 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirically Understanding the Value of Prediction in Allocation
Feb 09, 2026Institutions increasingly use prediction to allocate scarce resources. From a design perspective, better predictions compete with other investments, such as expanding capacity or improving treatment quality. Here, the big question is not how to solve a specific allocation problem, but rather which problem to solve. In this work, we develop an empirical toolkit to help planners form principled answers to this question and quantify the bottom-line welfare impact of investments in prediction versus other policy levers such as expanding capacity and improving treatment quality. Applying our framework in two real-world case studies on German employment services and poverty targeting in Ethiopia, we illustrate how decision-makers can reliably derive context-specific conclusions about the relative value of prediction in their allocation problem. We make our software toolkit, rvp, and parts of our data available in order to enable future empirical work in this area.
Performative Learning Theory
Feb 04, 2026Performative predictions influence the very outcomes they aim to forecast. We study performative predictions that affect a sample (e.g., only existing users of an app) and/or the whole population (e.g., all potential app users). This raises the question of how well models generalize under performativity. For example, how well can we draw insights about new app users based on existing users when both of them react to the app's predictions? We address this question by embedding performative predictions into statistical learning theory. We prove generalization bounds under performative effects on the sample, on the population, and on both. A key intuition behind our proofs is that in the worst case, the population negates predictions, while the sample deceptively fulfills them. We cast such self-negating and self-fulfilling predictions as min-max and min-min risk functionals in Wasserstein space, respectively. Our analysis reveals a fundamental trade-off between performatively changing the world and learning from it: the more a model affects data, the less it can learn from it. Moreover, our analysis results in a surprising insight on how to improve generalization guarantees by retraining on performatively distorted samples. We illustrate our bounds in a case study on prediction-informed assignments of unemployed German residents to job trainings, drawing upon administrative labor market records from 1975 to 2017 in Germany.
The Value of Prediction in Identifying the Worst-Off
Jan 31, 2025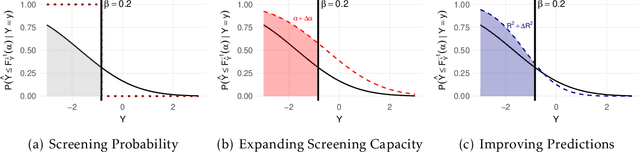
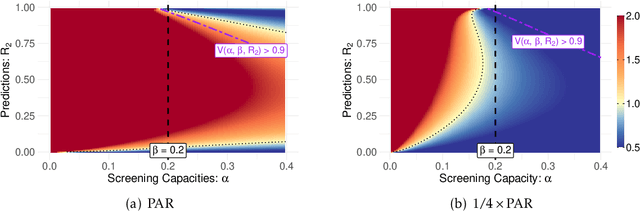
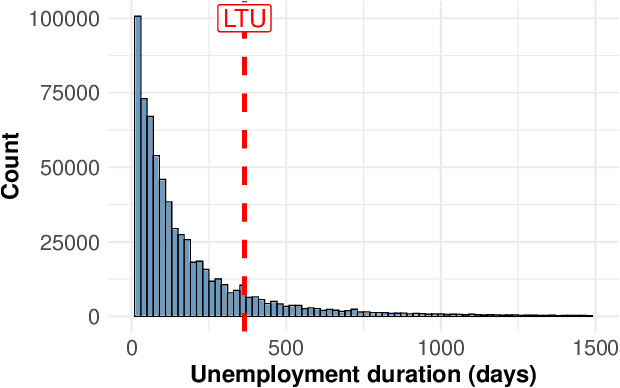
Machine learning is increasingly used in government programs to identify and support the most vulnerable individuals, prioritizing assistance for those at greatest risk over optimizing aggregate outcomes. This paper examines the welfare impacts of prediction in equity-driven contexts, and how they compare to other policy levers, such as expanding bureaucratic capacity. Through mathematical models and a real-world case study on long-term unemployment amongst German residents, we develop a comprehensive understanding of the relative effectiveness of prediction in surfacing the worst-off. Our findings provide clear analytical frameworks and practical, data-driven tools that empower policymakers to make principled decisions when designing these systems.
The Missing Link: Allocation Performance in Causal Machine Learning
Jul 15, 2024Automated decision-making (ADM) systems are being deployed across a diverse range of critical problem areas such as social welfare and healthcare. Recent work highlights the importance of causal ML models in ADM systems, but implementing them in complex social environments poses significant challenges. Research on how these challenges impact the performance in specific downstream decision-making tasks is limited. Addressing this gap, we make use of a comprehensive real-world dataset of jobseekers to illustrate how the performance of a single CATE model can vary significantly across different decision-making scenarios and highlight the differential influence of challenges such as distribution shifts on predictions and allocations.