 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing the Black-Box: Signed-Distance Supervision for Black-Box Model Copying
Jan 28, 2026Deployed machine learning systems must continuously evolve as data, architectures, and regulations change, often without access to original training data or model internals. In such settings, black-box copying provides a practical refactoring mechanism, i.e. upgrading legacy models by learning replicas from input-output queries alone. When restricted to hard-label outputs, copying turns into a discontinuous surface reconstruction problem from pointwise queries, severely limiting the ability to recover boundary geometry efficiently. We propose a distance-based copying (distillation) framework that replaces hard-label supervision with signed distances to the teacher's decision boundary, converting copying into a smooth regression problem that exploits local geometry. We develop an $α$-governed smoothing and regularization scheme with Hölder/Lipschitz control over the induced target surface, and introduce two model-agnostic algorithms to estimate signed distances under label-only access. Experiments on synthetic problems and UCI benchmarks show consistent improvements in fidelity and generalization accuracy over hard-label baselines, while enabling distance outputs as uncertainty-related signals for black-box replicas.
Safeguarding Autonomy: a Focus on Machine Learning Decision Systems
Mar 27, 2025As global discourse on AI regulation gains momentum, this paper focuses on delineating the impact of ML on autonomy and fostering awareness. Respect for autonomy is a basic principle in bioethics that establishes persons as decision-makers. While the concept of autonomy in the context of ML appears in several European normative publications, it remains a theoretical concept that has yet to be widely accepted in ML practice. Our contribution is to bridge the theoretical and practical gap by encouraging the practical application of autonomy in decision-making within ML practice by identifying the conditioning factors that currently prevent it. Consequently, we focus on the different stages of the ML pipeline to identify the potential effects on ML end-users' autonomy. To improve its practical utility, we propose a related question for each detected impact, offering guidance for identifying possible focus points to respect ML end-users autonomy in decision-making.
A Scalable and Efficient Iterative Method for Copying Machine Learning Classifiers
Feb 07, 2023Differential replication through copying refers to the process of replicating the decision behavior of a machine learning model using another model that possesses enhanced features and attributes. This process is relevant when external constraints limit the performance of an industrial predictive system. Under such circumstances, copying enables the retention of original prediction capabilities while adapting to new demands. Previous research has focused on the single-pass implementation for copying. This paper introduces a novel sequential approach that significantly reduces the amount of computational resources needed to train or maintain a copy, leading to reduced maintenance costs for companies using machine learning models in production. The effectiveness of the sequential approach is demonstrated through experiments with synthetic and real-world datasets, showing significant reductions in time and resources, while maintaining or improving accuracy.
Importance attribution in neural networks by means of persistence landscapes of time series
Feb 06, 2023We propose and implement a method to analyze time series with a neural network using a matrix of area-normalized persistence landscapes obtained through topological data analysis. We include a gating layer in the network's architecture that is able to identify the most relevant landscape levels for the classification task, thus working as an importance attribution system. Next, we perform a matching between the selected landscape functions and the corresponding critical points of the original time series. From this matching we are able to reconstruct an approximate shape of the time series that gives insight into the classification decision. We test this technique with input data from a dataset of electrocardiographic signals.
Reconstruction of univariate functions from directional persistence diagrams
Mar 03, 2022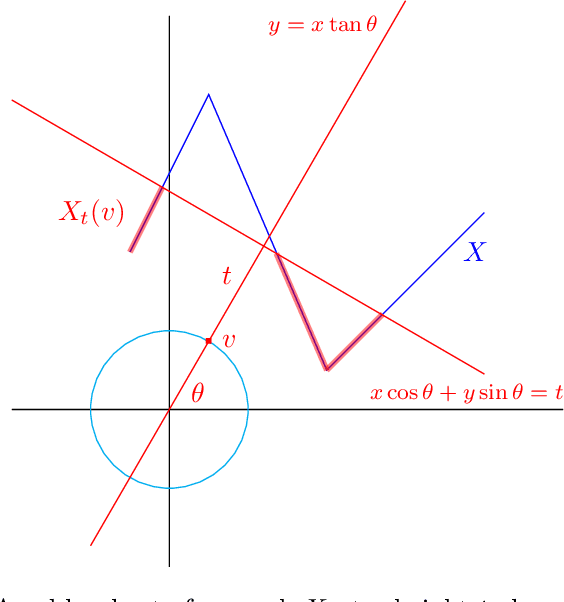



We describe a method for approximating a single-variable function $f$ using persistence diagrams of sublevel sets of $f$ from height functions in different directions. We provide algorithms for the piecewise linear case and for the smooth case. Three directions suffice to locate all local maxima and minima of a piecewise linear continuous function from its collection of directional persistence diagrams, while five directions are needed in the case of smooth functions with non-degenerate critical points. Our approximation of functions by means of persistence diagrams is motivated by a study of importance attribution in machine learning, where one seeks to reduce the number of critical points of signal functions without a significant loss of information for a neural network classifier.
