 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Formalization of a Trustworthy AI for Mining Interpretable Models explOiting Sophisticated Algorithms
Oct 23, 2025Interpretable-by-design models are crucial for fostering trust, accountability, and safe adoption of automated decision-making models in real-world applications. In this paper we formalize the ground for the MIMOSA (Mining Interpretable Models explOiting Sophisticated Algorithms) framework, a comprehensive methodology for generating predictive models that balance interpretability with performance while embedding key ethical properties. We formally define here the supervised learning setting across diverse decision-making tasks and data types, including tabular data, time series, images, text, transactions, and trajectories. We characterize three major families of interpretable models: feature importance, rule, and instance based models. For each family, we analyze their interpretability dimensions, reasoning mechanisms, and complexity. Beyond interpretability, we formalize three critical ethical properties, namely causality, fairness, and privacy, providing formal definitions, evaluation metrics, and verification procedures for each. We then examine the inherent trade-offs between these properties and discuss how privacy requirements, fairness constraints, and causal reasoning can be embedded within interpretable pipelines. By evaluating ethical measures during model generation, this framework establishes the theoretical foundations for developing AI systems that are not only accurate and interpretable but also fair, privacy-preserving, and causally aware, i.e., trustworthy.
A Practical Approach to Causal Inference over Time
Oct 14, 2024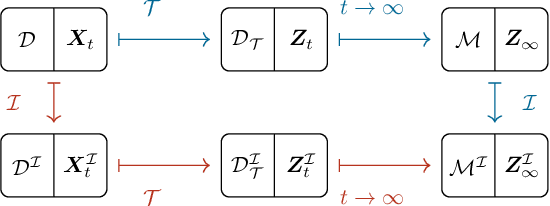
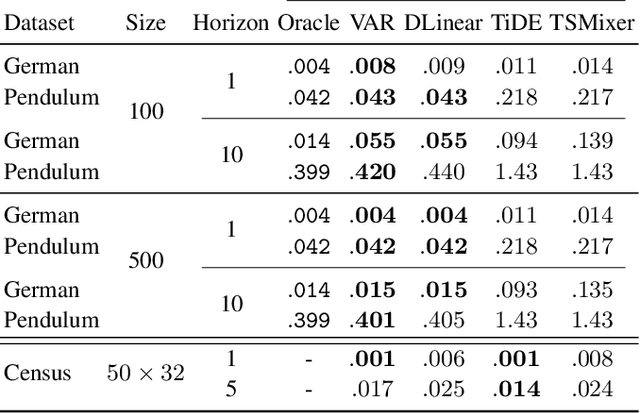
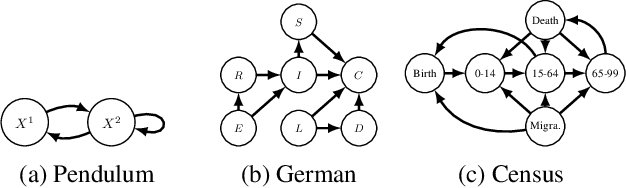
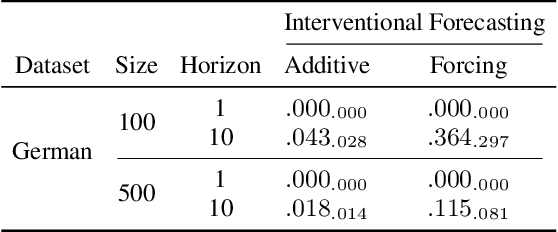
In this paper, we focus on estimating the causal effect of an intervention over time on a dynamical system. To that end, we formally define causal interventions and their effects over time on discrete-time stochastic processes (DSPs). Then, we show under which conditions the equilibrium states of a DSP, both before and after a causal intervention, can be captured by a structural causal model (SCM). With such an equivalence at hand, we provide an explicit mapping from vector autoregressive models (VARs), broadly applied in econometrics, to linear, but potentially cyclic and/or affected by unmeasured confounders, SCMs. The resulting causal VAR framework allows us to perform causal inference over time from observational time series data. Our experiments on synthetic and real-world datasets show that the proposed framework achieves strong performance in terms of observational forecasting while enabling accurate estimation of the causal effect of interventions on dynamical systems. We demonstrate, through a case study, the potential practical questions that can be addressed using the proposed causal VAR framework.
