations, and simple mistakes. Machine learning research commonly treats all disagreement as noise, which obscures these distinctions and limits our understanding of what models actually learn. This paper reframes annotation as a measurement process and introduces a statistical framework for decomposing labeling outcomes into interpretable sources of variation: instance difficulty, annotator bias, situational noise, and relational alignment. The framework extends classical measurement-error models to accommodate both shared and individualized notions of truth, reflecting traditional and human label variation interpretations of error, and provides a diagnostic for assessing which regime better characterizes a given task. Applying the proposed model to a multi-annotator natural language inference dataset, we find empirical evidence for all four theorized components and demonstrate the effectiveness of our approach. We conclude with implications for data-centric machine learning and outline how this approach can guide the development of a more systematic science of labeling.
Dialect and Gender Bias in YouTube's Spanish Captioning System
Feb 27, 2026Spanish is the official language of twenty-one countries and is spoken by over 441 million people. Naturally, there are many variations in how Spanish is spoken across these countries. Media platforms such as YouTube rely on automatic speech recognition systems to make their content accessible to different groups of users. However, YouTube offers only one option for automatically generating captions in Spanish. This raises the question: could this captioning system be biased against certain Spanish dialects? This study examines the potential biases in YouTube's automatic captioning system by analyzing its performance across various Spanish dialects. By comparing the quality of captions for female and male speakers from different regions, we identify systematic disparities which can be attributed to specific dialects. Our study provides further evidence that algorithmic technologies deployed on digital platforms need to be calibrated to the diverse needs and experiences of their user populations.
Empirically Understanding the Value of Prediction in Allocation
Feb 09, 2026Institutions increasingly use prediction to allocate scarce resources. From a design perspective, better predictions compete with other investments, such as expanding capacity or improving treatment quality. Here, the big question is not how to solve a specific allocation problem, but rather which problem to solve. In this work, we develop an empirical toolkit to help planners form principled answers to this question and quantify the bottom-line welfare impact of investments in prediction versus other policy levers such as expanding capacity and improving treatment quality. Applying our framework in two real-world case studies on German employment services and poverty targeting in Ethiopia, we illustrate how decision-makers can reliably derive context-specific conclusions about the relative value of prediction in their allocation problem. We make our software toolkit, rvp, and parts of our data available in order to enable future empirical work in this area.
Bias Begins with Data: The FairGround Corpus for Robust and Reproducible Research on Algorithmic Fairness
Oct 25, 2025As machine learning (ML) systems are increasingly adopted in high-stakes decision-making domains, ensuring fairness in their outputs has become a central challenge. At the core of fair ML research are the datasets used to investigate bias and develop mitigation strategies. Yet, much of the existing work relies on a narrow selection of datasets--often arbitrarily chosen, inconsistently processed, and lacking in diversity--undermining the generalizability and reproducibility of results. To address these limitations, we present FairGround: a unified framework, data corpus, and Python package aimed at advancing reproducible research and critical data studies in fair ML classification. FairGround currently comprises 44 tabular datasets, each annotated with rich fairness-relevant metadata. Our accompanying Python package standardizes dataset loading, preprocessing, transformation, and splitting, streamlining experimental workflows. By providing a diverse and well-documented dataset corpus along with robust tooling, FairGround enables the development of fairer, more reliable, and more reproducible ML models. All resources are publicly available to support open and collaborative research.
Bias in the Loop: How Humans Evaluate AI-Generated Suggestions
Sep 10, 2025Human-AI collaboration increasingly drives decision-making across industries, from medical diagnosis to content moderation. While AI systems promise efficiency gains by providing automated suggestions for human review, these workflows can trigger cognitive biases that degrade performance. We know little about the psychological factors that determine when these collaborations succeed or fail. We conducted a randomized experiment with 2,784 participants to examine how task design and individual characteristics shape human responses to AI-generated suggestions. Using a controlled annotation task, we manipulated three factors: AI suggestion quality in the first three instances, task burden through required corrections, and performance-based financial incentives. We collected demographics, attitudes toward AI, and behavioral data to assess four performance metrics: accuracy, correction activity, overcorrection, and undercorrection. Two patterns emerged that challenge conventional assumptions about human-AI collaboration. First, requiring corrections for flagged AI errors reduced engagement and increased the tendency to accept incorrect suggestions, demonstrating how cognitive shortcuts influence collaborative outcomes. Second, individual attitudes toward AI emerged as the strongest predictor of performance, surpassing demographic factors. Participants skeptical of AI detected errors more reliably and achieved higher accuracy, while those favorable toward automation exhibited dangerous overreliance on algorithmic suggestions. The findings reveal that successful human-AI collaboration depends not only on algorithmic performance but also on who reviews AI outputs and how review processes are structured. Effective human-AI collaborations require consideration of human psychology: selecting diverse evaluator samples, measuring attitudes, and designing workflows that counteract cognitive biases.
