 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable and Efficient Iterative Method for Copying Machine Learning Classifiers
Feb 07, 2023Differential replication through copying refers to the process of replicating the decision behavior of a machine learning model using another model that possesses enhanced features and attributes. This process is relevant when external constraints limit the performance of an industrial predictive system. Under such circumstances, copying enables the retention of original prediction capabilities while adapting to new demands. Previous research has focused on the single-pass implementation for copying. This paper introduces a novel sequential approach that significantly reduces the amount of computational resources needed to train or maintain a copy, leading to reduced maintenance costs for companies using machine learning models in production. The effectiveness of the sequential approach is demonstrated through experiments with synthetic and real-world datasets, showing significant reductions in time and resources, while maintaining or improving accuracy.
Differential Replication in Machine Learning
Jul 15, 2020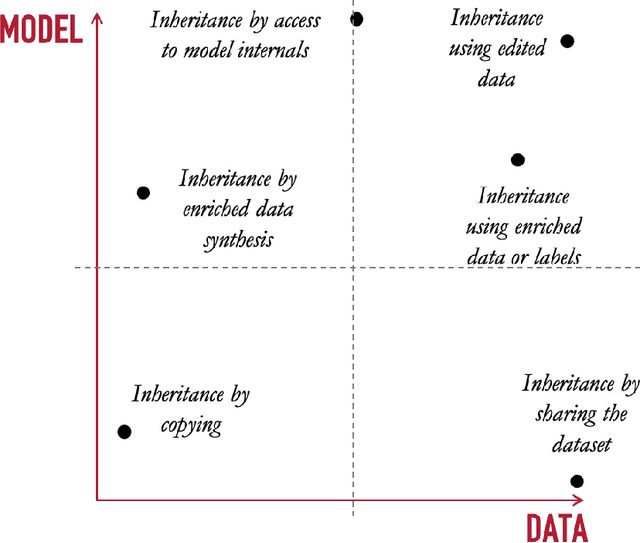
When deployed in the wild, machine learning models are usually confronted with data and requirements that constantly vary, either because of changes in the generating distribution or because external constraints change the environment where the model operates. To survive in such an ecosystem, machine learning models need to adapt to new conditions by evolving over time. The idea of model adaptability has been studied from different perspectives. In this paper, we propose a solution based on reusing the knowledge acquired by the already deployed machine learning models and leveraging it to train future generations. This is the idea behind differential replication of machine learning models.
Sampling Unknown Decision Functions to Build Classifier Copies
Oct 01, 2019
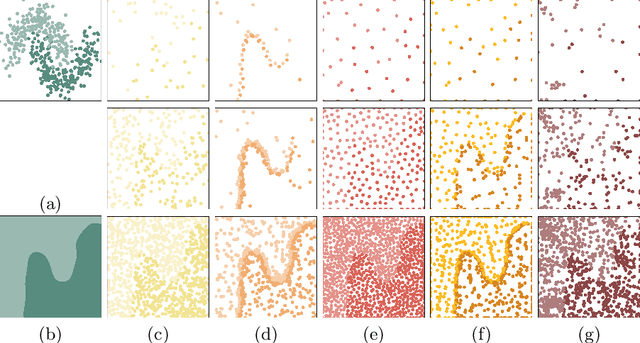


Copies have been proposed as a viable alternative to endow machine learning models with properties and features that adapt them to changing needs. A fundamental step of the copying process is generating an unlabelled set of points to explore the decision behavior of the targeted classifier throughout the input space. In this article we propose two sampling strategies to produce such sets. We validate them in six well-known problems and compare them with two standard methods. We evaluate our proposals in terms of both their accuracy performance and their computational cost.
Copying Machine Learning Classifiers
Mar 05, 2019
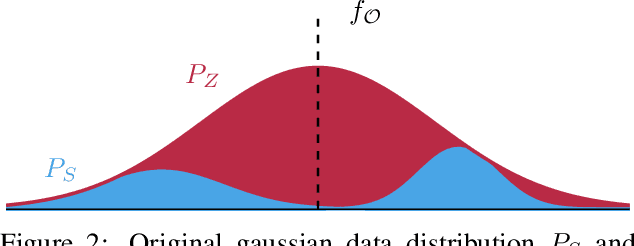


We study model-agnostic copies of machine learning classifiers. We develop the theory behind the problem of copying, highlighting its differences with that of learning, and propose a framework to copy the functionality of any classifier using no prior knowledge of its parameters or training data distribution. We identify the different sources of loss and provide guidelines on how best to generate synthetic sets for the copying process. We further introduce a set of metrics to evaluate copies in practice. We validate our framework through extensive experiments using data from a series of well-known problems. We demonstrate the value of copies in use cases where desiderata such as interpretability, fairness or productivization constrains need to be addressed. Results show that copies can be exploited to enhance existing solutions and improve them adding new features and characteristics.
Towards Global Explanations for Credit Risk Scoring
Nov 23, 2018
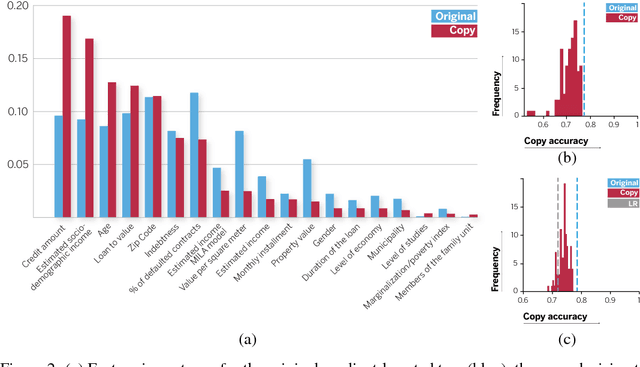
In this paper we propose a method to obtain global explanations for trained black-box classifiers by sampling their decision function to learn alternative interpretable models. The envisaged approach provides a unified solution to approximate non-linear decision boundaries with simpler classifiers while retaining the original classification accuracy. We use a private residential mortgage default dataset as a use case to illustrate the feasibility of this approach to ensure the decomposability of attributes during pre-processing.