Training Thinner and Deeper Neural Networks: Jumpstart Regularization
Jan 30, 2022
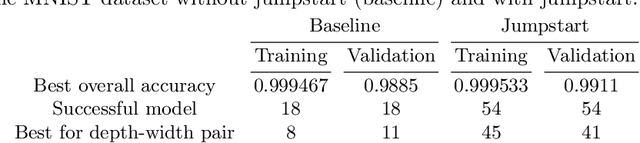
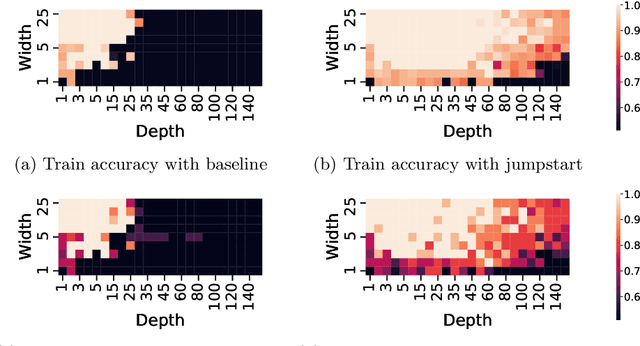
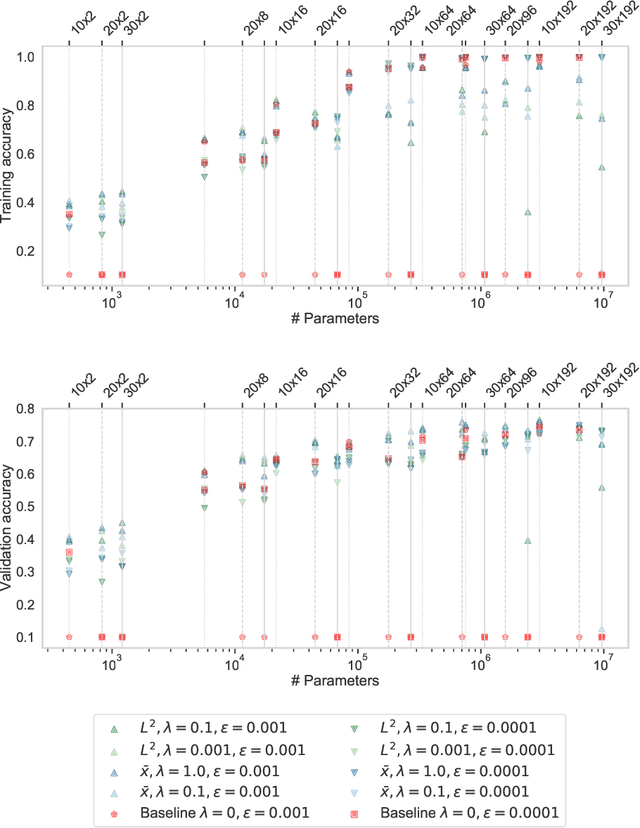
Neural networks are more expressive when they have multiple layers. In turn, conventional training methods are only successful if the depth does not lead to numerical issues such as exploding or vanishing gradients, which occur less frequently when the layers are sufficiently wide. However, increasing width to attain greater depth entails the use of heavier computational resources and leads to overparameterized models. These subsequent issues have been partially addressed by model compression methods such as quantization and pruning, some of which relying on normalization-based regularization of the loss function to make the effect of most parameters negligible. In this work, we propose instead to use regularization for preventing neurons from dying or becoming linear, a technique which we denote as jumpstart regularization. In comparison to conventional training, we obtain neural networks that are thinner, deeper, and - most importantly - more parameter-efficient.