Defeating Prompt Injections by Design
Mar 24, 2025Large Language Models (LLMs) are increasingly deployed in agentic systems that interact with an external environment. However, LLM agents are vulnerable to prompt injection attacks when handling untrusted data. In this paper we propose CaMeL, a robust defense that creates a protective system layer around the LLM, securing it even when underlying models may be susceptible to attacks. To operate, CaMeL explicitly extracts the control and data flows from the (trusted) query; therefore, the untrusted data retrieved by the LLM can never impact the program flow. To further improve security, CaMeL relies on a notion of a capability to prevent the exfiltration of private data over unauthorized data flows. We demonstrate effectiveness of CaMeL by solving $67\%$ of tasks with provable security in AgentDojo [NeurIPS 2024], a recent agentic security benchmark.
The Value of Prediction in Identifying the Worst-Off
Jan 31, 2025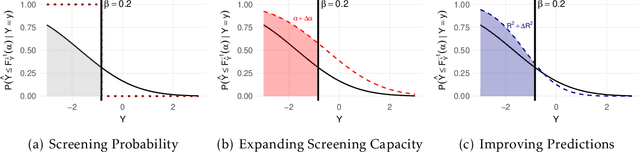
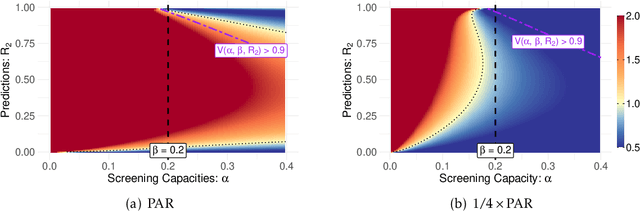
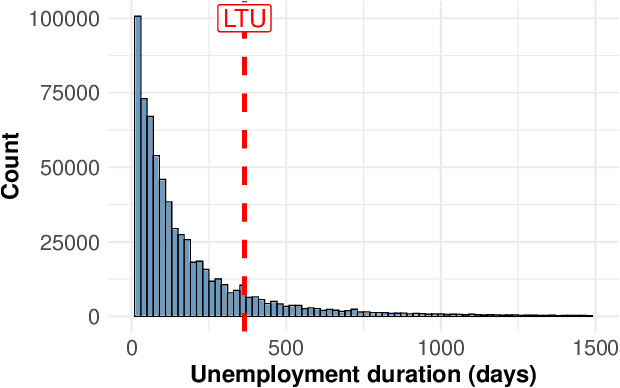
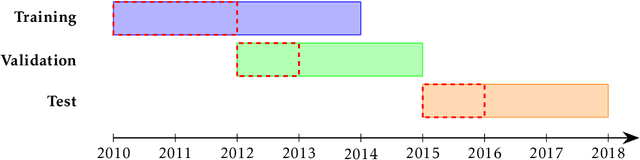
Machine learning is increasingly used in government programs to identify and support the most vulnerable individuals, prioritizing assistance for those at greatest risk over optimizing aggregate outcomes. This paper examines the welfare impacts of prediction in equity-driven contexts, and how they compare to other policy levers, such as expanding bureaucratic capacity. Through mathematical models and a real-world case study on long-term unemployment amongst German residents, we develop a comprehensive understanding of the relative effectiveness of prediction in surfacing the worst-off. Our findings provide clear analytical frameworks and practical, data-driven tools that empower policymakers to make principled decisions when designing these systems.
Correcting Annotator Bias in Training Data: Population-Aligned Instance Replication (PAIR)
Jan 12, 2025Models trained on crowdsourced labels may not reflect broader population views when annotator pools are not representative. Since collecting representative labels is challenging, we propose Population-Aligned Instance Replication (PAIR), a method to address this bias through statistical adjustment. Using a simulation study of hate speech and offensive language detection, we create two types of annotators with different labeling tendencies and generate datasets with varying proportions of the types. Models trained on unbalanced annotator pools show poor calibration compared to those trained on representative data. However, PAIR, which duplicates labels from underrepresented annotator groups to match population proportions, significantly reduces bias without requiring new data collection. These results suggest statistical techniques from survey research can help align model training with target populations even when representative annotator pools are unavailable. We conclude with three practical recommendations for improving training data quality.
The Missing Link: Allocation Performance in Causal Machine Learning
Jul 15, 2024Automated decision-making (ADM) systems are being deployed across a diverse range of critical problem areas such as social welfare and healthcare. Recent work highlights the importance of causal ML models in ADM systems, but implementing them in complex social environments poses significant challenges. Research on how these challenges impact the performance in specific downstream decision-making tasks is limited. Addressing this gap, we make use of a comprehensive real-world dataset of jobseekers to illustrate how the performance of a single CATE model can vary significantly across different decision-making scenarios and highlight the differential influence of challenges such as distribution shifts on predictions and allocations.