Constraint-Free Structure Learning with Smooth Acyclic Orientations
Sep 15, 2023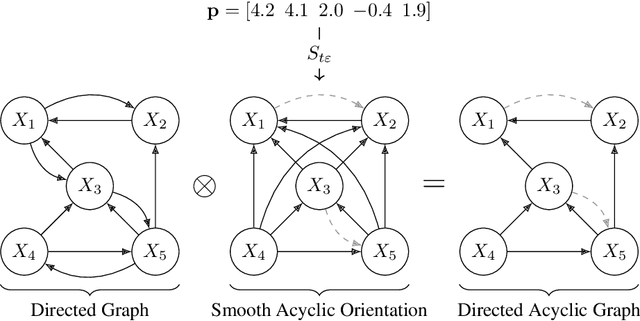
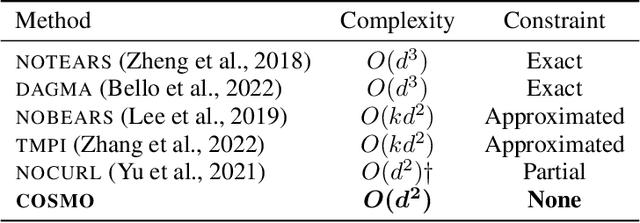
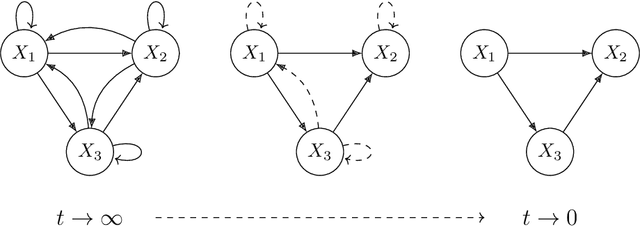
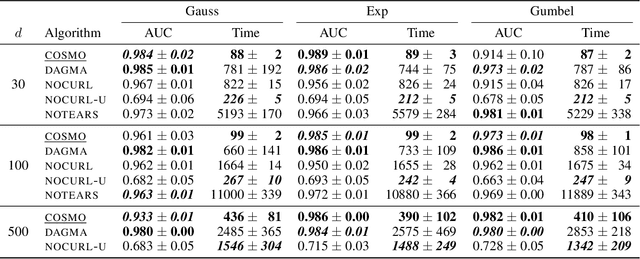
The structure learning problem consists of fitting data generated by a Directed Acyclic Graph (DAG) to correctly reconstruct its arcs. In this context, differentiable approaches constrain or regularize the optimization problem using a continuous relaxation of the acyclicity property. The computational cost of evaluating graph acyclicity is cubic on the number of nodes and significantly affects scalability. In this paper we introduce COSMO, a constraint-free continuous optimization scheme for acyclic structure learning. At the core of our method, we define a differentiable approximation of an orientation matrix parameterized by a single priority vector. Differently from previous work, our parameterization fits a smooth orientation matrix and the resulting acyclic adjacency matrix without evaluating acyclicity at any step. Despite the absence of explicit constraints, we prove that COSMO always converges to an acyclic solution. In addition to being asymptotically faster, our empirical analysis highlights how COSMO performance on graph reconstruction compares favorably with competing structure learning methods.
The Importance of Time in Causal Algorithmic Recourse
Jun 08, 2023The application of Algorithmic Recourse in decision-making is a promising field that offers practical solutions to reverse unfavorable decisions. However, the inability of these methods to consider potential dependencies among variables poses a significant challenge due to the assumption of feature independence. Recent advancements have incorporated knowledge of causal dependencies, thereby enhancing the quality of the recommended recourse actions. Despite these improvements, the inability to incorporate the temporal dimension remains a significant limitation of these approaches. This is particularly problematic as identifying and addressing the root causes of undesired outcomes requires understanding time-dependent relationships between variables. In this work, we motivate the need to integrate the temporal dimension into causal algorithmic recourse methods to enhance recommendations' plausibility and reliability. The experimental evaluation highlights the significance of the role of time in this field.
Boosting Synthetic Data Generation with Effective Nonlinear Causal Discovery
Jan 18, 2023



Synthetic data generation has been widely adopted in software testing, data privacy, imbalanced learning, and artificial intelligence explanation. In all such contexts, it is crucial to generate plausible data samples. A common assumption of approaches widely used for data generation is the independence of the features. However, typically, the variables of a dataset depend on one another, and these dependencies are not considered in data generation leading to the creation of implausible records. The main problem is that dependencies among variables are typically unknown. In this paper, we design a synthetic dataset generator for tabular data that can discover nonlinear causalities among the variables and use them at generation time. State-of-the-art methods for nonlinear causal discovery are typically inefficient. We boost them by restricting the causal discovery among the features appearing in the frequent patterns efficiently retrieved by a pattern mining algorithm. We design a framework for generating synthetic datasets with known causalities to validate our proposal. Broad experimentation on many synthetic and real datasets with known causalities shows the effectiveness of the proposed method.
CALIME: Causality-Aware Local Interpretable Model-Agnostic Explanations
Dec 10, 2022A significant drawback of eXplainable Artificial Intelligence (XAI) approaches is the assumption of feature independence. This paper focuses on integrating causal knowledge in XAI methods to increase trust and help users assess explanations' quality. We propose a novel extension to a widely used local and model-agnostic explainer that explicitly encodes causal relationships in the data generated around the input instance to explain. Extensive experiments show that our method achieves superior performance comparing the initial one for both the fidelity in mimicking the black-box and the stability of the explanations.