 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustrial-Grade Smart Troubleshooting through Causal Technical Language Processing: a Proof of Concept
Jul 30, 2024This paper describes the development of a causal diagnosis approach for troubleshooting an industrial environment on the basis of the technical language expressed in Return on Experience records. The proposed method leverages the vectorized linguistic knowledge contained in the distributed representation of a Large Language Model, and the causal associations entailed by the embedded failure modes and mechanisms of the industrial assets. The paper presents the elementary but essential concepts of the solution, which is conceived as a causality-aware retrieval augmented generation system, and illustrates them experimentally on a real-world Predictive Maintenance setting. Finally, it discusses avenues of improvement for the maturity of the utilized causal technology to meet the robustness challenges of increasingly complex scenarios in the industry.
Neural Networks with Causal Graph Constraints: A New Approach for Treatment Effects Estimation
Apr 18, 2024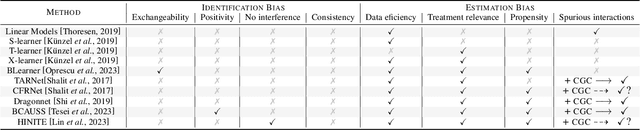
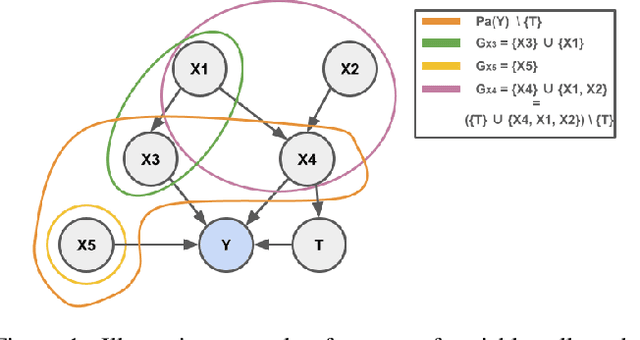
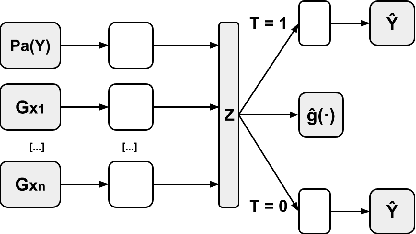
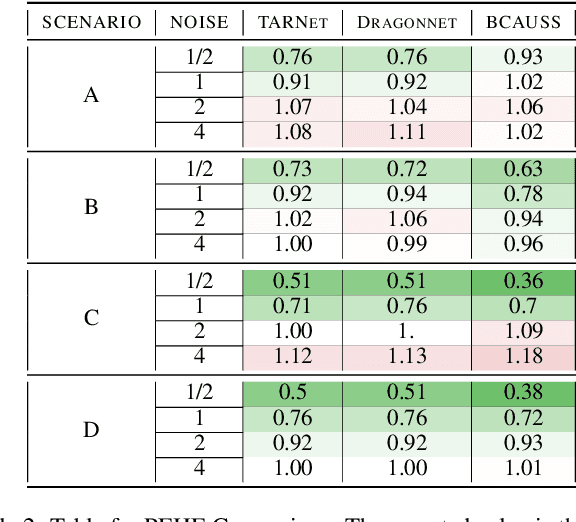
In recent years, there has been a growing interest in using machine learning techniques for the estimation of treatment effects. Most of the best-performing methods rely on representation learning strategies that encourage shared behavior among potential outcomes to increase the precision of treatment effect estimates. In this paper we discuss and classify these models in terms of their algorithmic inductive biases and present a new model, NN-CGC, that considers additional information from the causal graph. NN-CGC tackles bias resulting from spurious variable interactions by implementing novel constraints on models, and it can be integrated with other representation learning methods. We test the effectiveness of our method using three different base models on common benchmarks. Our results indicate that our model constraints lead to significant improvements, achieving new state-of-the-art results in treatment effects estimation. We also show that our method is robust to imperfect causal graphs and that using partial causal information is preferable to ignoring it.
