 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pre-Training Boosts Semantic Scene Segmentation on LiDAR data
Sep 05, 2023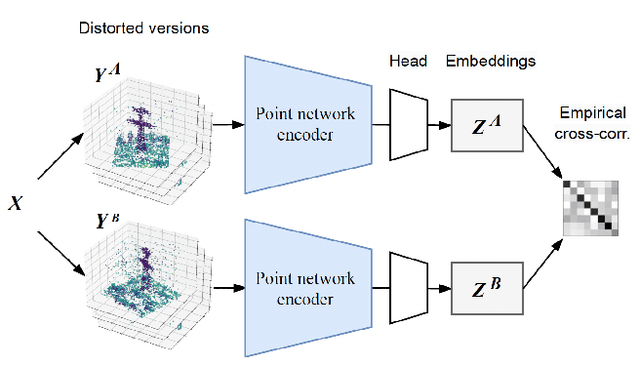


Airborne LiDAR systems have the capability to capture the Earth's surface by generating extensive point cloud data comprised of points mainly defined by 3D coordinates. However, labeling such points for supervised learning tasks is time-consuming. As a result, there is a need to investigate techniques that can learn from unlabeled data to significantly reduce the number of annotated samples. In this work, we propose to train a self-supervised encoder with Barlow Twins and use it as a pre-trained network in the task of semantic scene segmentation. The experimental results demonstrate that our unsupervised pre-training boosts performance once fine-tuned on the supervised task, especially for under-represented categories.
Time-based Self-supervised Learning for Wireless Capsule Endoscopy
Apr 20, 2022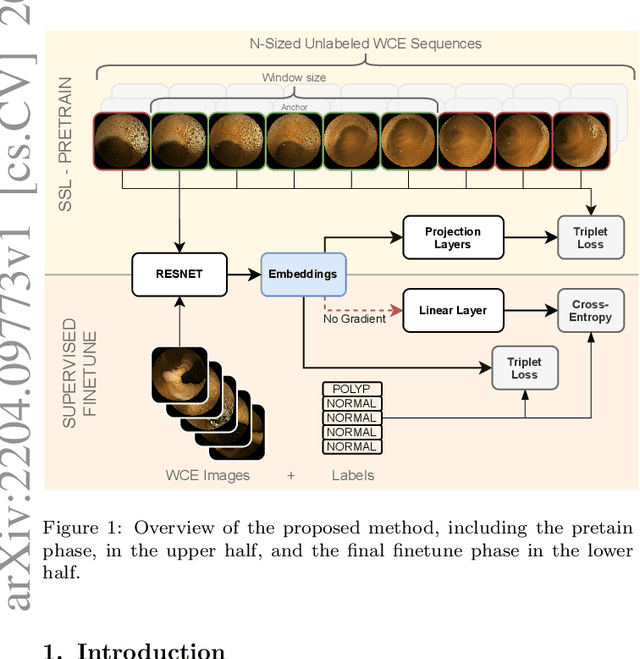
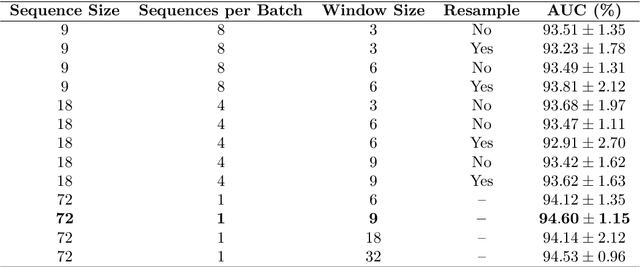
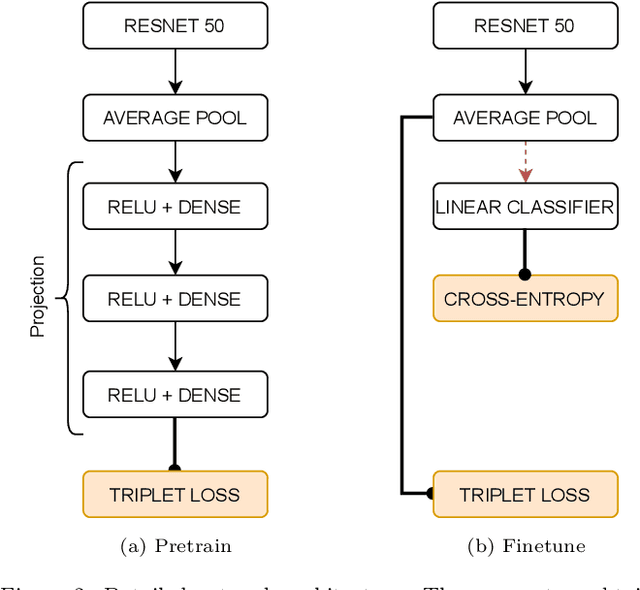
State-of-the-art machine learning models, and especially deep learning ones, are significantly data-hungry; they require vast amounts of manually labeled samples to function correctly. However, in most medical imaging fields, obtaining said data can be challenging. Not only the volume of data is a problem, but also the imbalances within its classes; it is common to have many more images of healthy patients than of those with pathology. Computer-aided diagnostic systems suffer from these issues, usually over-designing their models to perform accurately. This work proposes using self-supervised learning for wireless endoscopy videos by introducing a custom-tailored method that does not initially need labels or appropriate balance. We prove that using the inferred inherent structure learned by our method, extracted from the temporal axis, improves the detection rate on several domain-specific applications even under severe imbalance.
WCE Polyp Detection with Triplet based Embeddings
Dec 10, 2019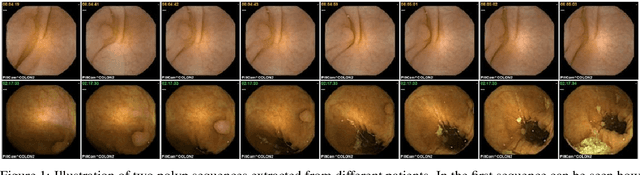