Quantile Encoder: Tackling High Cardinality Categorical Features in Regression Problems
May 27, 2021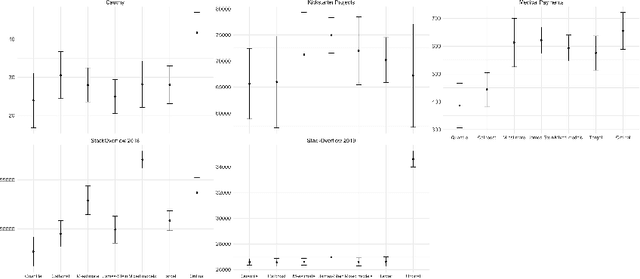
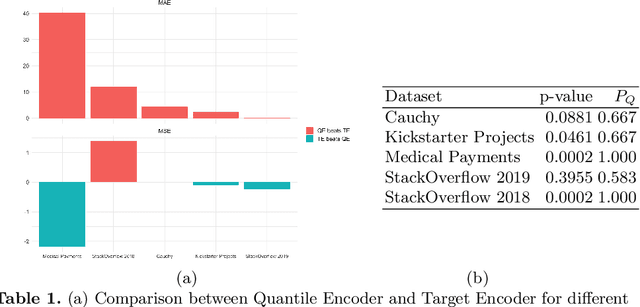
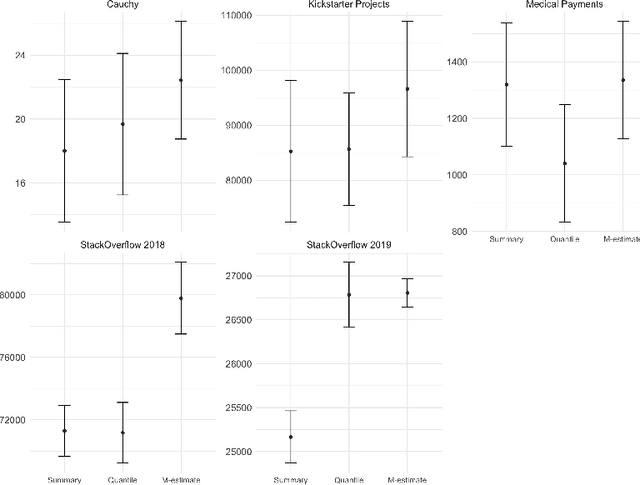
Regression problems have been widely studied in machinelearning literature resulting in a plethora of regression models and performance measures. However, there are few techniques specially dedicated to solve the problem of how to incorporate categorical features to regression problems. Usually, categorical feature encoders are general enough to cover both classification and regression problems. This lack of specificity results in underperforming regression models. In this paper,we provide an in-depth analysis of how to tackle high cardinality categor-ical features with the quantile. Our proposal outperforms state-of-the-encoders, including the traditional statistical mean target encoder, when considering the Mean Absolute Error, especially in the presence of long-tailed or skewed distributions. Besides, to deal with possible overfitting when there are categories with small support, our encoder benefits from additive smoothing. Finally, we describe how to expand the encoded values by creating a set of features with different quantiles. This expanded encoder provides a more informative output about the categorical feature in question, further boosting the performance of the regression model.
Differential Replication in Machine Learning
Jul 15, 2020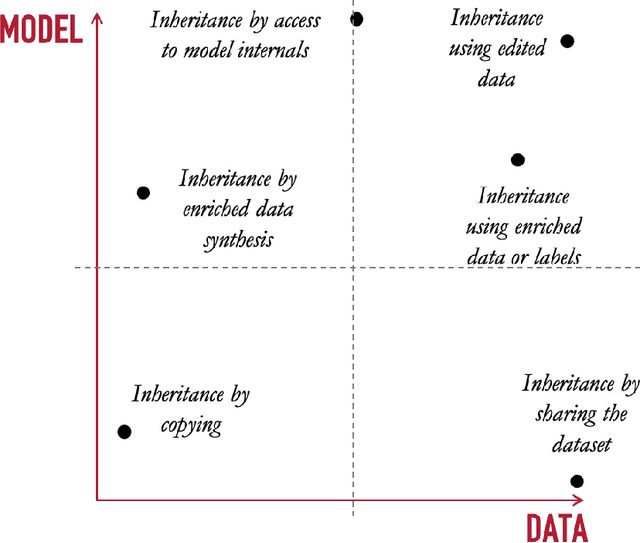
When deployed in the wild, machine learning models are usually confronted with data and requirements that constantly vary, either because of changes in the generating distribution or because external constraints change the environment where the model operates. To survive in such an ecosystem, machine learning models need to adapt to new conditions by evolving over time. The idea of model adaptability has been studied from different perspectives. In this paper, we propose a solution based on reusing the knowledge acquired by the already deployed machine learning models and leveraging it to train future generations. This is the idea behind differential replication of machine learning models.