Self-Supervised Pre-Training Boosts Semantic Scene Segmentation on LiDAR data
Sep 05, 2023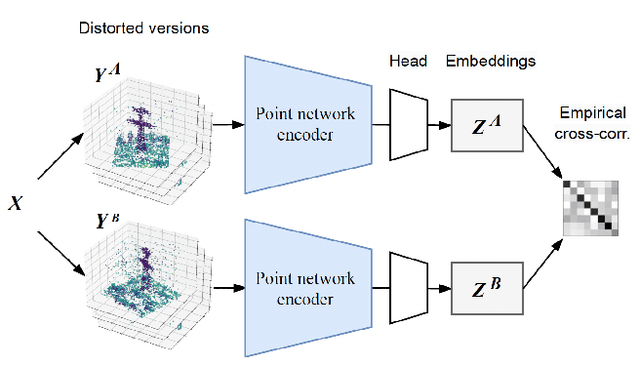


Airborne LiDAR systems have the capability to capture the Earth's surface by generating extensive point cloud data comprised of points mainly defined by 3D coordinates. However, labeling such points for supervised learning tasks is time-consuming. As a result, there is a need to investigate techniques that can learn from unlabeled data to significantly reduce the number of annotated samples. In this work, we propose to train a self-supervised encoder with Barlow Twins and use it as a pre-trained network in the task of semantic scene segmentation. The experimental results demonstrate that our unsupervised pre-training boosts performance once fine-tuned on the supervised task, especially for under-represented categories.
Time-based Self-supervised Learning for Wireless Capsule Endoscopy
Apr 20, 2022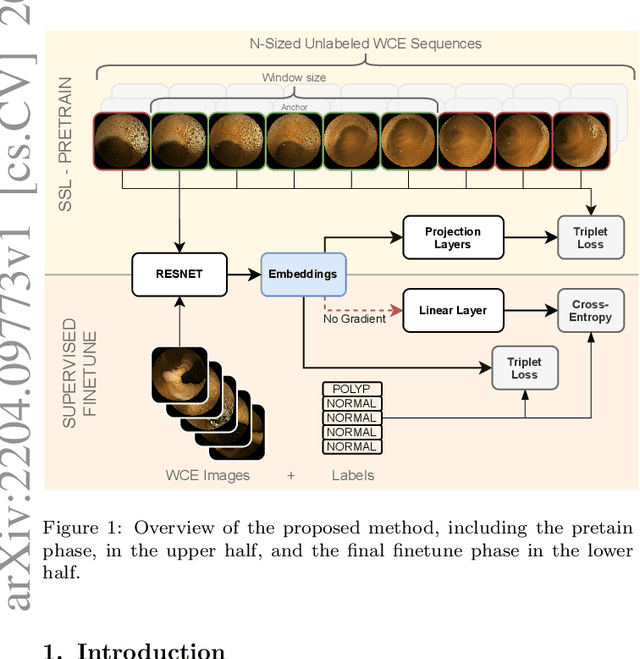
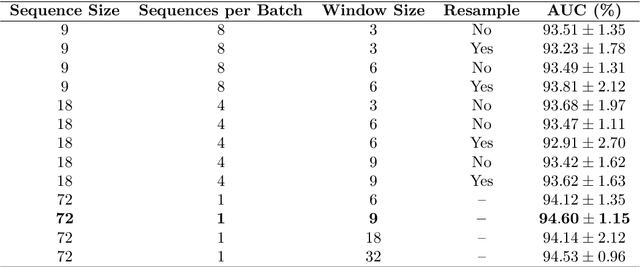
State-of-the-art machine learning models, and especially deep learning ones, are significantly data-hungry; they require vast amounts of manually labeled samples to function correctly. However, in most medical imaging fields, obtaining said data can be challenging. Not only the volume of data is a problem, but also the imbalances within its classes; it is common to have many more images of healthy patients than of those with pathology. Computer-aided diagnostic systems suffer from these issues, usually over-designing their models to perform accurately. This work proposes using self-supervised learning for wireless endoscopy videos by introducing a custom-tailored method that does not initially need labels or appropriate balance. We prove that using the inferred inherent structure learned by our method, extracted from the temporal axis, improves the detection rate on several domain-specific applications even under severe imbalance.