Multi-CATE: Multi-Accurate Conditional Average Treatment Effect Estimation Robust to Unknown Covariate Shifts
May 28, 2024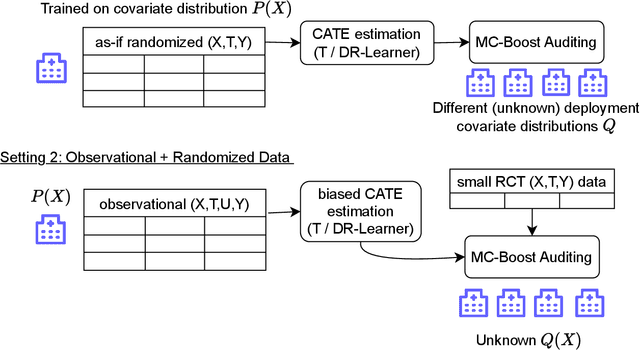

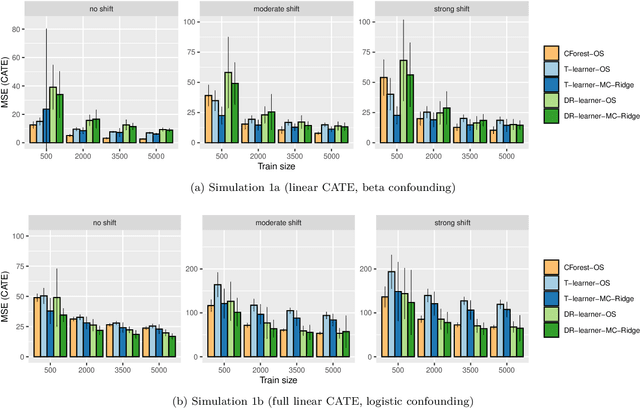
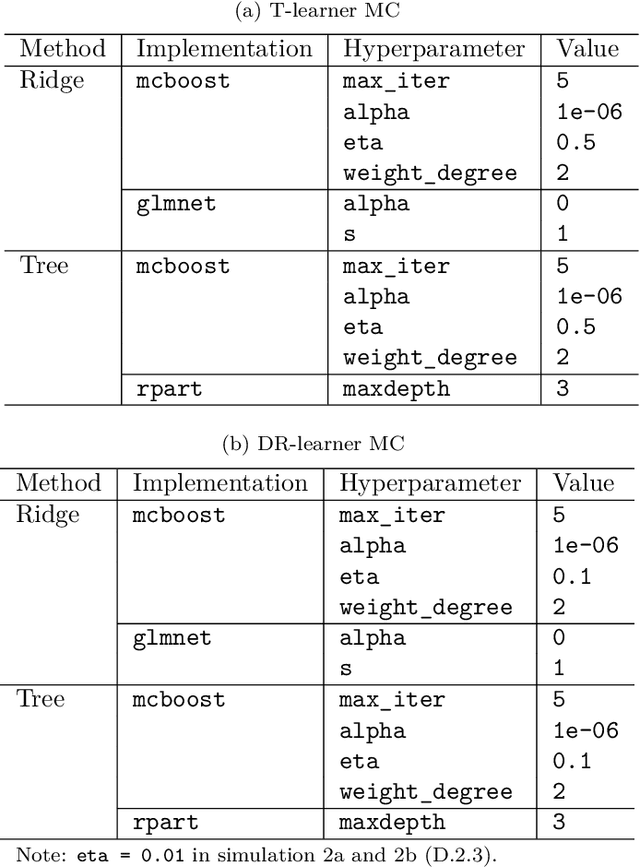
Estimating heterogeneous treatment effects is important to tailor treatments to those individuals who would most likely benefit. However, conditional average treatment effect predictors may often be trained on one population but possibly deployed on different, possibly unknown populations. We use methodology for learning multi-accurate predictors to post-process CATE T-learners (differenced regressions) to become robust to unknown covariate shifts at the time of deployment. The method works in general for pseudo-outcome regression, such as the DR-learner. We show how this approach can combine (large) confounded observational and (smaller) randomized datasets by learning a confounded predictor from the observational dataset, and auditing for multi-accuracy on the randomized controlled trial. We show improvements in bias and mean squared error in simulations with increasingly larger covariate shift, and on a semi-synthetic case study of a parallel large observational study and smaller randomized controlled experiment. Overall, we establish a connection between methods developed for multi-distribution learning and achieve appealing desiderata (e.g. external validity) in causal inference and machine learning.