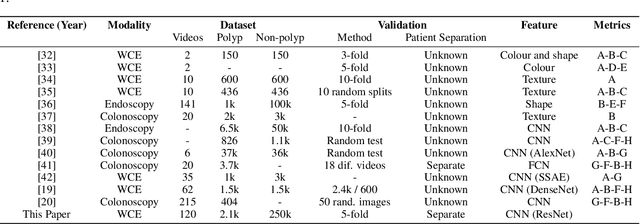
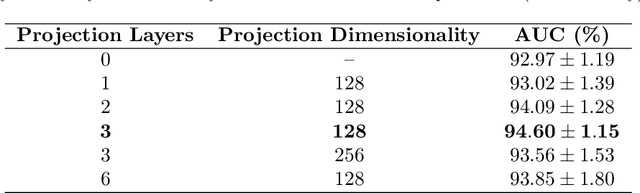
Wireless capsule endoscopy is a medical procedure used to visualize the entire gastrointestinal tract and to diagnose intestinal conditions, such as polyps or bleeding. Current analyses are performed by manually inspecting nearly each one of the frames of the video, a tedious and error-prone task. Automatic image analysis methods can be used to reduce the time needed for physicians to evaluate a capsule endoscopy video, however these methods are still in a research phase. In this paper we focus on computer-aided polyp detection in capsule endoscopy images. This is a challenging problem because of the diversity of polyp appearance, the imbalanced dataset structure and the scarcity of data. We have developed a new polyp computer-aided decision system that combines a deep convolutional neural network and metric learning. The key point of the method is the use of the triplet loss function with the aim of improving feature extraction from the images when having small dataset. The triplet loss function allows to train robust detectors by forcing images from the same category to be represented by similar embedding vectors while ensuring that images from different categories are represented by dissimilar vectors. Empirical results show a meaningful increase of AUC values compared to baseline methods. A good performance is not the only requirement when considering the adoption of this technology to clinical practice. Trust and explainability of decisions are as important as performance. With this purpose, we also provide a method to generate visual explanations of the outcome of our polyp detector. These explanations can be used to build a physician's trust in the system and also to convey information about the inner working of the method to the designer for debugging purposes.
Uncertainty Gated Network for Land Cover Segmentation
May 29, 2018