Deep Non-Crossing Quantiles through the Partial Derivative
Jan 30, 2022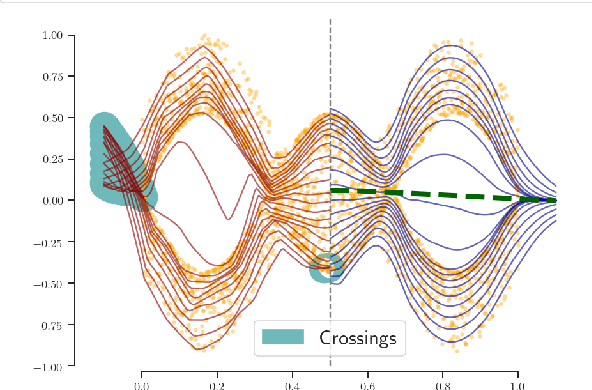

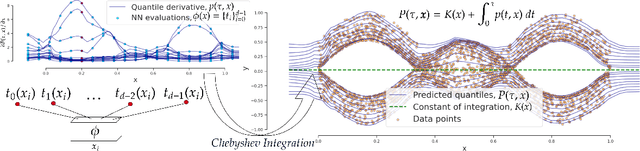

Quantile Regression (QR) provides a way to approximate a single conditional quantile. To have a more informative description of the conditional distribution, QR can be merged with deep learning techniques to simultaneously estimate multiple quantiles. However, the minimisation of the QR-loss function does not guarantee non-crossing quantiles, which affects the validity of such predictions and introduces a critical issue in certain scenarios. In this article, we propose a generic deep learning algorithm for predicting an arbitrary number of quantiles that ensures the quantile monotonicity constraint up to the machine precision and maintains its modelling performance with respect to alternative models. The presented method is evaluated over several real-world datasets obtaining state-of-the-art results as well as showing that it scales to large-size data sets.
Algorithmic Causal Effect Identification with causaleffect
Jul 09, 2021



Our evolution as a species made a huge step forward when we understood the relationships between causes and effects. These associations may be trivial for some events, but they are not in complex scenarios. To rigorously prove that some occurrences are caused by others, causal theory and causal inference were formalized, introducing the $do$-operator and its associated rules. The main goal of this report is to review and implement in Python some algorithms to compute conditional and non-conditional causal queries from observational data. To this end, we first present some basic background knowledge on probability and graph theory, before introducing important results on causal theory, used in the construction of the algorithms. We then thoroughly study the identification algorithms presented by Shpitser and Pearl in 2006, explaining our implementation in Python alongside. The main identification algorithm can be seen as a repeated application of the rules of $do$-calculus, and it eventually either returns an expression for the causal query from experimental probabilities or fails to identify the causal effect, in which case the effect is non-identifiable. We introduce our newly developed Python library and give some usage examples.
