 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence estimation of classification based on the distribution of the neural network output layer
Oct 18, 2022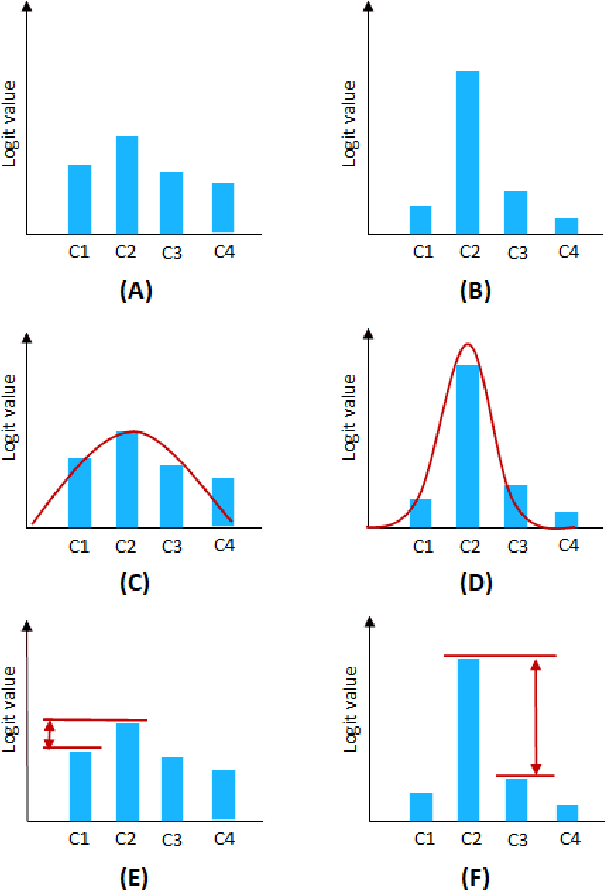
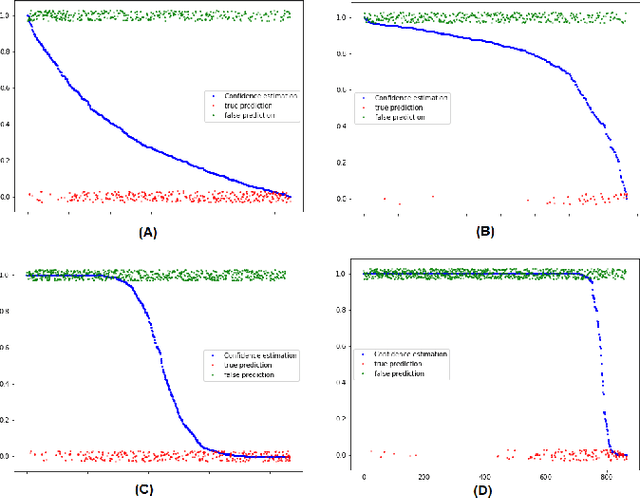
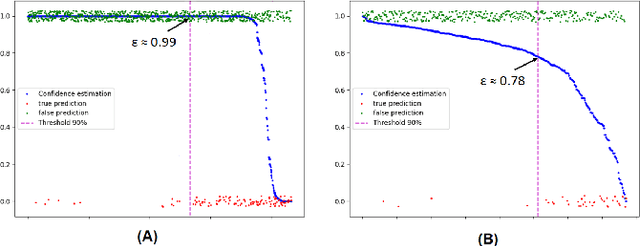
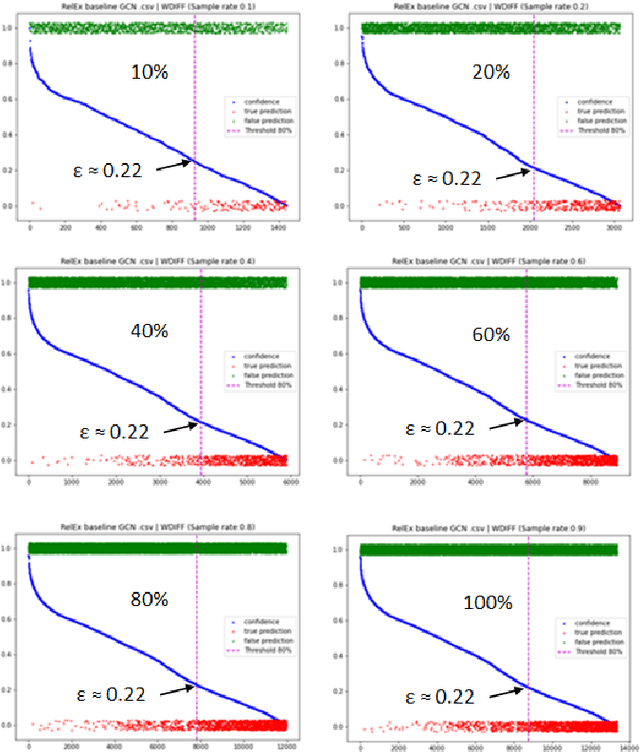
One of the most common problems preventing the application of prediction models in the real world is lack of generalization: The accuracy of models, measured in the benchmark does repeat itself on future data, e.g. in the settings of real business. There is relatively little methods exist that estimate the confidence of prediction models. In this paper, we propose novel methods that, given a neural network classification model, estimate uncertainty of particular predictions generated by this model. Furthermore, we propose a method that, given a model and a confidence level, calculates a threshold that separates prediction generated by this model into two subsets, one of them meets the given confidence level. In contrast to other methods, the proposed methods do not require any changes on existing neural networks, because they simply build on the output logit layer of a common neural network. In particular, the methods infer the confidence of a particular prediction based on the distribution of the logit values corresponding to this prediction. The proposed methods constitute a tool that is recommended for filtering predictions in the process of knowledge extraction, e.g. based on web scrapping, where predictions subsets are identified that maximize the precision on cost of the recall, which is less important due to the availability of data. The method has been tested on different tasks including relation extraction, named entity recognition and image classification to show the significant increase of accuracy achieved.