The production of thematic maps depicting land cover is one of the most common applications of remote sensing. To this end, several semantic segmentation approaches, based on deep learning, have been proposed in the literature, but land cover segmentation is still considered an open problem due to some specific problems related to remote sensing imaging. In this paper we propose a novel approach to deal with the problem of modelling multiscale contexts surrounding pixels of different land cover categories. The approach leverages the computation of a heteroscedastic measure of uncertainty when classifying individual pixels in an image. This classification uncertainty measure is used to define a set of memory gates between layers that allow a principled method to select the optimal decision for each pixel.
Generic Feature Learning for Wireless Capsule Endoscopy Analysis
Jul 26, 2016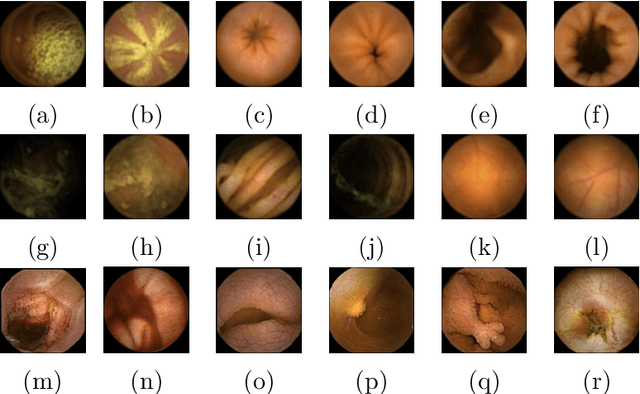
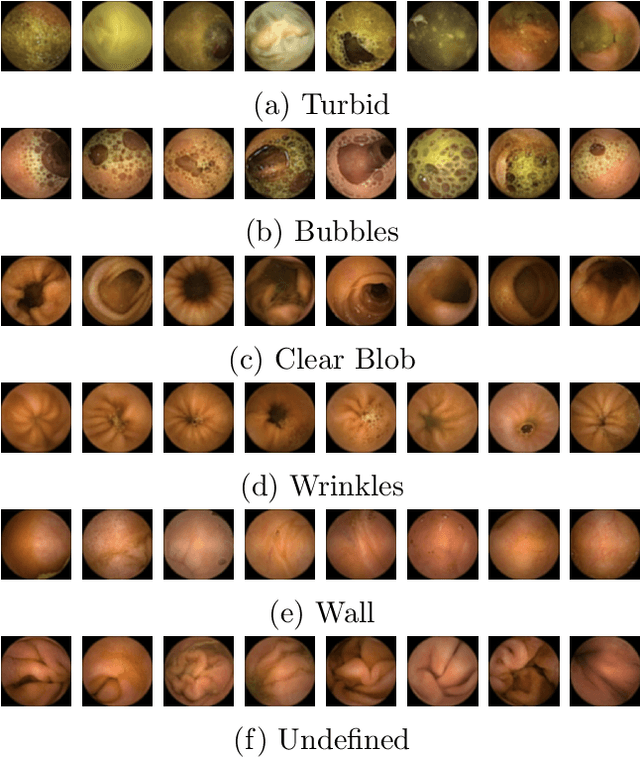

The interpretation and analysis of the wireless capsule endoscopy recording is a complex task which requires sophisticated computer aided decision (CAD) systems in order to help physicians with the video screening and, finally, with the diagnosis. Most of the CAD systems in the capsule endoscopy share a common system design, but use very different image and video representations. As a result, each time a new clinical application of WCE appears, new CAD system has to be designed from scratch. This characteristic makes the design of new CAD systems a very time consuming. Therefore, in this paper we introduce a system for small intestine motility characterization, based on Deep Convolutional Neural Networks, which avoids the laborious step of designing specific features for individual motility events. Experimental results show the superiority of the learned features over alternative classifiers constructed by using state of the art hand-crafted features. In particular, it reaches a mean classification accuracy of 96% for six intestinal motility events, outperforming the other classifiers by a large margin (a 14% relative performance increase).
Learning to count with deep object features
May 29, 2015
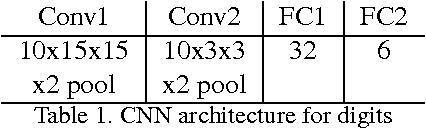


Learning to count is a learning strategy that has been recently proposed in the literature for dealing with problems where estimating the number of object instances in a scene is the final objective. In this framework, the task of learning to detect and localize individual object instances is seen as a harder task that can be evaded by casting the problem as that of computing a regression value from hand-crafted image features. In this paper we explore the features that are learned when training a counting convolutional neural network in order to understand their underlying representation. To this end we define a counting problem for MNIST data and show that the internal representation of the network is able to classify digits in spite of the fact that no direct supervision was provided for them during training. We also present preliminary results about a deep network that is able to count the number of pedestrians in a scene.