Graph Convolutional Embeddings for Recommender Systems
Mar 05, 2021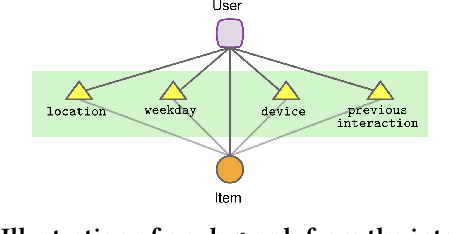
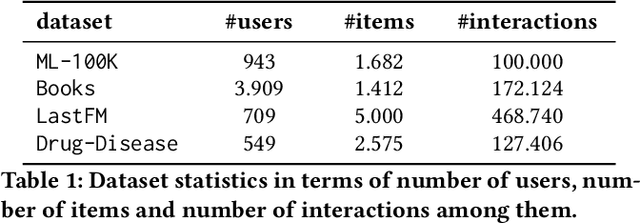
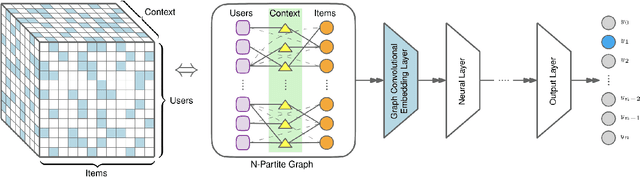
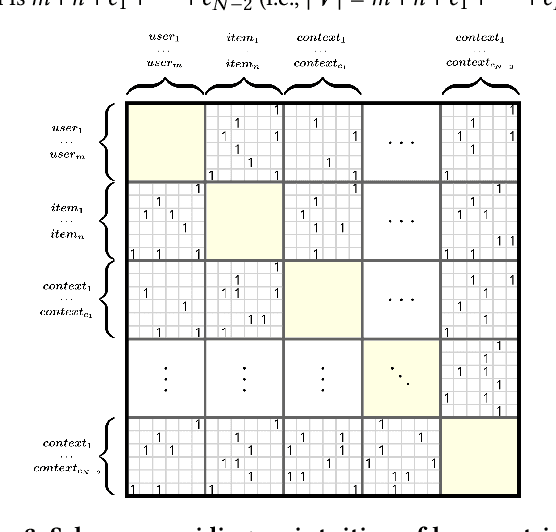
Modern recommender systems (RS) work by processing a number of signals that can be inferred from large sets of user-item interaction data. The main signal to analyze stems from the raw matrix that represents interactions. However, we can increase the performance of RS by considering other kinds of signals like the context of interactions, which could be, for example, the time or date of the interaction, the user location, or sequential data corresponding to the historical interactions of the user with the system. These complex, context-based interaction signals are characterized by a rich relational structure that can be represented by a multi-partite graph. Graph Convolutional Networks (GCNs) have been used successfully in collaborative filtering with simple user-item interaction data. In this work, we generalize the use of GCNs for N-partite graphs by considering N multiple context dimensions and propose a simple way for their seamless integration in modern deep learning RS architectures. More specifically, we define a graph convolutional embedding layer for N-partite graphs that processes user-item-context interactions, and constructs node embeddings by leveraging their relational structure. Experiments on several datasets from recommender systems to drug re-purposing show the benefits of the introduced GCN embedding layer by measuring the performance of different context-enriched tasks.
Causal Inference with Deep Causal Graphs
Jun 15, 2020


Parametric causal modelling techniques rarely provide functionality for counterfactual estimation, often at the expense of modelling complexity. Since causal estimations depend on the family of functions used to model the data, simplistic models could entail imprecise characterizations of the generative mechanism, and, consequently, unreliable results. This limits their applicability to real-life datasets, with non-linear relationships and high interaction between variables. We propose Deep Causal Graphs, an abstract specification of the required functionality for a neural network to model causal distributions, and provide a model that satisfies this contract: Normalizing Causal Flows. We demonstrate its expressive power in modelling complex interactions and showcase applications of the method to machine learning explainability and fairness, using true causal counterfactuals.
Dirichlet uncertainty wrappers for actionable algorithm accuracy accountability and auditability
Dec 29, 2019

Nowadays, the use of machine learning models is becoming a utility in many applications. Companies deliver pre-trained models encapsulated as application programming interfaces (APIs) that developers combine with third party components and their own models and data to create complex data products to solve specific problems. The complexity of such products and the lack of control and knowledge of the internals of each component used cause unavoidable effects, such as lack of transparency, difficulty in auditability, and emergence of potential uncontrolled risks. They are effectively black-boxes. Accountability of such solutions is a challenge for the auditors and the machine learning community. In this work, we propose a wrapper that given a black-box model enriches its output prediction with a measure of uncertainty. By using this wrapper, we make the black-box auditable for the accuracy risk (risk derived from low quality or uncertain decisions) and at the same time we provide an actionable mechanism to mitigate that risk in the form of decision rejection; we can choose not to issue a prediction when the risk or uncertainty in that decision is significant. Based on the resulting uncertainty measure, we advocate for a rejection system that selects the more confident predictions, discarding those more uncertain, leading to an improvement in the trustability of the resulting system. We showcase the proposed technique and methodology in a practical scenario where a simulated sentiment analysis API based on natural language processing is applied to different domains. Results demonstrate the effectiveness of the uncertainty computed by the wrapper and its high correlation to bad quality predictions and misclassifications.