Dirichlet uncertainty wrappers for actionable algorithm accuracy accountability and auditability
Dec 29, 2019

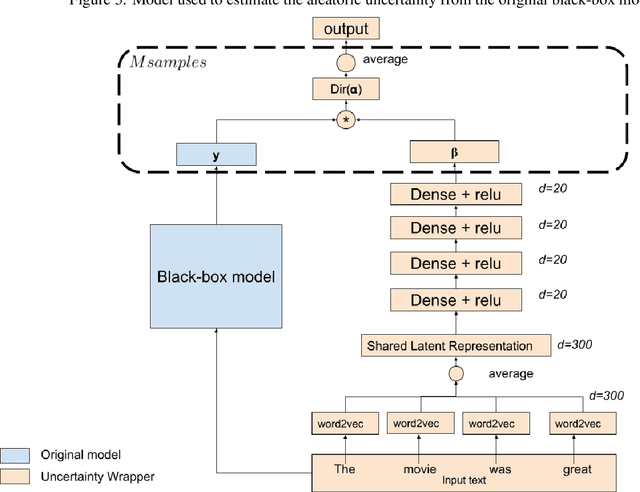
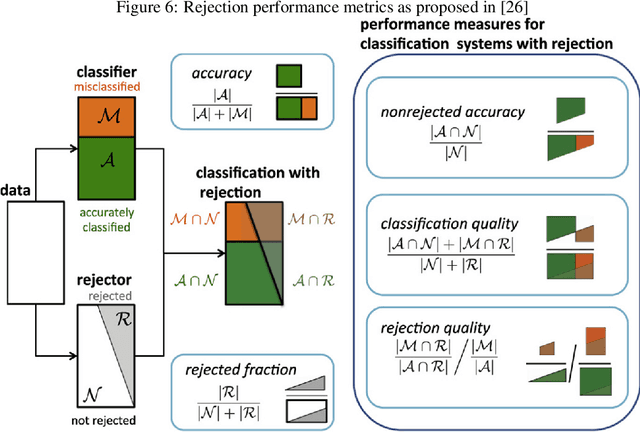
Nowadays, the use of machine learning models is becoming a utility in many applications. Companies deliver pre-trained models encapsulated as application programming interfaces (APIs) that developers combine with third party components and their own models and data to create complex data products to solve specific problems. The complexity of such products and the lack of control and knowledge of the internals of each component used cause unavoidable effects, such as lack of transparency, difficulty in auditability, and emergence of potential uncontrolled risks. They are effectively black-boxes. Accountability of such solutions is a challenge for the auditors and the machine learning community. In this work, we propose a wrapper that given a black-box model enriches its output prediction with a measure of uncertainty. By using this wrapper, we make the black-box auditable for the accuracy risk (risk derived from low quality or uncertain decisions) and at the same time we provide an actionable mechanism to mitigate that risk in the form of decision rejection; we can choose not to issue a prediction when the risk or uncertainty in that decision is significant. Based on the resulting uncertainty measure, we advocate for a rejection system that selects the more confident predictions, discarding those more uncertain, leading to an improvement in the trustability of the resulting system. We showcase the proposed technique and methodology in a practical scenario where a simulated sentiment analysis API based on natural language processing is applied to different domains. Results demonstrate the effectiveness of the uncertainty computed by the wrapper and its high correlation to bad quality predictions and misclassifications.
Sampling Unknown Decision Functions to Build Classifier Copies
Oct 01, 2019
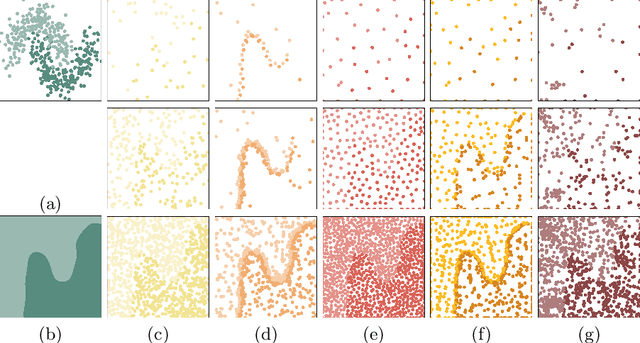


Copies have been proposed as a viable alternative to endow machine learning models with properties and features that adapt them to changing needs. A fundamental step of the copying process is generating an unlabelled set of points to explore the decision behavior of the targeted classifier throughout the input space. In this article we propose two sampling strategies to produce such sets. We validate them in six well-known problems and compare them with two standard methods. We evaluate our proposals in terms of both their accuracy performance and their computational cost.