On The Usage Of Average Hausdorff Distance For Segmentation Performance Assessment: Hidden Bias When Used For Ranking
Sep 13, 2020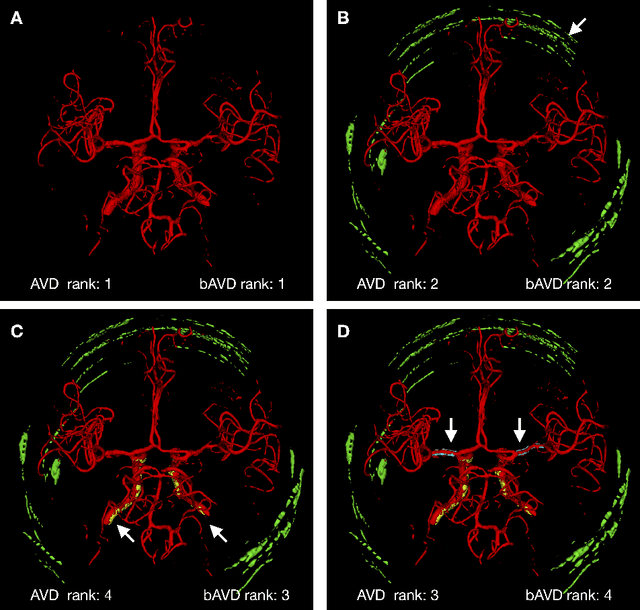
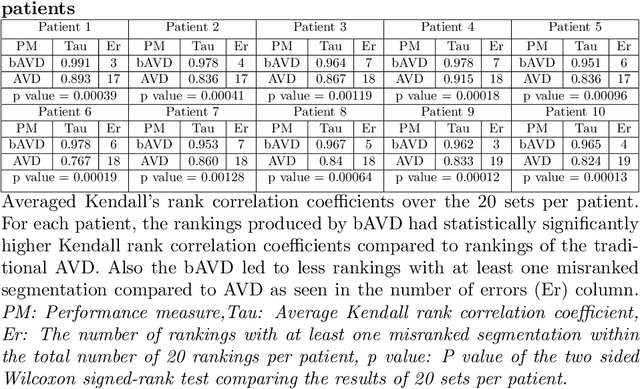
Average Hausdorff Distance (AVD) is a widely used performance measure to calculate the distance between two point sets. In medical image segmentation, AVD is used to compare ground truth images with segmentation results allowing their ranking. We identified, however, a ranking bias of AVD making it less suitable for segmentation ranking. To mitigate this bias, we present a modified calculation of AVD that we have coined balanced AVD (bAVD). To simulate segmentations for ranking, we manually created non-overlapping segmentation errors common in cerebral vessel segmentation as our use-case. Adding the created errors consecutively and randomly to the ground truth, we created sets of simulated segmentations with increasing number of errors. Each set of simulated segmentations was ranked using AVD and bAVD. We calculated the Kendall-rank-correlation-coefficient between the segmentation ranking and the number of errors in each simulated segmentation. The rankings produced by bAVD had a significantly higher average correlation (0.969) than those of AVD (0.847). In 200 total rankings, bAVD misranked 52 and AVD misranked 179 segmentations. Our proposed evaluation measure, bAVD, alleviates AVDs ranking bias making it more suitable for rankings and quality assessment of segmentations.