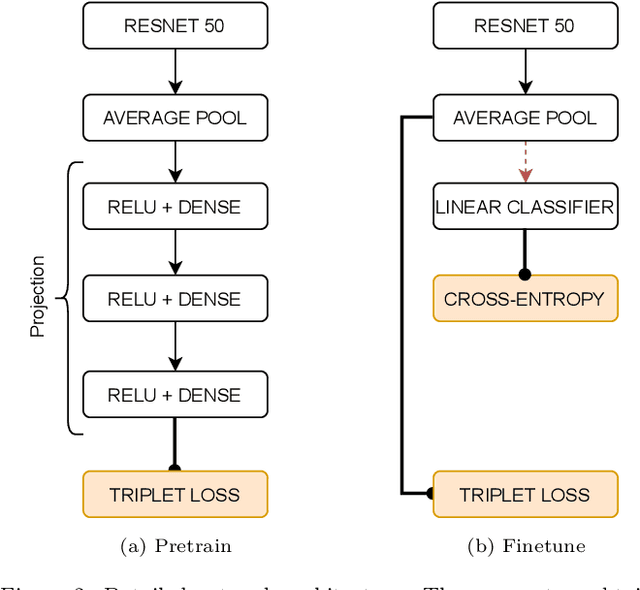
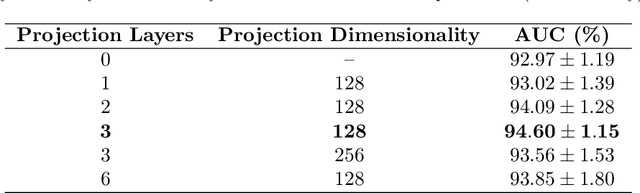
WCE Polyp Detection with Triplet based Embeddings
Dec 10, 2019


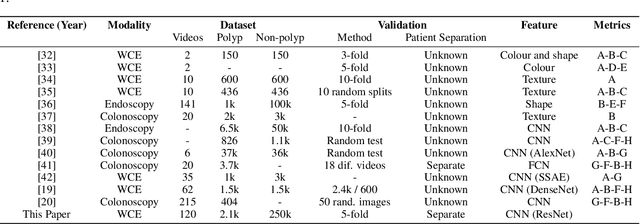
Wireless capsule endoscopy is a medical procedure used to visualize the entire gastrointestinal tract and to diagnose intestinal conditions, such as polyps or bleeding. Current analyses are performed by manually inspecting nearly each one of the frames of the video, a tedious and error-prone task. Automatic image analysis methods can be used to reduce the time needed for physicians to evaluate a capsule endoscopy video, however these methods are still in a research phase. In this paper we focus on computer-aided polyp detection in capsule endoscopy images. This is a challenging problem because of the diversity of polyp appearance, the imbalanced dataset structure and the scarcity of data. We have developed a new polyp computer-aided decision system that combines a deep convolutional neural network and metric learning. The key point of the method is the use of the triplet loss function with the aim of improving feature extraction from the images when having small dataset. The triplet loss function allows to train robust detectors by forcing images from the same category to be represented by similar embedding vectors while ensuring that images from different categories are represented by dissimilar vectors. Empirical results show a meaningful increase of AUC values compared to baseline methods. A good performance is not the only requirement when considering the adoption of this technology to clinical practice. Trust and explainability of decisions are as important as performance. With this purpose, we also provide a method to generate visual explanations of the outcome of our polyp detector. These explanations can be used to build a physician's trust in the system and also to convey information about the inner working of the method to the designer for debugging purposes.