 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pre-Training Boosts Semantic Scene Segmentation on LiDAR data
Sep 05, 2023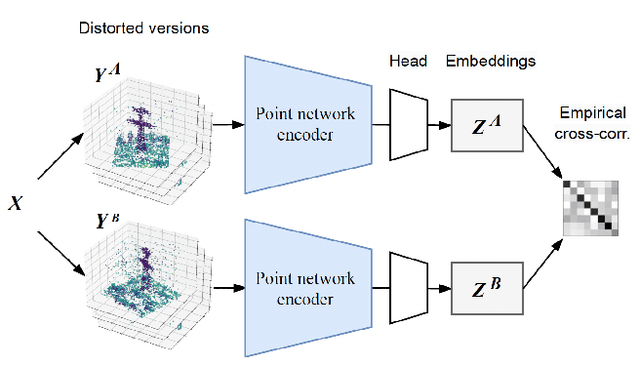


Airborne LiDAR systems have the capability to capture the Earth's surface by generating extensive point cloud data comprised of points mainly defined by 3D coordinates. However, labeling such points for supervised learning tasks is time-consuming. As a result, there is a need to investigate techniques that can learn from unlabeled data to significantly reduce the number of annotated samples. In this work, we propose to train a self-supervised encoder with Barlow Twins and use it as a pre-trained network in the task of semantic scene segmentation. The experimental results demonstrate that our unsupervised pre-training boosts performance once fine-tuned on the supervised task, especially for under-represented categories.
Object Segmentation of Cluttered Airborne LiDAR Point Clouds
Oct 28, 2022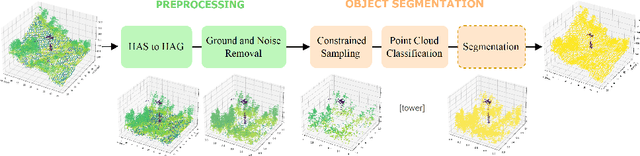
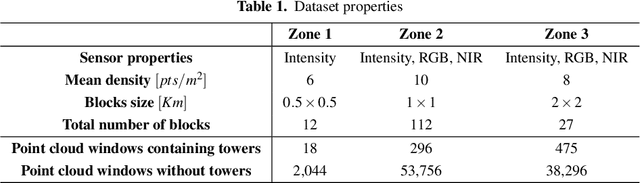

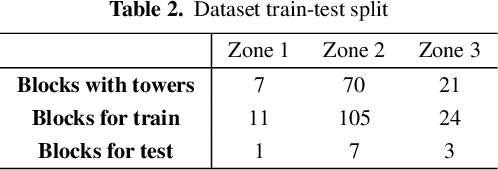
Airborne topographic LiDAR is an active remote sensing technology that emits near-infrared light to map objects on the Earth's surface. Derived products of LiDAR are suitable to service a wide range of applications because of their rich three-dimensional spatial information and their capacity to obtain multiple returns. However, processing point cloud data still requires a significant effort in manual editing. Certain human-made objects are difficult to detect because of their variety of shapes, irregularly-distributed point clouds, and low number of class samples. In this work, we propose an end-to-end deep learning framework to automatize the detection and segmentation of objects defined by an arbitrary number of LiDAR points surrounded by clutter. Our method is based on a light version of PointNet that achieves good performance on both object recognition and segmentation tasks. The results are tested against manually delineated power transmission towers and show promising accuracy.
* proceedings of the 24th International Conference of the Catalan Association for Artificial Intelligence (CCIA 2022)