Is the winner really the best? A critical analysis of common research practice in biomedical image analysis competitions
Jun 06, 2018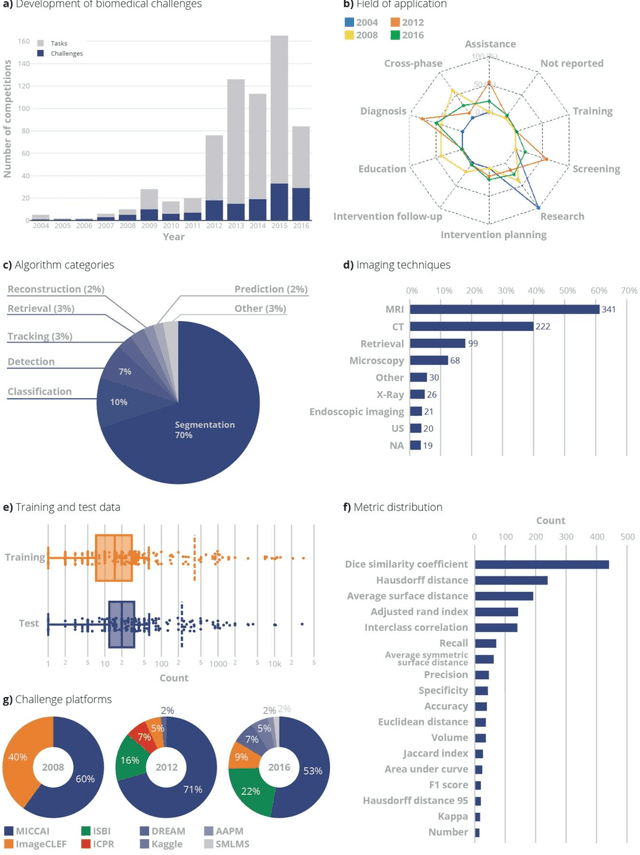
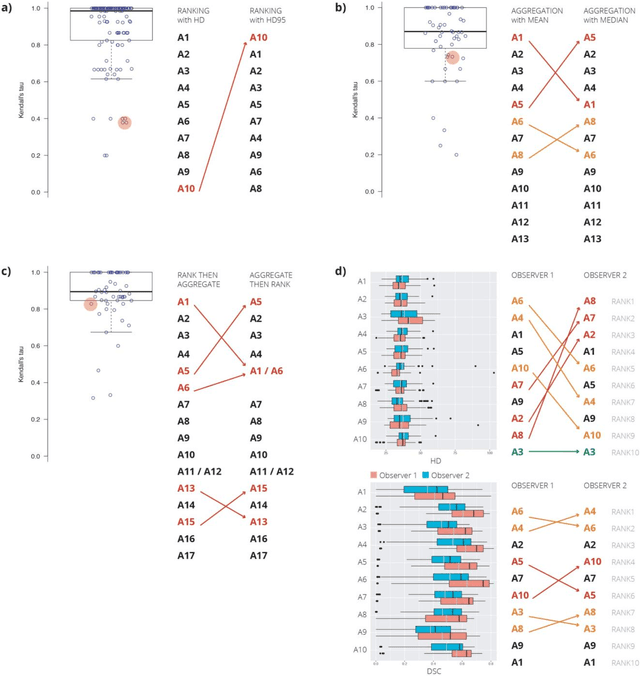
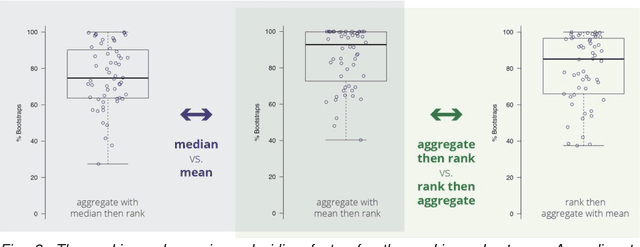
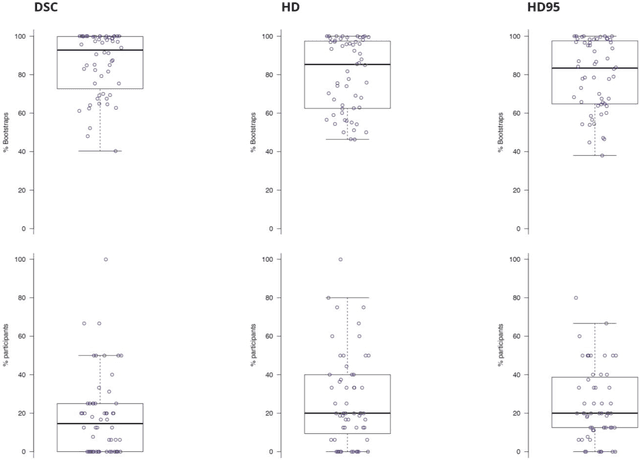
International challenges have become the standard for validation of biomedical image analysis methods. Given their scientific impact, it is surprising that a critical analysis of common practices related to the organization of challenges has not yet been performed. In this paper, we present a comprehensive analysis of biomedical image analysis challenges conducted up to now. We demonstrate the importance of challenges and show that the lack of quality control has critical consequences. First, reproducibility and interpretation of the results is often hampered as only a fraction of relevant information is typically provided. Second, the rank of an algorithm is generally not robust to a number of variables such as the test data used for validation, the ranking scheme applied and the observers that make the reference annotations. To overcome these problems, we recommend best practice guidelines and define open research questions to be addressed in the future.